Citation: Li Li, Min He, Shanqing Zhang, Ting Luo, Chin-Chen Chang. AMBTC based high payload data hiding with modulo-2 operation and Hamming code[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7934-7949. doi: 10.3934/mbe.2019399

| [1] | F. A. P. Petitcolas, R. J. Anderson and M. G. Kuhn, Information hiding-a survey, Proc. IEEE, 87 (1999), 1062–1078. |
| [2] | D. Xiao, J. Liang, Q. Ma, et al., High capacity data hiding in encrypted image based on compressive sensing for nonequivalent resources, CMC Comput. Mater. Continua, 58 (2019), 1–13. |
| [3] | Y. Du, Z. Yin and X. Zhang, Improved lossless data hiding for JPEG images based on histogram modification, CMC Comput. Mater. Continua, 55 (2018), 495–507. |
| [4] | Y. Chen, B. Yin, H. He, et al., Reversible data hiding in classification-scrambling encrypted-image based on iterative recovery, CMC Comput. Mater. Continua, 56 (2018), 299–312. |
| [5] | J. W. Wang, T. Li, X. Y. Luo, et al., Identifying computer generated images based on quaternion central moments in color quaternion wavelet domain, IEEE Trans. Circuits Syst. Video Technol., (2018). |
| [6] | T. Qiao, R. Shi, X. Luo, et al., Statistical model-based detector via texture weight map: Application in re-sampling authentication, IEEE Trans. Multimedia, 21 (2018), 1077–1092. |
| [7] | J. Fridrich, M. Goljan and R. Du, Detecting LSB steganography in color and gray-scale images, IEEE Multimedia, 8 (2001), 22–28. |
| [8] | M. Omoomi, S. Samavi and S. Dumitrescu, An efficient high payload ±1 data embedding scheme, Multimedia Tools Appl., 54 (2011), 201–218. |
| [9] | Y. Zhang, C. Qin, W. Zhang, et al., On the fault-tolerant performance for a class of robust image steganography, Signal Process., 146 (2018), 99–111. |
| [10] | Y. Ma, X. Luo, X. Li, et al., Selection of rich model steganalysis features based on decision rough set α-positive region reduction, IEEE Trans. Circuits Syst. Video Technol., 29 (2018), 336–350. |
| [11] | W. Luo, F. Huang and J. Huang, Edge adaptive image steganography based on LSB matching revisited, IEEE Trans. Inf. Forensics Secur., 5 (2010), 201–214. |
| [12] | W. Hong, Adaptive image data hiding in edges using patched reference table and pair-wise embedding technique, Inf. Sci., 221 (2013), 473–489. |
| [13] | V. Kumar and D. Kumar, A modified DWT-based image steganography technique, Multimedia Tools Appl., 77 (2018), 13279–13308. |
| [14] | C. C. Lin, C. C. Chang and Y. H. Chen, A novel SVD-based watermarking scheme for protecting rightful ownership of digital images, IEEE Trans. Multimedia, 5 (2014), 124–143. |
| [15] | C. C. Chang, T. D. Kieu and W. C. Wu, A lossless data embedding technique by joint neighboring coding, Pattern Recognit., 42 (2009), 1597–1603. |
| [16] | C. C. Chang, Y. H. Chen and C. C. Lin, A data embedding scheme for color images based on genetic algorithm and absolute moment block truncation coding, Soft Comput., 13 (2009), 321–331. |
| [17] | A. J. Zargar and A. K. Singh, Robust and imperceptible image watermarking in DWT-BTC domain, Int. J. Electron. Secur. Digital Forensics, 8 (2016), 53–62. |
| [18] | C. K. Chan and L. M. Cheng, Hiding data in images by simple LSB substitution, Pattern Recognit., 37 (2004), 469–474. |
| [19] | J. A. Fessler and B. P. Sutton, Nonuniform fast Fourier transforms using min-max interpolation, IEEE Trans. Signal Process., 51 (2003), 560–574. |
| [20] | B. Chen, S. Latifi and J. Kanai, Edge enhancement of remote image data in the DCT domain, Image Vision Comput., 17 (1999), 913–921. |
| [21] | C. Qin and Y. C. Hu, Reversible data hiding in VQ index table with lossless coding and adaptive switching mechanism, Signal Process., 129 (2016), 48–55. |
| [22] | Y. Qiu, H. He, Z. Qian, et al., Lossless data hiding in JPEG bitstream using alternative embedding, J. Visual Commun. Image Representation, 52 (2018), 86–91. |
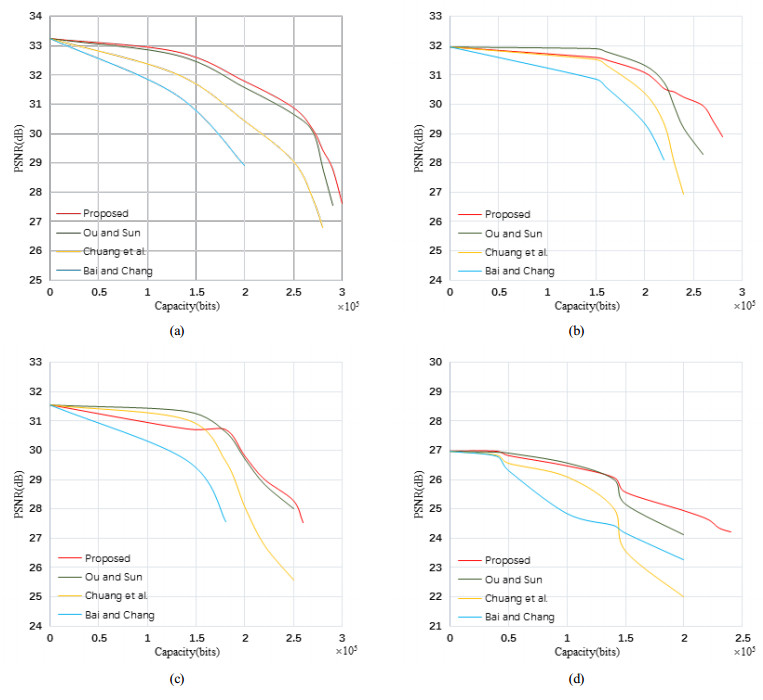
| [23] | J. C. Chuang and C. C. Chang, Using a simple and fast image compression algorithm to hide secret information, Int. J. Comput. Appl., 28 (2006), 329–333. |
| [24] | D. Ou and W. Sun, High payload image steganography with minimum distortion based on absolute moment block truncation coding, Multimedia Tools Appl., 74 (2015), 9117–9139. |
| [25] | J. Bai and C. C. Chang, High payload steganographic scheme for compressed images with Hamming code, Int. J. Network Secur., 18 (2016), 1122–1129. |
| [26] | C. Kim, D. Shin, L. Leng, et al., Lossless data hiding for absolute moment block truncation coding using histogram modification, J. Real-Time Image Process., 14 (2018), 101–114. |
| [27] | R. Kumar, D. S. Kim and K. H. Jung, Enhanced AMBTC based data hiding method using hamming distance and pixel value differencing, J. Inf. Secur. Appl., 47 (2019), 94–103. |
| [28] | R. Kumar, N. Kumar and K. H. Jung, A new data hiding method using adaptive quantization & dynamic bit plane based AMBTC, 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), 2019, 854–858. Available from: https://ieeexplore.ieee.org/abstract/document/8711774. |
| [29] | M. Lema and O. Mitchell, Absolute moment block truncation coding and its application to color images, IEEE Trans. Commun., 32 (1984), 1148–1157. |
| [30] | P. Fränti, O. Nevalainen and T. Kaukoranta, Compression of digital images by block truncation coding: A survey, Comput. J., 37 (1994), 308–332. |
| [31] | C. Kim, D. Shin, B. G. Kim, et, al.,Secure medical images based on data hiding using a hybrid scheme with the Hamming code, LSB, and OPAP, J. Real-Time Image Process., 14 (2018), 115–126. |
| [32] | E. Tsimbalo, X. Fafoutis and R. Piechocki, CRC error correction in IoT applications, IEEE Trans. Ind. Inf., 13 (2017), 361–369. |
| [33] | C. Kim, Data hiding by an improved exploiting modification direction, Multimedia Tools Appl., 69 (2014), 569–584. |
| [34] | Z. Wang, A. C. Bovik, H. R. Sheikh, et al., Image quality assessment: From error visibility to structural similarity, IEEE Trans. Image Process., 13 (2004), 600–612. |



Figures(8) / Tables(2)

Li Li, Min He, Shanqing Zhang, Ting Luo, Chin-Chen Chang. AMBTC based high payload data hiding with modulo-2 operation and Hamming code[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7934-7949. doi: 10.3934/mbe.2019399







 DownLoad:
DownLoad: