Citation: Tarek Frahi, Clara Argerich, Minyoung Yun, Antonio Falco, Anais Barasinski, Francisco Chinesta. Tape surfaces characterization with persistence images[J]. AIMS Materials Science, 2020, 7(4): 364-380. doi: 10.3934/matersci.2020.4.364

| [1] |
Chinesta F, Leygue A, Bognet B, et al. (2014) First steps towards an advanced simulation of composites manufacturing by automated tape placement. Int J Mater Form 7: 81-92. doi: 10.1007/s12289-012-1112-9

|
| [2] |
Chinesta F, Ammar A, Cueto E (2010) Recent advances and new challenges in the use of the Proper Generalized Decomposition for solving multidimensional models. Arch Comput Method Eng 17: 327-350. doi: 10.1007/s11831-010-9049-y
|
| [3] |
Chinesta F, Ladeveze P, Cueto E (2011) A short review in model order reduction based on Proper Generalized Decomposition. Arch Comput Method Eng 18: 395-404. doi: 10.1007/s11831-011-9064-7
|
| [4] | Chinesta F, Keunings R, Leygue A (2014) The Proper Generalized Decomposition for Advanced Numerical Simulations: A primer, Springer-Cham. |
| [5] | Chinesta F, Ladeveze P (2014) Separated Representations and PGD Based Model Reduction: Fundamentals and Applications, Springer-Verlag. |
| [6] |
Falcó A, Nouy A (2012) Proper generalized decomposition for nonlinear convex problems in tensor banach spaces. Numer Math 121: 503-530. doi: 10.1007/s00211-011-0437-5
|
| [7] |
Chinesta F, Leygue A, Bordeu F, et al. (2013) Parametric PGD based computational vademecum for efficient design, optimization and control. Arch Comput Method Eng 20: 31-59. doi: 10.1007/s11831-013-9080-x
|
| [8] |
Falcó A, Montés N, Chinesta F, et al. (2018) On the existence of a progressive variational vademecum based in the proper generalized decomposition for a class of elliptic parametrised problems. J Comput Appl Math 330: 1093-1107. doi: 10.1016/j.cam.2017.08.007
|
| [9] | Leon A, Argerich C, Barasinski A, et al. (2018) Effects of material and process parameters on in-situ consolidation. Int J Mater Form 12: 491-503. |
| [10] |
Argerich C, Ruben I, Leon A, et al. (2018) Tape surface characterization and classification in automated tape placement processability: Modeling and numerical analysis. AIMS Mater Sci 5: 870-888. doi: 10.3934/matersci.2018.5.870
|
| [11] | Rabadan R, Blumberg AJ (2020) Topological Data Analysis For Genomics And Evolution, Cambridge: Cambridge University Press. |
| [12] | Oudot SY (2010) Persistence theory: From quiver representation to data analysis, Mathematical Surveys and Monographs, American Mathematical Society, 209. |
| [13] | Chazal F, Michel B (2017) An introduction to topological data analysis: fundamental and practical aspects for data scientists. arXiv 1710.04019. |
| [14] |
Carlsson G (2009) Topology and data. Bull Amer Math Soc 46: 255-308. doi: 10.1090/S0273-0979-09-01249-X
|
| [15] |
Leon A, Barasinski A, Nadal E, et al. (2015) High-resolution thermal analysis at thermoplastic pre-impregnated composite interfaces. Compos Interface 22: 767-777. doi: 10.1080/09276440.2015.1060734
|
| [16] |
Leon A, Barasinski A, Chinesta F (2017) Microstructural analysis of pre-impreganted tapes consolidation. Int J Mater Form 10: 369-378. doi: 10.1007/s12289-016-1285-8
|
| [17] |
Yang F, Pitchumani R (2001) A fractal cantor set based description of interlaminar contact evolution during thermoplastic composites processing. J Mater Sci 36: 4661-4671. doi: 10.1023/A:1017950215945
|
| [18] |
Levy A, Heider D, Tierney J, et al. (2014) Inter-layer thermal contact resistance evolution with the degree of intimate contact in the processing of thermoplastic composite laminates. J Compos Mater 48: 491-503. doi: 10.1177/0021998313476318
|
| [19] | Krishnapriyan AS, Haranczyk M, Morozov D (2020) Robust topological descriptors for machine learning prediction of guest adsorption in nanoporous materials. arXiv 2001.05972. |
| [20] | Carlsson G, Zomorodian A, Colling A, et al. (2004) Persistence barcodes for shapes. Avaliable from: http://dx.doi.org/10.2312/SGP/SGP04/127-138. |
| [21] | Saul N, Tralie C (2019) Scikit-TDA: topological data analysis for python. |
| [22] | Adams H, Chepushtanova S, Kirby M, et al. (2017) Persistence images: A stable vector representation of persistent homology. J Mach Learn Res 18: 218-252. |
| [23] | Pedregosa F, Varoquaux G, Gramfort A, et al. (2011) Scikit-learn: Machine learning in python. arXiv1201.0490v4. |
| [24] |
Argerich C, Ruben I, Leon A, et al. (2019) Code2Vect: An efficient heterogenous data classifier and nonlinear regression technique. CR Mecanique 347: 754-761. doi: 10.1016/j.crme.2019.11.002
|
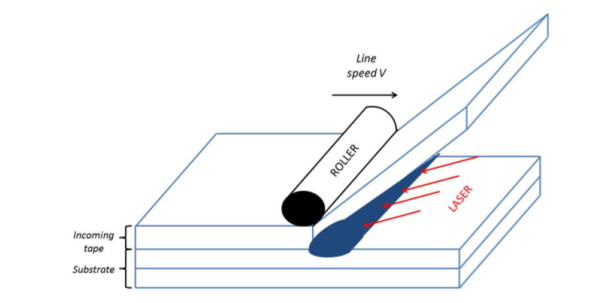
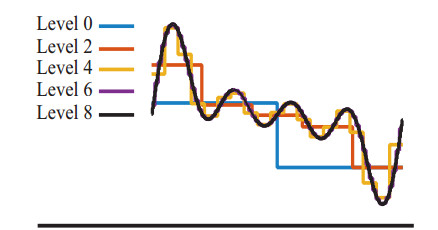
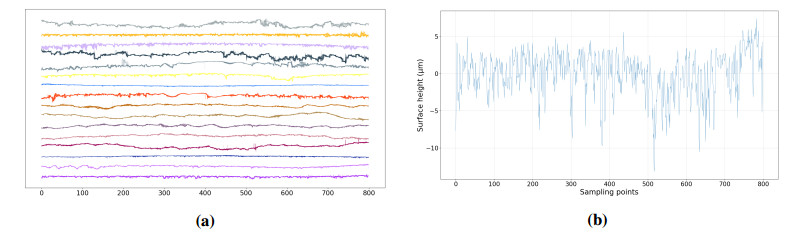
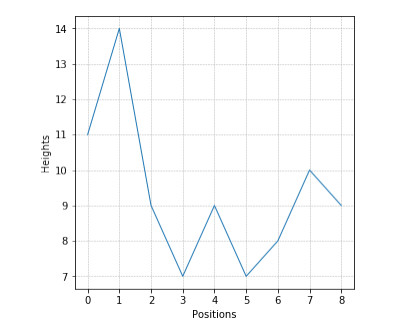
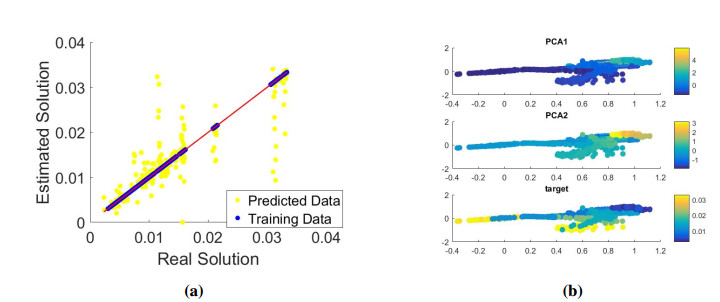
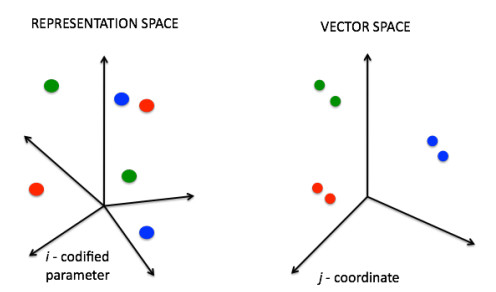
Figures(14)

Tarek Frahi, Clara Argerich, Minyoung Yun, Antonio Falco, Anais Barasinski, Francisco Chinesta. Tape surfaces characterization with persistence images[J]. AIMS Materials Science, 2020, 7(4): 364-380. doi: 10.3934/matersci.2020.4.364







 DownLoad:
DownLoad: