Citation: Xiujuan Zheng, Zhanheng Li, Xinyi Chun, Xiaomei Yang, Kai Liu. A model-based method with geometric solutions for gaze correction in eye-tracking[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1396-1412. doi: 10.3934/mbe.2020071

| [1] | K. Wang and Q. Ji, 3D gaze estimation without explicit personal calibration, Pattern Recognit., 79 (2018), 216-227. |
| [2] | P. Blignaut and D. Wium, Eye-tracking data quality as affected by ethnicity and experimental design, Behav. Res. Methods, 46 (2014), 67-80. |
| [3] | R. J. D. Tan and J. L. Demer, Heavy eye syndrome versus sagging eye syndrome in high myopia, J. Am. Assoc. Pediatr. Ophthalmol. Strabismus, 19 (2015), 500-506. |
| [4] | C. Biele and P. Kobylinski, Surface Recalibration as a New Method Improving GazeBased Human-Computer Interaction, International Conference on Intelligent Human Systems Integration, 2018, 197-202. Available from: https://link_springer.xilesou.top/chapter/10.1007/978-3-319-73888-8_31. |
| [5] | S. Schenk, M. Dreiser, G. Rigoll, et al., GazeEverywhere: Enabling Gaze-only User Interaction on an Unmodified Desktop PC in Everyday Scenarios, International Conference on Intelligent Human Systems Integration, 2017, 3034-3044. Available from: https://dl_acm.xilesou.top/citation.cfm?id=3025455. |
| [6] | M. A. Vadillo, C. N. Street, T. Beesley, et al., A simple algorithm for the offline recalibration of eye-tracking data through best-fitting linear transformation, Behav. Res. Methods, 47 (2017), 1365-1376. |
| [7] | Y. Zhang and A. J. Hornof, Easy post-hoc spatial recalibration of eye tracking data, Proceedings of the symposium on eye tracking research and applications. ACM, 2014, 95-98. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2578166. |
| [8] | B. Zhu, J. N. Chi and T. X. Zhang, Gaze point compensation method under head movement in gaze tracking system, J. Hignway Transp. Res. Dev., 30 (2013), 105-111. |
| [9] | C. Jin and T. Y. P. Li, Gaze point compensation method based on £iemannian geometry in eye tracking system, Journal of Chongqing University of Posts and Telecommunications, 28 (2016), 395-399. |
| [10] | Y. H. Zhou, Z. H. li and W. L. An, Examination and analysis on keratometry and axis of myopia, Chin. J. Ophthalmol., 31 (1995), 356-358. |
| [11] | R. L. Schwartz and J. H. Calhoun, Surgery of large angle exotropia, J. Pediatr. Ophthalmol. Strabismus, 17 (1980), 359-363. |
| [12] | G. J. Shao, M. Che, B. Y. Zhang, et al., A novel simple 2D model of eye gaze estimation, 2010 Second International Conference on Intelligent Human-Machine Systems and Cybernetics, 2010, 300-304. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/5590853. |
| [13] | T. Santini, W. Fuhl and E. Kasneci, Calibme: Fast and unsupervised eye tracker calibration for gaze-based pervasive human-computer interaction, Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems. ACM, 2017, 2594-2605. Available from: https://dl_acm.xilesou.top/citation.cfm?id=3025950. |
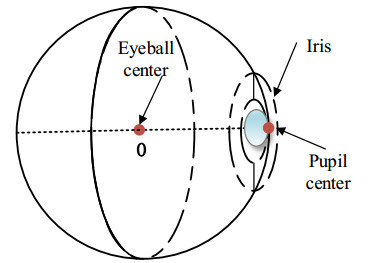
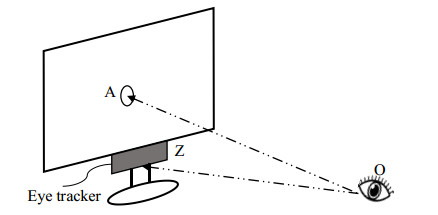
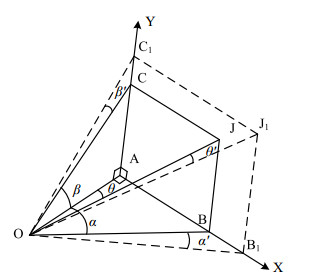
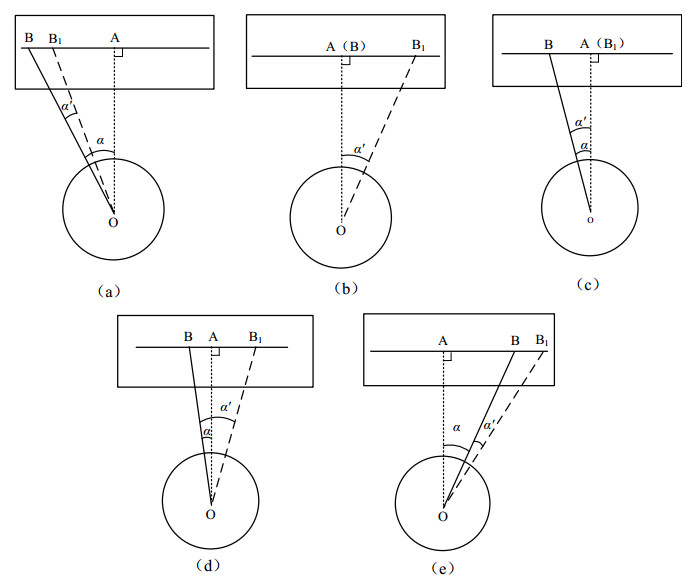
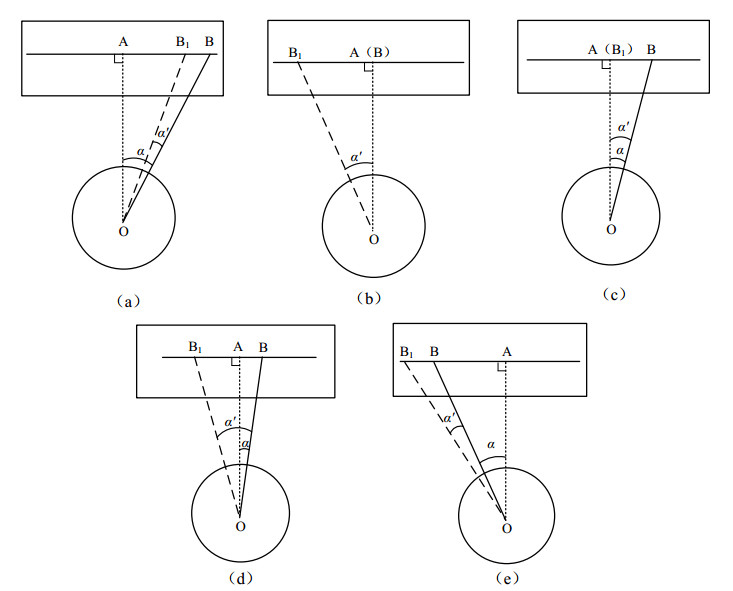
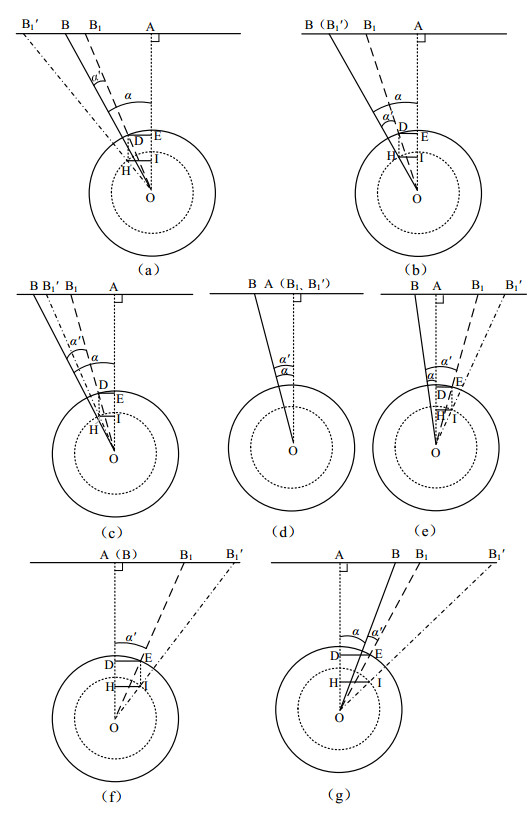
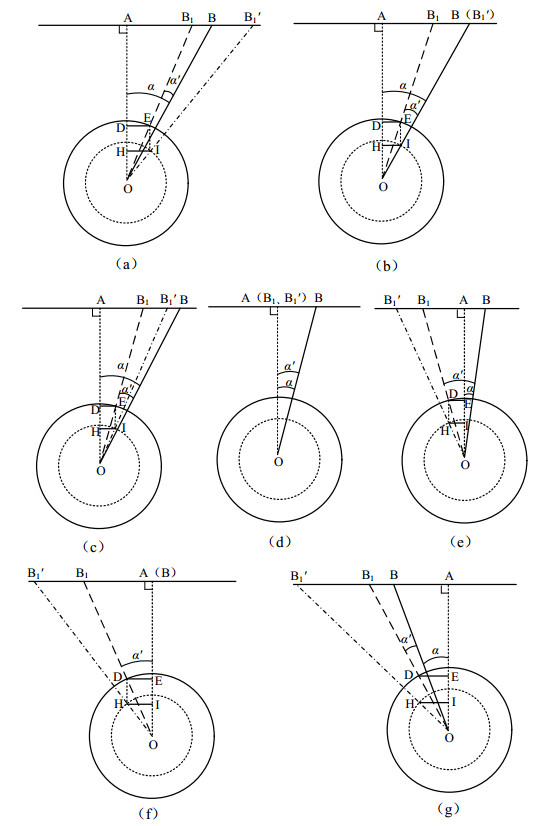
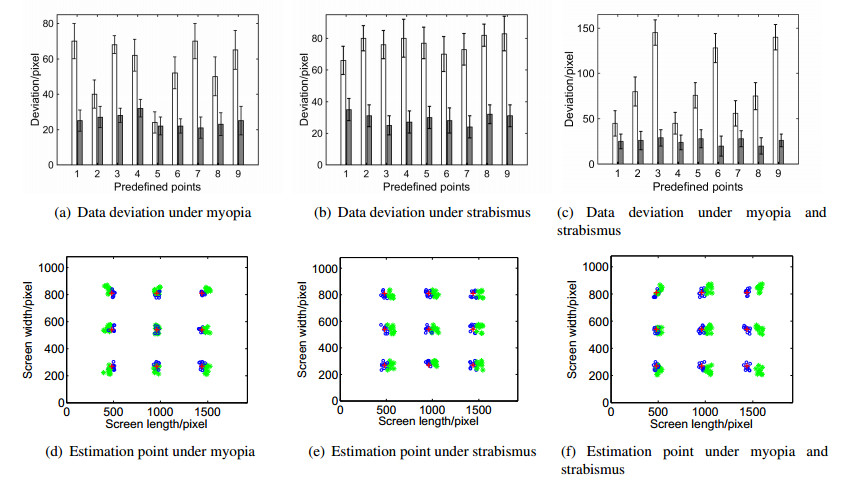
Figures(9)

Xiujuan Zheng, Zhanheng Li, Xinyi Chun, Xiaomei Yang, Kai Liu. A model-based method with geometric solutions for gaze correction in eye-tracking[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1396-1412. doi: 10.3934/mbe.2020071







 DownLoad:
DownLoad: