As is well known, it is impossible to model reality with its true level of detail. Additionally, it is impossible to make an infinite number of observations, which are always contaminated by noise. These circumstances imply that, in an inverse problem, the misfit of the best estimated model will always be less than that of the true one. Therefore, it is not possible to reconstruct the model that actually generated the collected observations. The best way to express the solution of an inverse problem is as a collection of models that explain the observations at a certain misfit level according to a defined cost function. One of the main advantages of global search methods over local ones is that, in addition to not depending on an initial model, they provide a set of generated models with which statistics can be made. In this paper we present a technique for analyzing the results of any global search method, particularized to the particle swarm optimization algorithm applied to the solution of a two-dimensional gravity inverse problem in sedimentary basins. Starting with the set of generated models, we build the equivalence region of a predefined tolerance which contains the best estimated model, i.e., which involves the estimated global minimum of the cost function. The presented algorithm improves the efficiency of the equivalence region detection compared to our previous works.
Citation: J. L. G. Pallero, M. Z. Fernández-Muñiz, J. L. Fernández-Martínez, S. Bonvalot. Posterior analysis of particle swarm optimization results applied to gravity inversion in sedimentary basins[J]. AIMS Mathematics, 2024, 9(6): 13927-13943. doi: 10.3934/math.2024677
As is well known, it is impossible to model reality with its true level of detail. Additionally, it is impossible to make an infinite number of observations, which are always contaminated by noise. These circumstances imply that, in an inverse problem, the misfit of the best estimated model will always be less than that of the true one. Therefore, it is not possible to reconstruct the model that actually generated the collected observations. The best way to express the solution of an inverse problem is as a collection of models that explain the observations at a certain misfit level according to a defined cost function. One of the main advantages of global search methods over local ones is that, in addition to not depending on an initial model, they provide a set of generated models with which statistics can be made. In this paper we present a technique for analyzing the results of any global search method, particularized to the particle swarm optimization algorithm applied to the solution of a two-dimensional gravity inverse problem in sedimentary basins. Starting with the set of generated models, we build the equivalence region of a predefined tolerance which contains the best estimated model, i.e., which involves the estimated global minimum of the cost function. The presented algorithm improves the efficiency of the equivalence region detection compared to our previous works.

| [1] |
A. G. Camacho, P. Vajda, J. Fernández, GROWTH-23: an integrated code for inversion of complete Bouguer gravity anomaly or temporal gravity changes, Comput. Geosci., 182 (2023), 105495. https://doi.org/10.1016/j.cageo.2023.105495 doi: 10.1016/j.cageo.2023.105495

|
| [2] |
S. Liu, M. Liang, X. Hu, Particle swarm optimization inversion of magnetic data: field examples from iron ore deposits in China, Geophysics, 83 (2018), J43–J59. https://doi.org/10.1190/geo2017-0456.1 doi: 10.1190/geo2017-0456.1
|
| [3] |
A. G. Yeguas, J. Almendros, R. Abella, J. M. Ibáñez, Quantitative analysis of seismic wave propagation anomalies in azimuth and apparent slowness at Deception Island volcano (Antarctica) using seismic arrays, Geophys. J. Int., 184 (2011), 801–815. https://doi.org/10.1111/j.1365-246X.2010.04864.x doi: 10.1111/j.1365-246X.2010.04864.x
|
| [4] |
W. W. Symes, The seismic reflection inverse problem, Inverse Probl., 25 (2009), 123008. https://doi.org/10.1088/0266-5611/25/12/123008 doi: 10.1088/0266-5611/25/12/123008
|
| [5] |
O. Bar, G. Even-Tzur, Fault-model parameters estimation using a feature-voting technique: Dead Sea fault as a case study, Comput. Geosci., 179 (2023), 105422. https://doi.org/10.1016/j.cageo.2023.105422 doi: 10.1016/j.cageo.2023.105422
|
| [6] |
M. Á. Benito-Saz, F. Sigmundsson, M. Charco, A. Hooper, M. Parks, Magma flow rates and temporal evolution of the 2012–2014 post-eruptive intrusions at El Hierro, Canary Islands, J. Geophys. Res.: Solid Earth, 124 (2019), 12576–12592. https://doi.org/10.1029/2019JB018219 doi: 10.1029/2019JB018219
|
| [7] | A. N. Tikhonov, V. Y. Arsenin, Solutions of ill-posed problems, Washington, DC: V. H. Winston and Sons, 1977. |
| [8] | R. J. Blakely, Potential theory in gravity and magnetic applications, Cambridge University Press, 1996. |
| [9] | M. S. Zhdanov, Inverse theory and applications in geophysics, 2 Eds., Oxford: Elsevier, 2015. |
| [10] |
J. L. Fernández-Martínez, J. L. G. Pallero, Z. Fernández-Muñiz, L. M. Pedruelo-González, The effect of noise and Tikhonov's regularization in inverse problems. Part II: the nonlinear case, J. Appl. Geophys., 108 (2014), 186–193. https://doi.org/10.1016/j.jappgeo.2014.05.005 doi: 10.1016/j.jappgeo.2014.05.005
|
| [11] | R. L. Parker, Understanding inverse theory, Ann. Rev. Earth Planet. Sci., 5 (1977), 35–64. https://doi.org/10.1146/annurev.ea.05.050177.000343 |
| [12] | R. C. Aster, B. Borchers, C. H. Thurber, Parameter estimation and inverse problems, 2 Eds., New York: Academic Press, 2012. |
| [13] |
S. Katoch, S. S. Chauhan, V. Kumar, A review on genetic algorithm: past, present, and future, Multimed. Tools Appl., 80 (2020), 8091–8126. https://doi.org/10.1007/s11042-020-10139-6 doi: 10.1007/s11042-020-10139-6
|
| [14] |
S. Kirkpatrick, C. D. Gelatt, M. P. Vecchi, Optimization by simulated annealing, Science, 220 (1983), 671–680. https://doi.org/10.1126/science.220.4598.671 doi: 10.1126/science.220.4598.671
|
| [15] | J. Kennedy, R. Eberhart, Particle swarm optimization, Proceedings of ICNN'95–International Conference on Neural Networks, 1995, 1942–1948. https://doi.org/10.1109/ICNN.1995.488968 |
| [16] |
A. Tarantola, Popper, Bayes and the inverse problem, Nature Phys., 2 (2006), 492–494. https://doi.org/10.1038/nphys375 doi: 10.1038/nphys375
|
| [17] |
J. L. Fernández-Martínez, M. Z. Fernández-Muñiz, M. J. Tompkins, On the topography of the cost functional in linear and nonlinear inverse problems, Geophysics, 77 (2012), W1–W15. https://doi.org/10.1190/geo2011-0341.1 doi: 10.1190/geo2011-0341.1
|
| [18] | J. A. Scales, R. Snieder, To Bayes or not to Bayes, Geophysics, 62 (1997), 1045–1046. https://doi.org/10.1190/1.6241045.1 |
| [19] |
J. A. Scales, R. Snieder, The anatomy of inverse problems, Geophysics, 65 (2000), 1708–1710. https://doi.org/10.1190/geo2000-0001.1 doi: 10.1190/geo2000-0001.1
|
| [20] |
Z. Fernández-Muñiz, J. L. G. Pallero, J. L. Fernández-Martínez, Anomaly shape inversion via model reduction and PSO, Comput. Geosci., 140 (2020), 104492. https://doi.org/10.1016/j.cageo.2020.104492 doi: 10.1016/j.cageo.2020.104492
|
| [21] | J. L. G. Pallero, J. L. Fernández-Martínez, Z. Fernández-Muñiz, S. Bonvalot, G. Gabalda, T. Nalpas, GRAVPSO2D: a Matlab package for 2D gravity inversion in sedimentary basins using the Particle Swarm Optimization algorithm, Comput. Geosci., 146 (2021), 104653. https://doi.org/10.1016/j.cageo.2020.104653 |
| [22] |
A. Jamasb, S. H. Motavalli-Anbaran, H. Zeyen, Non-linear stochastic inversion of gravity data via quantum-behaved particle swarm optimisation: application to Eurasia-Arabia collision zone (Zagros, Iran), Geophys. Prospect., 65 (2017), 274–294. https://doi.org/10.1111/1365-2478.12558 doi: 10.1111/1365-2478.12558
|
| [23] |
A. Jamasb, S. H. Motavalli-Anbaran, K. Ghasemi, A novel hybrid algorithm of particle swarm optimization and evolution strategies for geophysical non-linear inverse problems, Pure Appl. Geophys., 176 (2019), 1601–1613. https://doi.org/10.1007/s00024-018-2059-7 doi: 10.1007/s00024-018-2059-7
|
| [24] | S. Loni, M. Mehramuz, Gravity field inversion using improved particle swarm optimization (IPSO) for estimation of sedimentary basin basement depth, Contrib. Geophys. Geod., 50 (2020), 303–323. |
| [25] |
A. Roy, C. P. Dubey, M. Prasad, Gravity inversion of basement relief using particle swarm optimization by automated parameter selection of Fourier coefficients, Comput. Geosci., 156 (2021), 104875. https://doi.org/10.1016/j.cageo.2021.104875 doi: 10.1016/j.cageo.2021.104875
|
| [26] | L. L. Nettleton, Gravity and magnetics in oil prospecting, International Series in the Earth and Planetary Sciences, McGraw-Hill, 1976. |
| [27] |
M. H. P. Bott, The use of rapid digital computing methods for direct gravity interpretation of sedimentary basins, Geophys. J. R. Astron. Soc., 3 (1960), 63–67. https://doi.org/10.1111/j.1365-246X.1960.tb00065.x doi: 10.1111/j.1365-246X.1960.tb00065.x
|
| [28] |
V. Chakravarthi, Gravity interpretation of nonoutcropping sedimentary basins in which the density contrast decreases parabolically with depth, Pure Appl. Geophys., 145 (1995), 327–335. https://doi.org/10.1007/BF00880274 doi: 10.1007/BF00880274
|
| [29] |
J. B. C. Silva, W. A. Teixeira, V. C. F. Barbosa, Gravity data as a tool for landfill study, Environ. Geol., 57 (2009), 749–757. https://doi.org/10.1007/s00254-008-1353-6 doi: 10.1007/s00254-008-1353-6
|
| [30] |
J. B. C. Silva, A. S. Oliveira, V. C. F. Barbosa, Gravity inversion of 2D basement relief using entropic regularization, Geophysics, 75 (2010), I29–I35. https://doi.org/10.1190/1.3374358 doi: 10.1190/1.3374358
|
| [31] | M. B. Dobrin, C. H. Savit, Introduction to geophysical prospecting, 4 Eds., Geology Series, McGraw-Hill, 1988. |
| [32] |
V. C. F. Barbosa, J. B. C. Silva, Generalized compact gravity inversion, Geophysics, 95 (1994), 57–68. https://doi.org/10.1190/1.1443534 doi: 10.1190/1.1443534
|
| [33] |
J. L. Fernández-Martínez, E. García-Gonzalo, The PSO family: deduction, stochastic analysis and comparison, Swarm Intell., 3 (2009), 245–273. https://doi.org/10.1007/s11721-009-0034-8 doi: 10.1007/s11721-009-0034-8
|
| [34] | O. F. Ladino, A. Bassrei, A hybrid fast 3D inversion algorithm of gravity data for basement relief definition, SEG Technical Program Expanded Abstracts 2016, 2016, 1521–1525. https://doi.org/10.1190/segam2016-13840764.1 |
| [35] |
A. Singh, A. Biswas, Application of global particle swarm optimization for inversion of residual gravity anomalies over geological bodies with idealized geometries, Nat. Resour. Res., 25 (2016), 297–314. https://doi.org/10.1007/s11053-015-9285-9 doi: 10.1007/s11053-015-9285-9
|
| [36] | B. Moussirou, Quantification du remplissage quaternaire des vallées glaciaires des Pyrénées par la méthode gravimétrique, MS. Thesis, Université Toulouse III–Paul Sabatier, 2013. |
| [37] | S. Perrouty, Mesures géophysiques du remplissage sédimentaire Quaternaire dans les vallées de Bagnères de Bigorre et d'Argelès-Gazost (Hautes-Pyrénées), MS. Thesis, Université Toulouse III–Paul Sabatier, 2008. |
| [38] |
S. Perrouty, B. Moussirou, J. Martinod, S. Bonvalot, S. Carretier, G. Gabalda, et al., Geometry of two glacial valleys in the northern Pyrenees estimated using gravity data, C. R. Geosci., 347 (2015), 13–23. https://doi.org/10.1016/j.crte.2015.01.002 doi: 10.1016/j.crte.2015.01.002
|
| [39] |
J. L. G. Pallero, J. L. Fernández-Martínez, S. Bonvalot, O. Fudym, 3D gravity inversion and uncertainty assessment of basement relief via particle swarm optimization, J. Appl. Geophys., 139 (2017), 338–350. https://doi.org/10.1016/j.jappgeo.2017.02.004 doi: 10.1016/j.jappgeo.2017.02.004
|
| [40] | M. H. Alimen, Le quaternaire des Pyrénées de la Bigorre, Imprimerie nationale, 1964. |
| [41] |
J. W. Cady, Calculation of gravity and magnetic anomalies of finite length-right polygonal prisms, Geophysics, 45 (1980), 1507–1512. https://doi.org/10.1190/1.1441045 doi: 10.1190/1.1441045
|
| [42] |
P. K. Fullagar, N. A. Hughes, J. Paine, Drilling-constrained 3D gravity interpretation, Explor. Geophys., 31 (2000), 17–23. https://doi.org/10.1071/EG00017 doi: 10.1071/EG00017
|
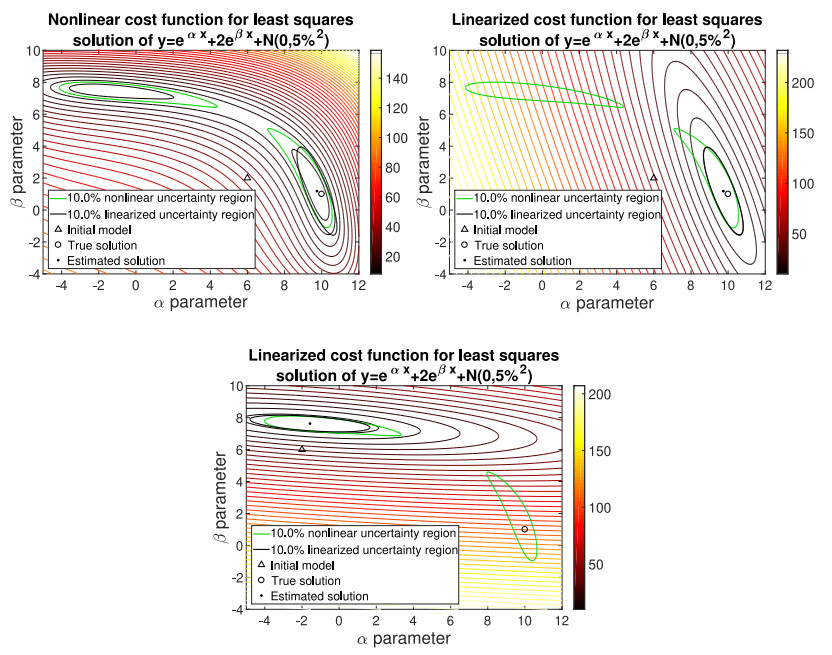




Figures(5)

J. L. G. Pallero, M. Z. Fernández-Muñiz, J. L. Fernández-Martínez, S. Bonvalot. Posterior analysis of particle swarm optimization results applied to gravity inversion in sedimentary basins[J]. AIMS Mathematics, 2024, 9(6): 13927-13943. doi: 10.3934/math.2024677







 DownLoad:
DownLoad: