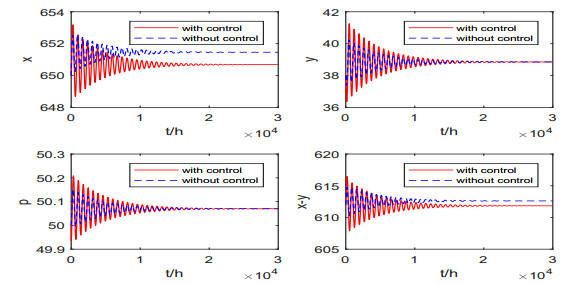
In this paper, a single-species fishery economic model with two time delays is investigated. The system is shown to be locally stable around the interior equilibrium when the parameters are in a specific range, and the Hopf bifurcation is shown occur as the time delays cross the critical values. Then the direction of Hopf bifurcation and the stability of bifurcated periodic solutions are discussed. In addition, the optimal cost strategy is obtained to maximize the net profit and minimize the waste by hoarding for speculation. We also design controls to minimize the waste by hoarding for the speculation of the system with time delays. The existence of the optimal controls and derivation from the optimality conditions are discussed. The validity of the theoretical results are shown via numerical simulation.
Citation: Xin Gao, Yue Zhang. Bifurcation analysis and optimal control of a delayed single-species fishery economic model[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 8081-8106. doi: 10.3934/mbe.2022378
In this paper, a single-species fishery economic model with two time delays is investigated. The system is shown to be locally stable around the interior equilibrium when the parameters are in a specific range, and the Hopf bifurcation is shown occur as the time delays cross the critical values. Then the direction of Hopf bifurcation and the stability of bifurcated periodic solutions are discussed. In addition, the optimal cost strategy is obtained to maximize the net profit and minimize the waste by hoarding for speculation. We also design controls to minimize the waste by hoarding for the speculation of the system with time delays. The existence of the optimal controls and derivation from the optimality conditions are discussed. The validity of the theoretical results are shown via numerical simulation.

| [1] | C. Clark, Mathematical Bioeconomics: The Optimal Management of Renewable Resources, John Wiley & Sons, New York, 1990. https://doi.org/10.1137/1020117 |
| [2] |
M. Liu, C. Bai, Optimal harvesting of a stochastic Logistic model with time delay, J. Nonlinear Sci., 25 (2015), 277–289. https://doi.org/10.1007/s00332-014-9229-2 doi: 10.1007/s00332-014-9229-2

|
| [3] |
M. Jerry, N. Raïssi, The optimal strategy for a bioeconomical model of a harvesting renewable resource problem, Math. Comput. Model., 36 (2002), 1293–1306. https://doi.org/10.1016/S0895-7177(02)00277-7 doi: 10.1016/S0895-7177(02)00277-7
|
| [4] |
J. M. Conrad, The bioeconomics of marine sanctuaries, J. Bioeconomics, 1 (1999), 205–217. https://doi.org/10.1023/A:1010039031324 doi: 10.1023/A:1010039031324
|
| [5] |
D. Ami, P. Cartigny, A. Rapaport, Can marine protected areas enhance both economic and biological situations?, C. R. Biol., 328 (2005), 357–366. https://doi.org/10.1016/j.crvi.2004.10.018 doi: 10.1016/j.crvi.2004.10.018
|
| [6] |
N. Bairagi, S. Bhattacharya, P. Auger, Bioeconomics fishery model in presence of infection: Sustainability and demand-price perspectives, Appl. Math. Comput., 405 (2021), 126225. https://doi.org/10.1016/j.amc.2021.126225 doi: 10.1016/j.amc.2021.126225
|
| [7] |
C. Jerry, N. Raïssi, Can management measures ensure the biological and economical stabilizability of a fishing model?, Appl. Math. Comput., 51 (2010), 516–526. https://doi.org/10.1016/j.mcm.2009.11.017 doi: 10.1016/j.mcm.2009.11.017
|
| [8] |
J. T. Lafrance, Linear demand functions in theory and practice, J. Econ. Theory, 37 (1985), 147–166. https://doi.org/10.1016/0022-0531(85)90034-1 doi: 10.1016/0022-0531(85)90034-1
|
| [9] |
K. Chakraborty, M. Chakraborty, T. K. Kar, Bifurcation and control of a bioeconomic model of a prey Cpredator system with a time delay, Nonlinear Anal. Hybrid Syst., 5 (2011), 613–625. https://doi.org/10.1016/j.nahs.2011.05.004 doi: 10.1016/j.nahs.2011.05.004
|
| [10] |
Y. Song, Y. Peng, J. Wei, Bifurcations for a predator-prey system with two delays, J. Math. Anal. Appl., 337 (2008), 466–479. https://doi.org/10.1016/j.jmaa.2007.04.001 doi: 10.1016/j.jmaa.2007.04.001
|
| [11] |
W. Liu, Y. Jiang, Bifurcation of a delayed Gause predator-prey model with Michaelis-Menten type harvesting, J. Theor. Biol., 438 (2018), 116–132. https://doi.org/10.1016/j.jtbi.2017.11.007 doi: 10.1016/j.jtbi.2017.11.007
|
| [12] |
X. Zhang, S. Song, J. Wu, Oscillations, fluctuation intensity and optimal harvesting of a bio-economic model in a complex habitat, J. Math. Anal. Appl., 436 (2016), 692–717. https://doi.org/10.1016/j.jmaa.2015.11.068 doi: 10.1016/j.jmaa.2015.11.068
|
| [13] |
S. Ruan, J. Wei, On the zeros of transcendental functions with applications to stability of delay differential equations with two delays, Dyn. Contin. Discrete Impuls. Syst., 10 (2003), 863–874. https://doi.org/10.1093/imammb/18.1.41 doi: 10.1093/imammb/18.1.41
|
| [14] | K. Yang, Delay Differential Equations: With Applications in Population Dynamics, American Academic Press, New York, 1993. |
| [15] |
H. I. Freedman, V. Sree Hari Rao, The trade-off between mutual interference and time lags in predator-prey systems, B. Math. Biol., 45 (1983), 991–1004. https://doi.org/10.1016/S0092-8240(83)80073-1 doi: 10.1016/S0092-8240(83)80073-1
|
| [16] | B. Hassard, N. Kazarinoff, Y. Wan, Theory and Applications of Hopf Bifurcation, Cambridge University Press, Cambridge, 1981. https://doi.org/10.1137/1024123 |
| [17] | L. D. Berkovitz, Optimal Control Theory, Springer-Verlag, Berlin, 1974. https://doi.org/10.1002/9783527639700.ch5 |
| [18] |
A. E. Bryson, Y. C. Ho, G. M. Siouris, Applied optimal control: optimization, estimation, and control, IEEE T. Syst. Man Cybernetics. B, 9 (1979), 366–367. https://doi.org/10.1109/TSMC.1979.4310229 doi: 10.1109/TSMC.1979.4310229
|
| [19] |
K. A. Gepreel, M. Higazy, A. M. S. Mahdy, Optimal control, signal flow graph, and system electronic circuit realization for nonlinear Anopheles mosquito model, Int. J. Mod. Phys. C, 31 (2020), 2050130. https://doi.org/10.1142/S0129183120501302 doi: 10.1142/S0129183120501302
|
| [20] | J. Borek, B. Groelke, C. Earnhardt, C. Vermillion, Economic optimal control for minimizing fuel consumption of Heavy-Duty trucks in a highway environment, IEEE Trans. Control Syst. Technol., 99 (2019), 1–13. https://ieeexplore.ieee.org/document/8737780 |
| [21] |
F. A. Rihan, S. Lakshmanan, H. Maurer, Optimal control of tumour-immune model with time-delay and immuno-chemotherapy, Appl. Math. Comput., 353 (2019), 147–165. https://doi.org/10.1016/j.amc.2019.02.002 doi: 10.1016/j.amc.2019.02.002
|
| [22] | W. Kaplan, Ordinary Differential Equations, Addison-Wesley Publishing Company, 1958. |
| [23] | O. Hölder, Ueber einen Mittelwerthabsatz, Digi Zeitschriften, (1889). |
| [24] | Z. Peng, M. Huang, J. Qiao, Effects of breeding density and salinity on growth traits of penaeus vannamei during sizing, Fish. Sci. Technol. Inf., 46 (2019), 154–159. |
| [25] | J. Li, J. Shi, X. Hu, Statistical analysis of Penaeus vannamei strains, density, seedling release time and breeding benefit, J. Aquacult., 40 (2019), 19–24. |
| [26] |
Y. Fu, L. Mai, X. Zhong, 2016 national report on breeding and fishing of penaeus vannamei, Ocean Fish., 8 (2016), 68–71. https://doi.org/10.3969/j.issn.1672-4046.2016.08.038 doi: 10.3969/j.issn.1672-4046.2016.08.038
|
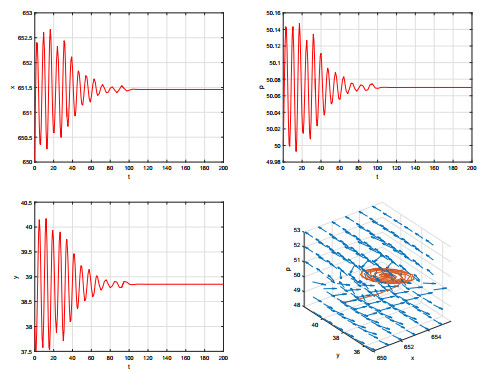
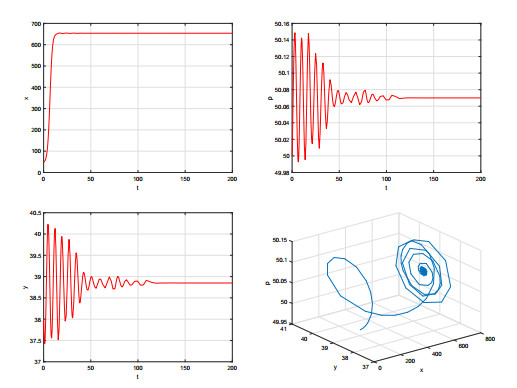
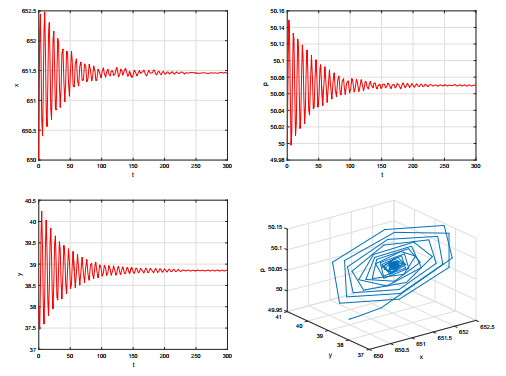
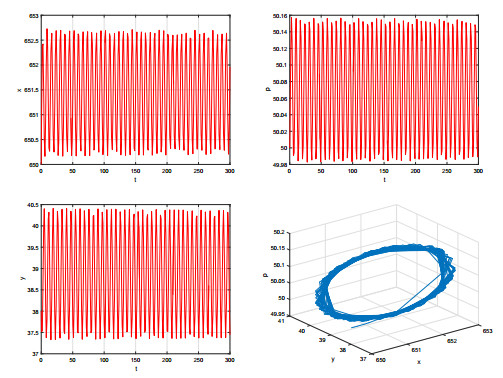
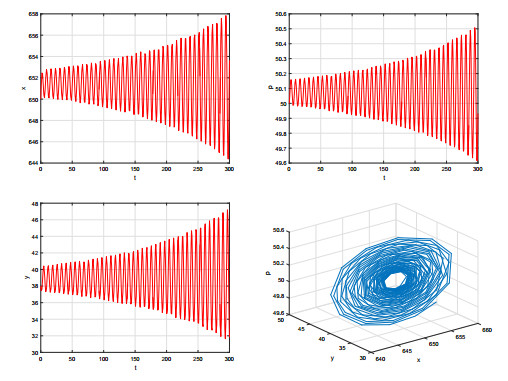
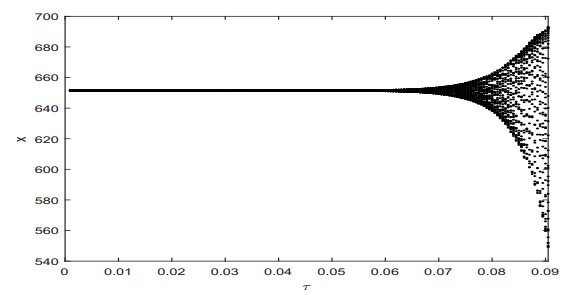
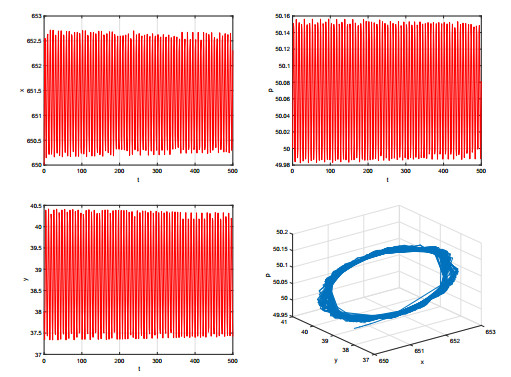
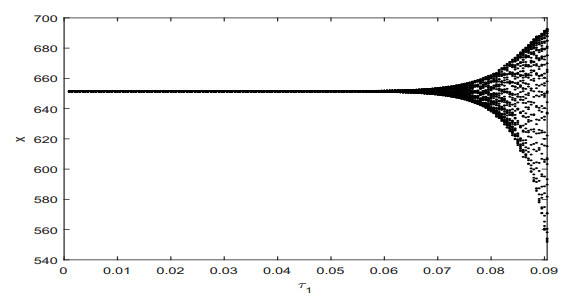
Figures(9)

Xin Gao, Yue Zhang. Bifurcation analysis and optimal control of a delayed single-species fishery economic model[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 8081-8106. doi: 10.3934/mbe.2022378







 DownLoad:
DownLoad: