Citation: Rong Li, Xiangyang Li, Yan Xiong, An Jiang, David Lee. An IPVO-based reversible data hiding scheme using floating predictors[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 5324-5345. doi: 10.3934/mbe.2019266

| [1] | J. Fridrich. M. Goljan and R. Du, Lossless data embedding-new paradigm in digital watermarking, EURASIP J. Adv. Signal Process., 2 (2002), 185–196. |
| [2] | M. U. Celik, G. Sharma and A. M. Tekalp, Lossless generalized-LSB data embedding, IEEE Transact. Image Process., 14 (2005), 253–266. |
| [3] | J. Tian, Reversible data embedding using a difference expansion, IEEE Transact. Circuit. Syst. Video Technol., 13 (2003), 890–896. |
| [4] | A. M. Alattar, Reversible watermark using the difference expansion of a generalized integer transform, IEEE Transact. Image Process., 13 (2004), 1147–1156. |
| [5] | Z. Ni, Y.Q. Shi and N. Snsari, Reversible data hiding, IEEE Transact. Circuit. Syst. Video Technol., 16 (2006), 354–362. |
| [6] | C. Kim, Content-based image copy detection, Signal Process. Image Commun., 18 (2003), 169 –184. |
| [7] | S. K. Lee, Y. H. Suh and Y. S. Ho, Reversible image authentication based on water-marking, Process IEEE ICME, (2006), 1321–1324. |
| [8] | X. Li, B. Li and B. Yang, General framework to histogram-shifting-based reversible data hiding, IEEE Transact. Image Process., 23 (2013), 2181–2191. |
| [9] | D. M. Thodi and J. J. Rodrigues, Expansion embedding techniques for reversible watermarking, IEEE Transact. Image Process., 16 (2007), 721–730. |
| [10] | D. M. Thodi and J. J. Rodrigues, Reversible watermarking by prediction-error expansion, IEEE Southwest Symposium on Image Analysis & Interpretation IEEE, (2004), 21–25. |
| [11] | H. W. Tseng and C. P. Hsieh, Prediction-based reversible data hiding, Inform. Sci., 179 (2009), 2460–2469. |
| [12] | C. F. Lee, H. L. Chen and H. K. Tso, Embedding capacity raising in reversible data hiding based on prediction of difference expansion, J. Syst. Software, 83(2010), 1864–1872. |
| [13] | Q. Shen, G. Liu and W. Liu, Adaptive image steganography based on pixel selection, 2015 IEEE International Conference on Progress in Informatics & Computing, 2016. |
| [14] | Y. Hu, H. K. Lee and J. Li, De-based reversible data hiding with improved overflow location map, IEEE Transact. Circuits Syst. Video Technol., 19 (2009), 250–260. |
| [15] | X. Li, B. Yang and T. Zeng, Efficient reversible watermarking based on adaptive prediction-error expansion and pixel selection, IEEE Transact. Image Process., 20 (2011), 3524–3533. |
| [16] | D. Coltuc, Improved embedding for prediction-based reversible watermarking, IEEE Transact. Inform. Forens. Secur., 6 (2011), 873–882. |
| [17] | D. Coltuc, Low distortion transform for reversible watermarking, IEEE Transact. Image Process., 21 (2012), 412–417. |
| [18] | X. Li, J. Li and B. Li, High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion, Signal Process., 93(2013), 198–205. |
| [19] | B. Ou, X. Li and Y. Zhao, Reversible data hiding using invariant pixel value ordering and prediction-error expansion, Signal Process., 29 (2013), 760–772. |
| [20] | X. Qu and H. J. Kim, Pixel-based pixel value ordering predictor for high-fidelity reversible data hiding, Signal Process., 111(2015), 249–260. |
| [21] | F. Peng, X. Li and B. Yang, Improved PVO-based reversible data hiding, Digital Signal Process., 25 (2014), 255–265. |
| [22] | P. Subitha and V. Vaithiyanathan, Novel reversible pixel-value-ordering technique for secret concealment, Indian J. Sci. Technol., 8 (2015), 628–636. |
| [23] | K. H. Jung, A high-capacity reversible data hiding scheme based on sorting and prediction in digital images, Mult. Tools Appl., 76(2017), 13127–13137. |
| [24] | W. He, G. Xiong and S. Weng, Reversible data hiding using multi-pass pixel value ordering and prediction-error expansion, Inform. Sci., 467(2018), 784–799. |
| [25] | Y. Du, Z. X. Yin and X. P. Zhang, Improved lossless data hiding for jpeg images based on histogram modification, Comput. Mater. Cont., 55(2018), 495–507. |
| [26] | X. T. Duan, H. X. Song and C. Qin, Coverless steganography for digital images based on a generative model, Comput. Mater. Cont., 55(2018), 483–493. |
| [27] | L. Z. Xiong and Y. Q. Shi, On the privacy-preserving outsourcing scheme of reversible data hiding over encrypted image data in cloud computing, Comput. Mater. Cont., 55(2018), 523–539. |
| [28] | M. J. Weinberger, G. Seroussi and G. Sapiro, The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS, IEEE Transact. Image Process., 9 (2000), 1309–1324. |
| [29] | X. Wu and N. Memon, Context-based, adaptive, lossless image coding, IEEE Transact. Commun., 45 (1997), 437–444. |
| [30] | V. Sachnev, H. J. Kim and J. Nam, Reversible watermarking algorithm using sorting and prediction, IEEE Transact. Circuit. Syst. Video Technol., 19 (2009), 989–999. |


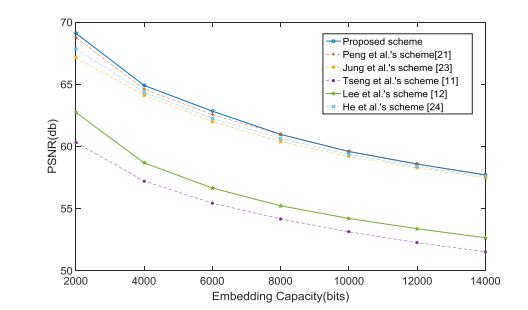
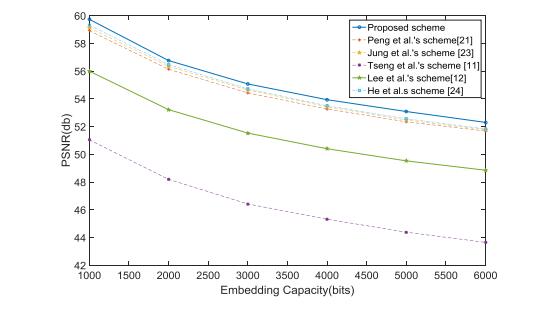
Figures(12) / Tables(9)

Rong Li, Xiangyang Li, Yan Xiong, An Jiang, David Lee. An IPVO-based reversible data hiding scheme using floating predictors[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 5324-5345. doi: 10.3934/mbe.2019266







 DownLoad:
DownLoad: