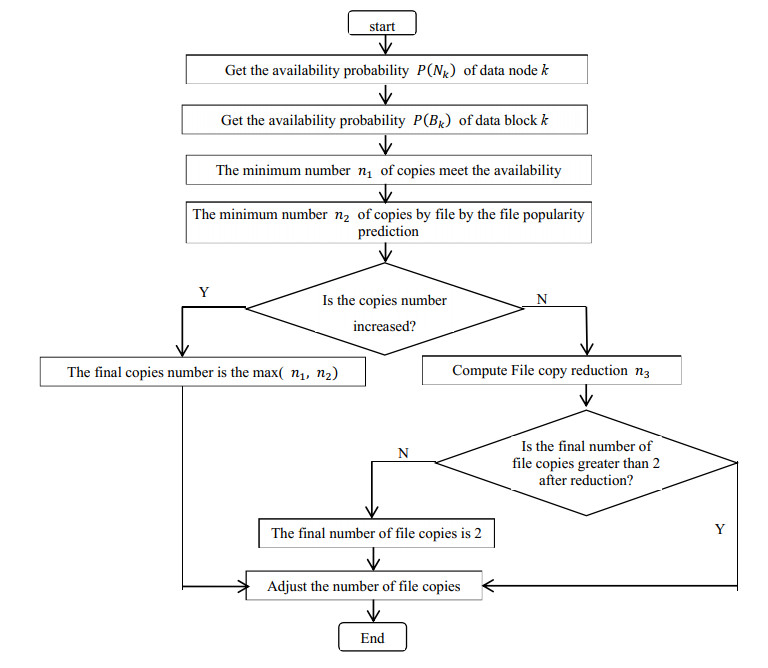
HDFS heterogeneous clusters usually have multiple storage media at the same time. How to efficiently read and write file copies and reasonably use various storage media is a problem to be solved. Dynamically adjusting the number of copies is important in HDFS, which can solve the problem of accessing a large number of hot files at the same time and improve the efficiency of cluster services. A method is introduced to calculate the number of dynamic HDFS copies based on file access popularity in this paper. Firstly, an algorithm was proposed to predict file popularity based on the cuckoo search optimization Markov model. The unbiased grey model is used to predict the accessing file's popularity at the next moment according to the recent access of the file. The cuckoo search is used to optimize the Markov model, and the prediction error is corrected. Then, the calculation method of the number of copies is designed based on the prediction of the popularity of the file to be accessed and the availability of the node. The experiment shows that the proposed method has a high fitting degree with the actual value, and the MAPE is 3.08%, and it is the smallest, compared with several commonly used prediction models. In CloudSim4.0 simulation platform, multiple users write 10 files to the cluster at the same time, and the change number of copies is calculated according to the predicted value at the next moment, so as to improve the user access efficiency.
Citation: Xi-yue Cao, Chao Wang, Biao Wang, Zhen-xue He. A method to calculate the number of dynamic HDFS copies based on file access popularity[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12212-12231. doi: 10.3934/mbe.2022568
HDFS heterogeneous clusters usually have multiple storage media at the same time. How to efficiently read and write file copies and reasonably use various storage media is a problem to be solved. Dynamically adjusting the number of copies is important in HDFS, which can solve the problem of accessing a large number of hot files at the same time and improve the efficiency of cluster services. A method is introduced to calculate the number of dynamic HDFS copies based on file access popularity in this paper. Firstly, an algorithm was proposed to predict file popularity based on the cuckoo search optimization Markov model. The unbiased grey model is used to predict the accessing file's popularity at the next moment according to the recent access of the file. The cuckoo search is used to optimize the Markov model, and the prediction error is corrected. Then, the calculation method of the number of copies is designed based on the prediction of the popularity of the file to be accessed and the availability of the node. The experiment shows that the proposed method has a high fitting degree with the actual value, and the MAPE is 3.08%, and it is the smallest, compared with several commonly used prediction models. In CloudSim4.0 simulation platform, multiple users write 10 files to the cluster at the same time, and the change number of copies is calculated according to the predicted value at the next moment, so as to improve the user access efficiency.

| [1] | C. L. Abad, Y. Lu, R. H. Campbell, DARE: Adaptive data replication for efficient cluster schedule, in 2011 IEEE International Conference on Cluster Computing, (2011), 159–168. https://doi.org/10.1109/CLUSTER.2011.26 |
| [2] |
M. Meddeb, A. Dhraief, A. Belghith, T. Monteil, K. Drira, H. Mathkour, Least fresh first cache replacement policy for NDN-based IoT networks, Pervasive Mobile Comput., 52 (2019), 60–70. https://doi.org/10.1016/j.pmcj.2018.12.002 doi: 10.1016/j.pmcj.2018.12.002

|
| [3] |
H. Wu, H. Lu, F. Wu, C. W. Chen, Energy and delay optimization for cache-enabled dense small cell networks, IEEE Trans. Veh. Technol., 69 (2020), 7663–7678. https://doi.org/10.1109/TVT.2020.2989033 doi: 10.1109/TVT.2020.2989033
|
| [4] | Q. Li, X. Zheng, Research survey of cloud computing, Comput. Sci., 38 (2011), 32–37. |
| [5] | S. P. Menon, N. P. Hegde, A survey of tools and applications in big data, in 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), (2015), 1–7. https://doi.org/10.1109/ISCO.2015.7282364 |
| [6] | Y. Taleb, S. Ibrahim, G. Antoniu, T. Cortes, Characterizing performance and energy-efficiency of the ramcloud storage system, in 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), 1488–1498. https://doi.org/10.1109/ICDCS.2017.51 |
| [7] | L. Rao, F. Yang, X. M. Li, Dynamic replica creation algorithm based on temperature's analysis, J. Comput. Appl., 34 (2014), 130–134. |
| [8] |
H. Wu, H. Lu, F. Wu, C. W. Chen, Energy and delay optimization for cache-enabled dense small cell networks, IEEE Trans. Veh. Technol., 69 (2020), 7663–7678. https://doi.org/10.1109/TVT.2020.2989033 doi: 10.1109/TVT.2020.2989033
|
| [9] |
A. M. Daniel, W. Yu, Optimization of heterogeneous coded caching, IEEE Trans. Inf. Theory, 66 (2020), 1893–1919. https://doi.org/10.1109/TIT.2019.2962495 doi: 10.1109/TIT.2019.2962495
|
| [10] | L. Shi, M. Y. Guo, L. Liu, Y. L. Shen, L. Xu, Feedback mechanism based prediction method of dynamic replicas number, J. Syst. Simul., 23 (2011), 193–199. |
| [11] |
X. Xu, C. Yang, J. Shao, Data replica placement mechanism for open heterogeneous storage systems, Procedia Comput. Sci., 109 (2017), 18–25. https://doi.org/10.1016/j.procs.2017.05.290 doi: 10.1016/j.procs.2017.05.290
|
| [12] | Z. J. Cheng, L. Wang, Y. D. Cheng, G. Chen, Q. B. Hu, H. B. Li, File access heat prediction for high energy physical hierarchical storage, Comput. Eng., 47 (2021), 7. |
| [13] | Y. Qin, Reserch on HDFS Replica Placement Management Policy and Retrieval Algorithm in Heterogeneous Storage Environment, Ph.D thesis, University of Electronic Science and Technology of China, 2020. |
| [14] | Q. Wei, B. Veeravalli, B. Gong, L. Zeng, D. Feng, CDRM: A cost-effective dynamic replication management scheme for cloud storage cluster, in 2010 IEEE International Conference on Cluster Computing, (2010), 188–196. https://doi.org/10.1109/CLUSTER.2010.24 |
| [15] |
A. Higai, A. Takefusa, H. Nakada, M. Oguchi, A study of effective replica reconstruction schemes for the hadoop distributed file system, IEICE Trans. Inf. Syst., 98 (2015), 872–882. https://doi.org/10.1587/transinf.2014EDP7242 doi: 10.1587/transinf.2014EDP7242
|
| [16] | L. F. Chen, D. B. Hoang, Adaptive data replicas management based on active data-centric framework in Cloud Environment, in 2013 IEEE 10th International Conference on Highperformance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, (2013), 101–108. https://doi.org/10.1109/HPCC.and.EUC.2013.24 |
| [17] | S. Zhang, D. U. Qing-Wei, J. Sun, Z. Sun, Dynamic replicas strategy based on predicted popularity, Comput. Modernization, 2015 (2015). |
| [18] | L. L. Xu, H. Li, J. Li, Research on population prediction based on grey prediction and radial basis function network, Comput. Sci., 46 (2019), 431–435. |
| [19] |
Y. S. Lee, L. I. Tong, Forecasting energy consumption using a grey model improved by incorporating genetic programming, Energy Convers. Manage., 52 (2011), 147–152. https://doi.org/10.1016/j.enconman.2010.06.053 doi: 10.1016/j.enconman.2010.06.053
|
| [20] | X. S. Yang, S. Deb, Cuckoo search via Lévy flights, in 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), (2009), 210–214.https://doi.org/10.1109/NABIC.2009.5393690 |
| [21] |
D. Chitara, K. R. Niazi, A. Swarnkar, N. Gupta, Cuckoo search optimization algorithm for designing of a multimachine power system stabilizer, IEEE Trans. Ind. Appl., 54 (2018) 3056–3065. https://doi.org/10.1109/TIA.2018.2811725 doi: 10.1109/TIA.2018.2811725
|
| [22] | X. C. Huang, J. W. Yin, HDFS load balancer for video cloud storage service, J. Chin. Comput. Syst., 38 (2017), 293–298. |



Figures(4) / Tables(10)

Xi-yue Cao, Chao Wang, Biao Wang, Zhen-xue He. A method to calculate the number of dynamic HDFS copies based on file access popularity[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12212-12231. doi: 10.3934/mbe.2022568







 DownLoad:
DownLoad: