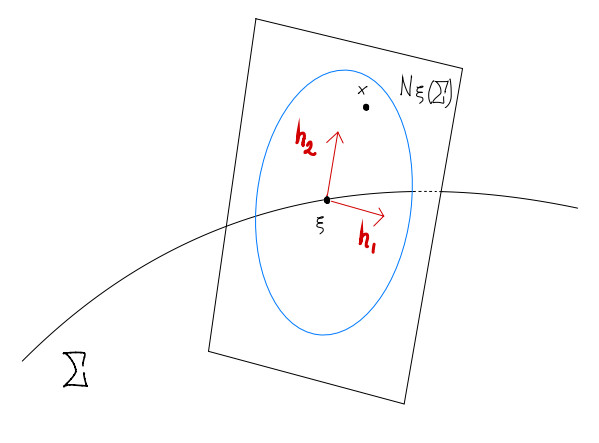
We have presented the construction of a theory of distributions (generalized functions) with a "thick submanifold", that is, a new theory of thick distributions on $ \mathbb{R}^n $ whose domain contains a smooth submanifold on which the test functions may be singular. We defined several operations, including "thick partial derivatives", and clarified their connection with their classical counterparts in Schwartz distribution theory. We also introduced and studied a number of special thick distributions, including new thick delta functions or, more generally, thick multilayer distributions along a submanifold.
Citation: Jiajia Ding, Jasson Vindas, Yunyun Yang. Distributions in spaces with thick submanifolds[J]. Electronic Research Archive, 2024, 32(12): 6660-6679. doi: 10.3934/era.2024311
We have presented the construction of a theory of distributions (generalized functions) with a "thick submanifold", that is, a new theory of thick distributions on $ \mathbb{R}^n $ whose domain contains a smooth submanifold on which the test functions may be singular. We defined several operations, including "thick partial derivatives", and clarified their connection with their classical counterparts in Schwartz distribution theory. We also introduced and studied a number of special thick distributions, including new thick delta functions or, more generally, thick multilayer distributions along a submanifold.

| [1] | R. Estrada, S. A. Fulling, Functions and distributions in spaces with thick points, Int. J. Appl. Math. Stat., 10 (2007), 25–37. |
| [2] |
Y. Yang, R. Estrada, Distributions in spaces with thick points, J. Math. Anal. Appl., 401 (2013), 821–835. https://doi.org/10.1016/j.jmaa.2012.12.045 doi: 10.1016/j.jmaa.2012.12.045

|
| [3] |
S. Antontsev, I. Kuznetsov, S. Sazhenkov, S. Shmarev, Strong solutions of a semilinear impulsive pseudoparabolic equation with an infinitesimal initial layer, J. Math. Anal. Appl., 530 (2024), 127751. https://doi.org/10.1016/j.jmaa.2023.127751 doi: 10.1016/j.jmaa.2023.127751
|
| [4] |
G. Schäfer, P. Jaranowski, Hamiltonian formulation of general relativity and post-newtonian dynamics of compact binaries, Living Rev. Relativ., 27 (2024), 2. https://doi.org/10.1007/s41114-024-00048-7 doi: 10.1007/s41114-024-00048-7
|
| [5] |
E. Le Boudec, C. Kasmi, N. Mora, F. Rachidi, E. Radici, M. Rubinstein, et al., The time-domain cartesian multipole expansion of electromagnetic fields, Sci. Rep., 14 (2024), 8084. https://doi.org/10.1038/s41598-024-58570-1 doi: 10.1038/s41598-024-58570-1
|
| [6] |
Y. Yang, Distributions in $\mathbb{R}^3$ with a thick curve, J. Math. Anal. Appl., 512 (2022), 126075. https://doi.org/10.1016/j.jmaa.2022.126075 doi: 10.1016/j.jmaa.2022.126075
|
| [7] |
B. J. Vakoc, R. M. Lanning, J. A. Tyrrell, T. P. Padera, L. A. Bartlett, T. Stylianopoulos, et al., Three-dimensional microscopy of the tumor microenvironment in vivo using optical frequency domain imaging, Nat. Med., 15 (2009), 1219–1223. https://doi.org/10.1038/nm.1971 doi: 10.1038/nm.1971
|
| [8] |
X. Zheng, G. Y. Koh, T. Jackson, A continuous model of angiogenesis: Initiation, extension, and maturation of new blood vessels modulated by vascular endothelial growth factor, angiopoietins, platelet-derived growth factor-B, and pericytes, Discrete Contin. Dyn. Syst.-Ser. B, 18 (2013), 1109–1154. https://doi.org/10.3934/dcdsb.2013.18.1109 doi: 10.3934/dcdsb.2013.18.1109
|
| [9] |
R. Estrada, J. Vindas, Y. Yang, The Fourier transform of thick distributions, Anal. Appl., 19 (2021), 621–646. https://doi.org/10.1142/S0219530520500074 doi: 10.1142/S0219530520500074
|
| [10] |
F. Brackx, F. Sommen, J. Vindas, On the radial derivative of the delta distribution, Complex Anal. Oper. Theory, 11 (2017), 1035–1057. https://doi.org/10.1007/s11785-017-0638-8 doi: 10.1007/s11785-017-0638-8
|
| [11] | V. Guillemin, A. Pollack, Differential Topology, Prentice-Hall, New Jersey, 1974. |
| [12] | R. Estrada, R. P. Kanwal, A Distributional Approach to Asymptotics: Theory and Applications, Birkhäuser, Boston, 2002. https://doi.org/10.1007/978-0-8176-8130-2 |
| [13] | G. B. Folland, Real Analysis: Modern Techniques and Their Applications, John Wiley & Sons, New York, 1984. |
| [14] | F. Farassat, Introduction to Generalized Functions with Applications in Aerodynamics and Aeroacoustics, 1994. Available from: https://ntrs.nasa.gov/citations/19940029887. |
| [15] |
R. Estrada, R. P. Kanwal, Distributional analysis for discontinuous fields, J. Math. Anal. Appl., 105 (1985), 478–490. https://doi.org/10.1016/0022-247X(85)90063-0 doi: 10.1016/0022-247X(85)90063-0
|
| [16] | F. Treves, Topological Vector Spaces, Distributions and Kernels, Academic Press, San Diego, 1967. |
| [17] | R. Meise, D. Vogt, Introduction to Functional Analysis, Oxford University Press, Oxford, 1997. https://doi.org/10.1093/oso/9780198514855.001.0001 |
| [18] | P. Domański, Classical PLS-spaces: spaces of distributions, real analytic functions and their relatives, Banach Center Publ., 64 (2004), 51–70. |
| [19] | L. Narici, E. Beckenstein, Topological Vector Spaces, $2^{nd}$ Edition, CRC Press, New York, 2010. https://doi.org/10.1201/9781584888673 |
| [20] |
R. Estrada, J. Vindas, A generalization of the banach-steinhaus theorem for finite part limits, Bull. Malays. Math. Sci. Soc., 40 (2017), 907–918. https://doi.org/10.1007/s40840-017-0450-7 doi: 10.1007/s40840-017-0450-7
|
| [21] | R. P. Kanwal, Generalized Functions: Theory and Applications, Birkhäuser, Boston, 2004. https://doi.org/10.1007/978-0-8176-8174-6 |
Figures(1)
Jiajia Ding, Jasson Vindas, Yunyun Yang. Distributions in spaces with thick submanifolds[J]. Electronic Research Archive, 2024, 32(12): 6660-6679. doi: 10.3934/era.2024311







 DownLoad:
DownLoad: