Citation: Zhiguo Qu, Shengyao Wu, Le Sun, Mingming Wang, Xiaojun Wang. Effects of quantum noises on χ state-based quantum steganography protocol[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4999-5021. doi: 10.3934/mbe.2019252

| [1] | W. J. Liu, P. P. Gao, W. B. Yu, et al., Quantum Relief algorithm, Quantum Inf. Process., 17 (2018), 280. |
| [2] | W. J. Liu, H. B. Wang, G. L. Yuan, et al., Multiparty quantum sealed-bid auction using single photons as message carrier, Quantum Inf. Process., 15 (2016), 869–879. |
| [3] | W. J. Liu, Z. Y. Chen, J. S. Liu, et al., Full-blind delegating private quantum computation, CMC-Comput. Mater. Con., 56 (2018), 211–223. |
| [4] | W. J. Liu, Y. Xu, C. N. Yang, et al., An efficient and secure arbitrary n-party quantum key agreement protocol using Bell states, Int. J. Theor. Phys., 57 (2018), 195–207. |
| [5] | X. B. Chen, X. Tang, G. Xu, et al., Cryptanalysis of secret sharing with a single d-level quantum system, Quantum Inf. Process., 17 (2018), 225. |
| [6] | J. W. Wang, T. Li, X. Y. Luo, et al., Identifying computer generated images based on quaternion central moments in color quaternion wavelet domain, IEEE T. Circ. Syst. Vid., (2018), 1. |
| [7] | Y. Zhang, C. Qin, W. M. Zhang, et al., On the fault-tolerant performance for a class of robust image steganography, Signal Process., 146 (2018), 99–111. |
| [8] | X. Y. Luo, X. F. Song, X. L. Li, et al., Steganalysis of HUGO steganography based on parameter recognition of syndrome-trellis-codes, Multimed. Tools Appl., 75 (2016), 13557–13583. |
| [9] | T. Qiao, R. Shi, X. Y. Luo, et al., Statistical model-based detector via texture weight map: application in re-sampling authentication, IEEE T. Multimedia, 21 (2019), 1077–1092. |
| [10] | Y. Y. Ma, X. Y. Luo, X. L. Li, et al., Selection of rich model steganalysis features based on decision rough set -positive region reduction, IEEE T. Circ. Syst. Vid., 29 (2019), 336–350. |
| [11] | Z. G. Qu, J. Keeney, S. Robitzsch, et al., Multilevel pattern mining architecture for automatic network monitoring in heterogeneous wireless communication networks, China Commun., 13 (2016), 106–116. |
| [12] | G. Xu, X. B. Chen and J. Li, Network coding for quantum cooperative multicast, Quantum Inf. Process., 14 (2015), 4297–4322. |
| [13] | C. H. Bennett, G. Brassard, C. Crepeau, et al., Teleporting an unknown quantum state via dual classical and Einstein-Podolsky-Rosen channels, Phys. Rev. Lett., 70 (1993), 1895–1899. |
| [14] | X. B. Chen, Y. R. Sun, G. Xu, et al., Controlled bidirectional remote preparation of three-qubit state, Quantum Inf. Process., 16 (2017), 244. |
| [15] | M. M. Wang, C. Yang and R. Mousoli, Controlled cyclic remote state preparation of arbitrary qubit states, CMC-Comput. Mater. Con., 55 (2018), 321–329. |
| [16] | C. H. Bennett and G. Brassard, Quantum cryptography: Public key distribution and coin tossing, Theor. Comput. Sci., 560 (2014), 7–11. |
| [17] | M. Hillery, V. Buzek and A. Berthiaume, Quantum secret sharing, Phys. Rev. A, 59 (1999), 1829–1834. |
| [18] | M. Curty and D. J. Santos, Quantum authentication of classical messages, Phys. Rev. A, 64 (2012), 168–1. |
| [19] | B. M. Terhal, D. P. Divincenzo and D. W. Leung, Hiding bits in Bell states, Phys. Rev. Lett., 86 (2001), 5807–5810. |
| [20] | D. P. Divincenzo, D. W. Leung and B. M. Terhal, Quantum data hiding, IEEE T. Inform. Theory, 48 (2001), 580–598. |
| [21] | B. A. Shaw and T. A. Brun, Quantum steganography with noisy quantum channels, Phys. Rev. A, 83 (2011), 498–503. |
| [22] | B. A. Shaw and T. A. Brun, Hiding quantum information in the perfect code, preprint, arXiv:1007.0793. |
| [23] | T. Mihara, Quantum steganography embedded any secret text without changing the content of cover data, J. Quantum Inf. Sci., 2 (2012), 10–14. |
| [24] | Z. H. Wei, X. B. Chen, X. X. Niu, et al., The quantum steganography protocol via quantum noisy channels, Int. J. Theor. Phys., 54 (2015), 2505–2515. |
| [25] | T. Mihara, Quantum steganography using prior entanglement, Phys. Lett. A, 379 (2015), 952–955. |
| [26] | Z. G. Qu, T. C. Zhu and J. W. Wang, A novel quantum steganography based on Brown states, CMC-Comput. Mater. Con., 1 (2018), 47–59. |
| [27] | Z. G. Qu, Z. W. Cheng, W. J. Liu, et al., A novel quantum image steganography algorithm based on exploiting modification direction, Multimed. Tools Appl., 78 (2019), 7981–8001. |
| [28] | Z. G. Qu, Z. W. Chen, W. B. Yu, et al., Matrix coding-based quantum image steganography algorithm, IEEE Access, 1 (2019), 99–114. |
| [29] | G. C. Guo and G. P. Guo, Quantum data hiding with spontaneous parameter down-conversion, Phys. Rev. A, 68 (2003), 044303. |
| [30] | K. Martin, Steganographic communication with quantum information, Lecture Notes in Computer Science(LNCS), 4567 (2007), 32–49. |
| [31] | Z. G. Qu, X. B. Chen, X. J. Zhou, et al., Novel quantum steganography with large payload, Opt. Commun., 283 (2010), 4782–4786. |
| [32] | Z. G. Qu, X. B. Chen, M. X. Luo, et al., Quantum steganography with large payload based on entanglement swapping of χ-type entangled states, Opt. Commun., 284 (2011), 2075–2082. |
| [33] | Z. H. Wei, X. B. Chen, X. X. Niu, et al., A novel quantum steganography protocol based on probability measurements, Int. J. Quantum Inf., 11 (2013), 1350068. |
| [34] | Z. H. Wei, X. B. Chen, X. X. Niu, et al., Least significant qubit (LSQb) information hiding algorithm for quantum image, Int. J. Theor. Phys., 54 (2015), 32–38. |
| [35] | S. Heidari and E. Farzadnia, A novel quantum lsb-based steganography method using the gray code for colored quantum images, Quantum Inf. Process., 16 (2017), 242. |
| [36] | Z. G. Qu, Z. W. Cheng, M. X. Luo, et al., A robust quantum watermark algorithm based on quantum log-polar images, Int. J. Theor. Phys., 56 (2017), 3460–3476. |
| [37] | Z. G. Qu, S. Y. Chen and S. Ji, A novel quantum video steganography protocol with large payload based on mcqi quantum video, Int. J. Theor. Phys., 56 (2017), 1–19. |
| [38] | R. Laflamme, C. Miquel, J. P. Paz, et al., Perfect quantum error correcting code, Phys. Rev. Lett., 77 (1996), 198–201. |
| [39] | L. M. Duan and G. C. Guo, Preserving coherence in quantum computation by pairing quantum bits, Physics, 79 (1998), 1953–1956. |
| [40] | H. Zheng, S. Y. Zhu and M. S. Zubairy, Quantum zeno and anti-zeno effects: without the rotating- wave approximation, Phys. Rev. Lett., 101 (2008), 200404. |
| [41] | Z. G. Qu, S. Y. Chen, S. Ji, et al., Anti-noise bidirectional quantum steganography qrotocol with large payload, Int. J. Theor. Phys., 57 (2018), 1–25. |
| [42] | Z. G. Qu, S. Y. Wu, W. J. Liu, et al., Analysis and Improvement of Steganography Protocol Based on Bell States in Noise Environment, CMC-Comput. Mater. Con., 59 (2019), 607–624. |
| [43] | N. K. Alexander and K. Kyle, Decoherence suppression by quantum measurement reversal, Phys. Rev. A, 81 (2010), 040103. |
| [44] | X. W. Guan, X. B. Chen and L. C. Wang, Joint remote preparation of an arbitrary two-qubit state in noisy environments, Int. J. Theor. Phys., 53 (2014), 2236–2245. |
| [45] | F. Raphael and R. Gustavo, Fighting noise with noise in realistic quantum teleportation, Phys. Rev. A, 92 (2015), 012338. |
| [46] | M. M. Wang and Z. G. Qu, Effect of quantum noise on deterministic joint remote state preparation of a qubit state via a GHZ channel, Quantum Inf. Process., 15 (2016), 4805–4818. |
| [47] | M. M. Wang, Z. G. Qu and W. Wang, Effect of noise on deterministic joint remote preparation of an arbitrary two-qubit state, Quantum Inf. Process., 16 (2017), 140. |
| [48] | M. M. Wang, Z. G. Qu, W. Wang, et al., Effect of noise on joint remote preparation of multi-qubit state, Int. J. Quantum Inf., 15 (2017), 1750012. |
| [49] | Z. G. Qu, S. Y. Wu, M. M. Wang, et al., Effect of quantum noise on deterministic remote state preparation of an arbitrary two-particle state via various quantum entangled channels, Quantum Inf. Process., 16 (2017), 306–331. |
| [50] | L. Sun, S. Y. Wu, Z. G. Qu, et al., The effect of quantum noise on two different deterministic remote state preparation of an arbitrary three-particle state protocols, Quantum Inf. Process., 17 (2018), 283–301. |
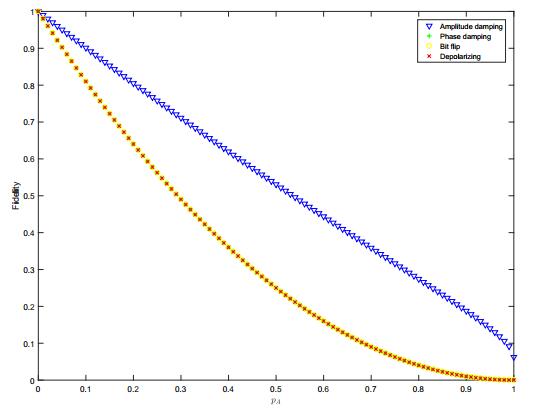
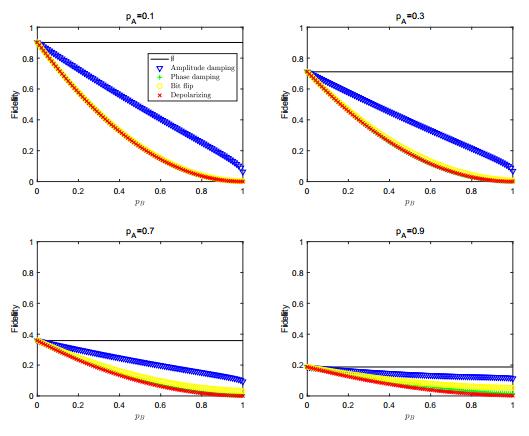
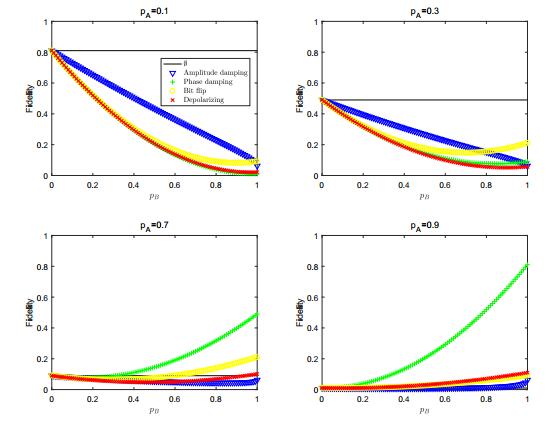
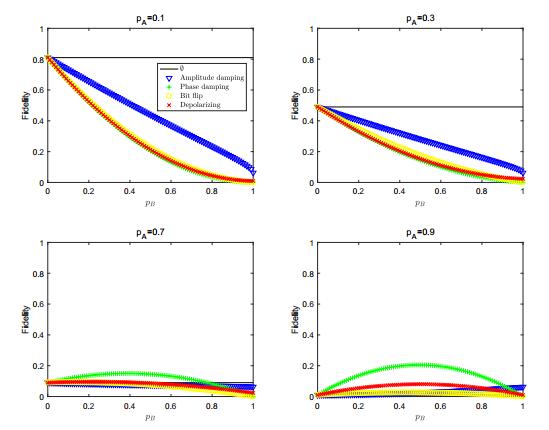
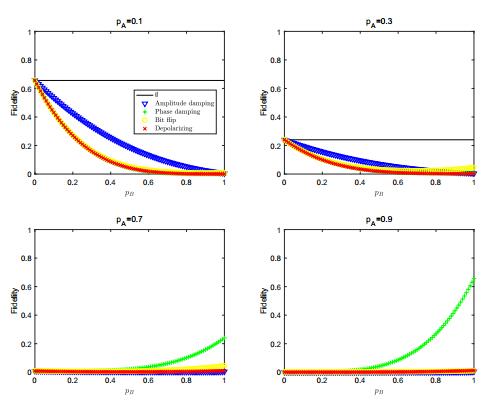
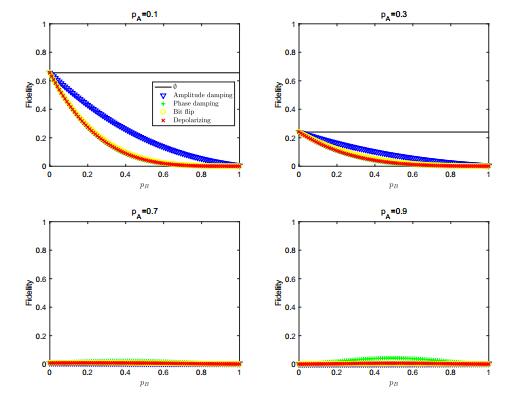
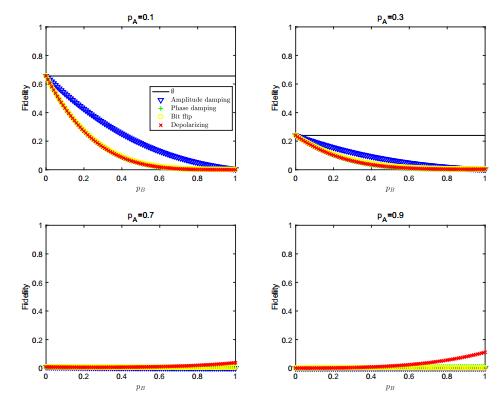
Figures(11) / Tables(1)

Zhiguo Qu, Shengyao Wu, Le Sun, Mingming Wang, Xiaojun Wang. Effects of quantum noises on χ state-based quantum steganography protocol[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4999-5021. doi: 10.3934/mbe.2019252







 DownLoad:
DownLoad: