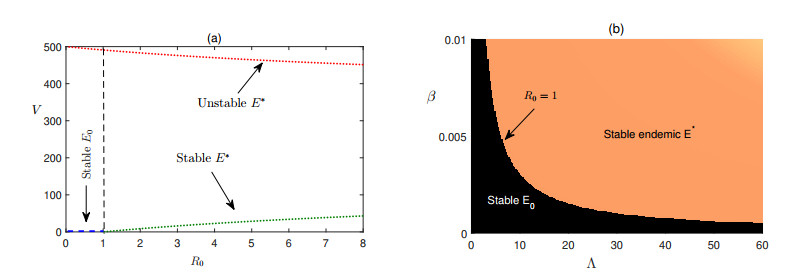
In this article, we have presented a mathematical model to study the dynamics of hepatitis C virus (HCV) disease considering three populations namely the uninfected liver cells, infected liver cells, and HCV with the aim to control the disease. The model possesses two equilibria namely the disease-free steady state and the endemically infected state. There exists a threshold condition (basic reproduction number) that determines the stability of the disease-free equilibrium and the number of the endemic states. We have further introduced impulsive periodic therapy using DAA into the system and studied the efficacy of the DAA therapy for hepatitis C infected patients in terms of a threshold condition. Finally, impulse periodic dosing with varied rate and time interval is adopted for cost effective disease control for finding the proper dose and dosing interval for the control of HCV disease.
Citation: Amar Nath Chatterjee, Fahad Al Basir, Yasuhiro Takeuchi. Effect of DAA therapy in hepatitis C treatment — an impulsive control approach[J]. Mathematical Biosciences and Engineering, 2021, 18(2): 1450-1464. doi: 10.3934/mbe.2021075
In this article, we have presented a mathematical model to study the dynamics of hepatitis C virus (HCV) disease considering three populations namely the uninfected liver cells, infected liver cells, and HCV with the aim to control the disease. The model possesses two equilibria namely the disease-free steady state and the endemically infected state. There exists a threshold condition (basic reproduction number) that determines the stability of the disease-free equilibrium and the number of the endemic states. We have further introduced impulsive periodic therapy using DAA into the system and studied the efficacy of the DAA therapy for hepatitis C infected patients in terms of a threshold condition. Finally, impulse periodic dosing with varied rate and time interval is adopted for cost effective disease control for finding the proper dose and dosing interval for the control of HCV disease.

| [1] | WHO, Hepatitis C, 2020. Available from: https://www.who.int/news-room/fact-sheets/detail/hepatitis-c. |
| [2] | M. J. Alter, HCV routes of transmission: what goes around comes around, In: Seminars in liver disease, 31 (2011), 340–346. |
| [3] |
A. U. Neumann, N. P. Lam, H. Dahari, D. R. Gretch, T. E. Wiley, T. J. Layden, et al., Hepatitis C viral dynamics in vivo and the antiviral efficacy of interferon-a therapy, Science., 282 (1998), 103–107. doi: 10.1126/science.282.5386.103

|
| [4] |
F. Alvarez, P. A. Berg, F. B. Bianchi, International Autoimmune Hepatitis Group Report: review of criteria for diagnosis of autoimmune hepatitis, J. Hepatol., 31 (1999), 929–938. doi: 10.1016/S0168-8278(99)80297-9
|
| [5] | D. Das, M. Pandya, Recent Advancement of Direct-acting Antiviral Agents (DAAs) in Hepatitis C Therapy, Mini Rev. Med. Chem., 18 (2018), 584–596. |
| [6] | T. Asselah, P. Marcellin, Interferon free therapy with direct acting antivirals for HCV, Liver Int., 33 (2013), 93–104. |
| [7] | E. De Clercq, Current race in the development of DAAs (direct-acting antivirals) against HCV, Biochem. Pharmacol., 89 (2014), 441–452. |
| [8] | M. A. Nowak, C. R. M. Bangham, Population dynamics of immune responses to persistent viruses, Science, 272 (1996), 74–79. |
| [9] | S. Bonhoeffer, J. M. Coffin, M. A. Nowak, Human immunodeficiency virus drug therapy and virus load, J. Virol., 71 (1997), 3275–3278. |
| [10] | R. O. Avendan, L. Estevab, J. A. Floresb, J. F. Allen, G. Gomez, J. Lopez-Estrada, A Mathematical Model for the Dynamics of Hepatitis C, J. Theor. Med., 4 (2002), 109–118. |
| [11] | Y. Zhao, Z. Xu, Global Dynamics for Delayed Hepatitis C Virus Infection Model, Electron. J. Differ. Equ., 2014 (2014), 1–18. |
| [12] | A. Chatterjee, J. Guedj, A. S. Perelson, Mathematical modelling of HCV infection: what can it teach us in the era of direct-acting antiviral agents?, Antivir. Ther., 17 (2012), 1171–1182. |
| [13] | H. A. Elkaranshawy, H. M. Ezzat, Y. Abouelseoud, N. N. Ibrahim, Innovative approximate analytical solution for standard model of viral dynamics: hepatitis C with direct-acting agents as an implemented case, Math. Probl. Eng., 2019 (2019). |
| [14] | J. Guedj, A. U. Neumann, Understanding hepatitis C viral dynamics with direct-acting antiviral agents due to the interplay between intracellular replication and cellular infection dynamics, J. Theor. Biol., 267 (2013), 330–340. |
| [15] | A. N. Chatterjee, M. K. Singh, B. Kumar, The effect of immune responses in HCV disease progression, Eng. Math. Lett., 2019 (2019), 1–14. |
| [16] | A. N. Chatterjee, B. Kumar, Cytotoxic T-lymphocyte Vaccination for Hepatitis C: A Mathematical Approach, Stud. Indian Place Names, 40 (2020), 769–779. |
| [17] | D. Echevarria, A. Gutfraind, B. Boodram, M. Major, S. Del Valle, S. J. Cotler, et al., Mathematical modeling of hepatitis C prevalence reduction with antiviral treatment scale-up in persons who inject drugs in metropolitan Chicago, PloS One, 10 (2015), e0135901. |
| [18] | N. Scott, E. McBryde, P. Vickerman, N. K. Martin, J. Stone, H. Drummer, et al., The role of a hepatitis C virus vaccine: modelling the benefits alongside direct-acting antiviral treatments, BMC Med., 13 (2015), p198. |
| [19] | L. Rong, A. S. Perelson, Mathematical analysis of multiscale models for hepatitis C virus dynamics under therapy with direct-acting antiviral agents, Math. Biosci., 245 (2013), 22–30. |
| [20] | S. Zhang, X. Xu, Dynamic analysis and optimal control for a model of hepatitis C with treatment, Commun. Nonlinear Sci. Numer. Simul., 46 (2017), 14–25. |
| [21] | E. Mayanja, L. S. Luboobi, J. Kasozi, R. N. Nsubuga, Mathematical Modelling of HIV-HCV Coinfection Dynamics in Absence of Therapy, Comput. Math. Methods Med., 2020 (2020), 2106570. |
| [22] | S. Drazilova, M. Janicko, L. Skladany, P. Kristian, M. Oltman, M. Szantova, et al., Glucose metabolism changes in patients with chronic hepatitis C treated with direct acting antivirals, Can. J. Gastroenterol. Hepatol., 2018 (2018), 6095097. |
| [23] | H. Dahari, A. Lo, R. M. Ribeiro, A. S. Perelson, Modeling hepatitis C virus dynamics: Liver regeneration and critical drug efficacy, J. Theor. Biol., 247 (2007), 371–381. |
| [24] | N. K. Martin, P. Vickman, M. Hickman, Mathematical modelling of hepatitis C treatment for injecting drug users, J. Theor. Biol., 274 (2011), 58–66. |
| [25] | E. Ahmed, H. A. El-Saka, On fractional order models for Hepatitis C, Nonlinear Biomed. Phys., 4 (2010), 1–3. |
| [26] | D. Bainov, P. Simeonov, Impulsive differential equations: periodic solutions and applications, CRC Press, 66 (1993). |
| [27] | J. Lou, Y. Lou, J. Wu, Threshold virus dynamics with impulsive antiretroviral drug effects, J. Math. Biol., 65 (2012), 623–652. |
| [28] | J. Lou, R. J. Smith, Modelling the effects of adherence to the HIV fusion inhibitor enfuvirtide, J. Theor. Biol., 268 (2011), 1–13. |
| [29] | L. Q. Min, Y. M. Su, Y. Kuang, Mathematical analysis of a basic virus infection model with application to HBV infection, Rocky Mt. J. Math., 38 (2008), 1573–1585. |
| [30] |
S. A. Gourleya, Y. Kuangb, J. D. Nagy, Dynamics of a delay differential equation model of hepatitis B virus infection, J. Biol. Dyn., 2 (2008), 140–153. doi: 10.1080/17513750701769873
|
| [31] | M. Zhao, Y. Wang, L. Chen, Dynamic Analysis of a Predator-Prey (Pest) Model with Disease in Prey and Involving an Impulsive Control Strategy, J. Appl. Math., 2012 (2012), 969425. |
| [32] | H. Yu, S. Zhong, R. P. Agarwal, Mathematics analysis and chaos in an ecological model with an impulsive control strategy, Commun. Nonlinear Sci. Numer. Simul., 16 (2011), 776–786. |
| [33] | V. Lakshmikantham, D. D. Bainov, P. S. Simeonov, Theory of Impulsive Differential Equations, Series in Modern Appl. Math., 6, 1989. |
| [34] |
B. Patricia, Hepatitis C virus and peripheral blood mononuclear cell reservoirs Patricia Baré, World J. Hepatol., 1 (2009), 67. doi: 10.4254/wjh.v1.i1.67
|
| [35] |
C. Caussin-Schwemling, C. Schmitt, F. Stoll-Keller, Study of the infection of human blood derived monocyte/macrophages with hepatitis C virus in vitro, J. Med. Virol., 65 (2001), 14–22. doi: 10.1002/jmv.1095
|
| [36] |
R. J. Smith, B. D. Aggarwala, Can the viral reservoir of latently infected CD$4{^+}$ T cells be eradicated with antiretroviral HIV drugs?, J. Math. Biol., 59 (2009), 697–715. doi: 10.1007/s00285-008-0245-4
|
| [37] |
P. van den Driessche, J. Watmough, Reproduction numbers and subthreshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29–48. doi: 10.1016/S0025-5564(02)00108-6
|
| [38] |
J. M. HefferNan, R. J. Smith, L. M. Wahl, Perspectives on the basic reproductive ratio, J. R. Soc. Interface., 2 (2005), 281–293. doi: 10.1098/rsif.2005.0042
|





Figures(6) / Tables(1)

Amar Nath Chatterjee, Fahad Al Basir, Yasuhiro Takeuchi. Effect of DAA therapy in hepatitis C treatment — an impulsive control approach[J]. Mathematical Biosciences and Engineering, 2021, 18(2): 1450-1464. doi: 10.3934/mbe.2021075







 DownLoad:
DownLoad: