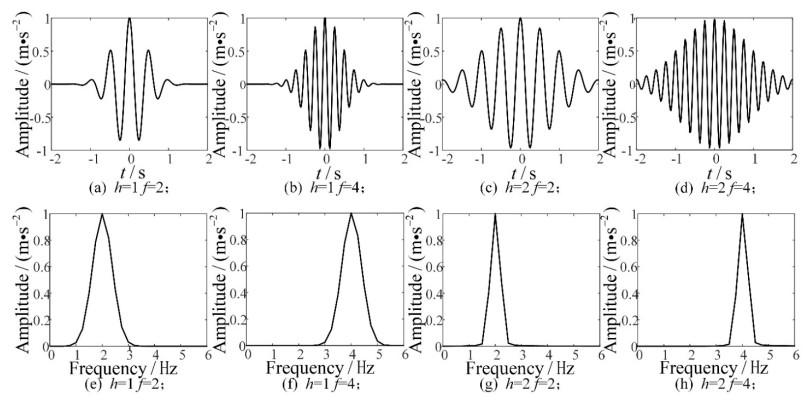
In response to the challenge of noise filtering for the impulsive vibration signals of rolling bearings, this paper presented a novel filtering method based on the improved Morlet wavelet, which has clear physical meaning and is more conducive to parameter optimization through employing Gaussian waveform width to replace the traditional Morlet wavelet shape factor. Simultaneously, the marine predation algorithm was employed and the minimum Shannon entropy was used as the parameter optimization index while optimizing the shape width and center frequency of the improved Morlet wavelet. The vibration waveform of the rolling bearing was matched perfectly by using the optimized Morlet wave. Shannon entropy was used as the evaluation index of noise filtering, and the quantitative analysis of noise filtering was realized. Through experimental validation, this method was proved to be effective in noise elimination for rolling bearing. It is significance to preprocessing of vibration signal, feature extraction and fault recognition of rolling bearing.
Citation: Yu Chen, Qingyang Meng, Zhibo Liu, Zhuanzhe Zhao, Yongming Liu, Zhijian Tu, Haoran Zhu. Research on filtering method of rolling bearing vibration signal based on improved Morlet wavelet[J]. Electronic Research Archive, 2024, 32(1): 241-262. doi: 10.3934/era.2024012
In response to the challenge of noise filtering for the impulsive vibration signals of rolling bearings, this paper presented a novel filtering method based on the improved Morlet wavelet, which has clear physical meaning and is more conducive to parameter optimization through employing Gaussian waveform width to replace the traditional Morlet wavelet shape factor. Simultaneously, the marine predation algorithm was employed and the minimum Shannon entropy was used as the parameter optimization index while optimizing the shape width and center frequency of the improved Morlet wavelet. The vibration waveform of the rolling bearing was matched perfectly by using the optimized Morlet wave. Shannon entropy was used as the evaluation index of noise filtering, and the quantitative analysis of noise filtering was realized. Through experimental validation, this method was proved to be effective in noise elimination for rolling bearing. It is significance to preprocessing of vibration signal, feature extraction and fault recognition of rolling bearing.

| [1] |
M. Cerrada, R. V. Sanchez, C. Li, F. Pacheco, D. Cabrera, J. V. de Oliveira, et al., A review on data-driven fault severity assessment in rolling bearings, Mech. Syst. Signal Process., 99 (2018), 169–196. https://doi.org/10.1016/j.ymssp.2017.06.012 doi: 10.1016/j.ymssp.2017.06.012

|
| [2] |
M. Xia, T. Li, L. Xu, L. Liu, C. W. de Silva, Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks, IEEE/ASME Trans. Mechatron., 23 (2017), 101–110. https://doi.org/10.1109/TMECH.2017.2728371 doi: 10.1109/TMECH.2017.2728371
|
| [3] |
M. Liang, K. Zhou, Probabilistic bearing fault diagnosis using Gaussian process with tailored feature extraction, Int. J. Adv. Manuf. Technol., 119 (2022), 2059–2076. https://doi.org/10.1007/s00170-021-08392-6 doi: 10.1007/s00170-021-08392-6
|
| [4] |
W. Yang, R. Court, Experimental study on the optimum time for conducting bearing maintenance, Measurement, 46 (2013), 2781–2791. https://doi.org/10.1016/j.measurement.2013.04.016 doi: 10.1016/j.measurement.2013.04.016
|
| [5] |
C. Mongia, D. Goyal, S. Sehgal, Vibration response-based condition monitoring and fault diagnosis of rotary machinery, Mater. Today Proc., 50 (2022), 679–683. https://doi.org/10.1016/j.matpr.2021.04.395 doi: 10.1016/j.matpr.2021.04.395
|
| [6] |
W. Ahmad, S. A. Khan, J. M. Kim, A hybrid prognostics technique for rolling element bearings using adaptive predictive models, IEEE Trans. Ind. Electron., 65 (2017), 1577–1584. https://doi.org/10.1109/TIE.2017.2733487 doi: 10.1109/TIE.2017.2733487
|
| [7] |
M. A. Ugwiri, M. Carratú, V. Paciello, C. Liguori, Benefits of enhanced techniques combining negentropy, spectral correlation and kurtogram for bearing fault diagnosis, Measurement, 185 (2021), 110013. https://doi.org/10.1016/j.measurement.2021.110013 doi: 10.1016/j.measurement.2021.110013
|
| [8] |
S. Gawde, S. Patil, S. Kumar, P. Kamat, K. Kotecha, A. Abraham, Multi-fault diagnosis of Industrial Rotating Machines using Data-driven approach: a review of two decades of research, Eng. Appl. Artif. Intell., 123 (2023), 106139. https://doi.org/10.1016/j.engappai.2023.106139 doi: 10.1016/j.engappai.2023.106139
|
| [9] |
Y. Xu, Z. Li, S. Wang, W. Li, T. Sarkodie-Gyan, S. Feng, A hybrid deep-learning model for fault diagnosis of rolling bearings, Measurement, 169 (2021), 108502. https://doi.org/10.1016/j.measurement.2020.108502 doi: 10.1016/j.measurement.2020.108502
|
| [10] |
H. Shao, H. Jiang, Y. Lin, X. Li, A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders, Mech. Syst. Signal Process., 102 (2018), 278–297. https://doi.org/10.1016/j.ymssp.2017.09.026 doi: 10.1016/j.ymssp.2017.09.026
|
| [11] |
L. Wen, X. Li, L. Gao, Y. Zhang, A new convolutional neural network-based data-driven fault diagnosis method, IEEE Trans. Ind. Electron., 65 (2018), 5990–5998. https://doi.org/10.1109/TIE.2017.2774777 doi: 10.1109/TIE.2017.2774777
|
| [12] |
M. Gan, C. Wang, C. Zhu, Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings, Mech. Syst. Signal Process., 72–73 (2016), 92–104. https://doi.org/10.1016/j.ymssp.2015.11.014 doi: 10.1016/j.ymssp.2015.11.014
|
| [13] |
X. F. Xu, S. T. Hu, P. M. Shi, H. S. Shao, R. X. Li, Z. Li, Natural phase space reconstruction-based broad learning system for short-term wind speed prediction: case studies of an offshore wind farm, Energy, 262 (2023), 125342. https://doi.org/10.1016/j.energy.2022.125342 doi: 10.1016/j.energy.2022.125342
|
| [14] |
X. F. Xu, S. T. Hu, H. S. Shao, P. M. Shi, R. X. Li, D. G. Li, A spatio-temporal forecasting model using optimally weighted graph convolutional network and gated recurrent unit for wind speed of different sites distributed in an offshore wind farm, Energy, 284 (2023), 128565. https://doi.org/10.1016/j.energy.2023.128565 doi: 10.1016/j.energy.2023.128565
|
| [15] |
L. J. Zhang, J. W. Xu, J. H. Yang, D. B. Yang, D. D. Wang, Multiscale morphology analysis and its application of fault diagnosis, Mech. Syst. Signal Process., 22 (2008), 597–610. https://doi.org/10.1016/j.ymssp.2007.09.010 doi: 10.1016/j.ymssp.2007.09.010
|
| [16] |
Z. Li, S. Cai, X. Li, S. Shao, X. Y. Yang, Fault diagnosis of Rolling Bearing for Motor Based on LSTM-EEMD and Genetic Optimization, J. Phys.: Conf. Ser., 2549 (2023), 012025. https://doi.org/10.1088/1742-6596/2549/1/012025 doi: 10.1088/1742-6596/2549/1/012025
|
| [17] |
K. Zhou, J. Tang, A wavelet neural network informed by time-domain signal preprocessing for bearing remaining useful life prediction, Appl. Math. Modell., 122 (2023), 220–241. https://doi.org/10.1016/j.apm.2023.05.042 doi: 10.1016/j.apm.2023.05.042
|
| [18] |
Q. Miao, C. Tang, W. Liang, M. Pecht, Health assessment of cooling fan bearings using wavelet-based filtering, Sensors, 13 (2013), 274–291. https://doi.org/10.3390/s130100274 doi: 10.3390/s130100274
|
| [19] |
K. Belaid, A. Miloudi, H. Bournine, The processing of resonances excited by gear faults using continuous wavelet transform with adaptive complex Morlet wavelet and sparsity measurement, Measurement, 180 (2021), 109576. https://doi.org/10.1016/j.measurement.2021.109576 doi: 10.1016/j.measurement.2021.109576
|
| [20] |
P. Liang, W. Wang, X. Yuan, S. Liu, L. Zhang, Y. Cheng, Intelligent fault diagnosis of rolling bearing based on wavelet transform and improved ResNet under noisy labels and environment, Eng. Appl. Artif. Intell., 115 (2022), 105269. https://doi.org/10.1016/j.engappai.2022.105269 doi: 10.1016/j.engappai.2022.105269
|
| [21] |
J. Ma, H. Li, Y. Chen, J. Wang, Z. Zou, Application of VMD and dynamic wavelet noise reduction techniques in rolling bearing fault diagnosis, J. Phys.: Conf. Ser., 2528 (2023), 012048. https://doi.org/10.1088/1742-6596/2528/1/012048 doi: 10.1088/1742-6596/2528/1/012048
|
| [22] |
G. Naima, H. A. Elias, S. Salah, An improved fast kurtogram based on an optimal wavelet coefficient for wind turbine gear fault detection, J. Electr. Eng. Technol., 17 (2022), 1335–1346. https://doi.org/10.1007/s42835-021-00937-9 doi: 10.1007/s42835-021-00937-9
|
| [23] |
L. Liang, G. H. Xu, C. G. Hou, Continuous wavelet transform denoising method based on singular value decomposition, J. Xi'an Jiaotong Univ., 38 (2004), 904–908. https://doi.org/10.3321/j.issn:0253-987X.2004.09.006 doi: 10.3321/j.issn:0253-987X.2004.09.006
|
| [24] |
J. Lin, L. S. Qu, Feature extraction based on Morlet wavelet and its application form echanical fault diagnosis, J. Sound Vib., 234 (2000), 135–148. https://doi.org/10.1006/jsvi.2000.2864 doi: 10.1006/jsvi.2000.2864
|
| [25] |
W. Zhang, M. P. Jia, L. Zhu, An adaptive Morlet wavelet filter method and its application in detecting early fault feature of ball bearings (in Chinese), J. Southeast Univ. (Nat. Sci. Ed.), 46 (2016), 457–463. https://doi.org/10.3969/j.issn.1001-0505.2016.03.001 doi: 10.3969/j.issn.1001-0505.2016.03.001
|
| [26] |
P. W. Tse, D. Wang, The automatic selection of an optimal wavelet filter and its enhancement by the new Sparsogram for bearing fault detection: part 2 of the two related manuscripts that have a joint title as "two automatic vibration-based fault diagnostic methods using the novel sparsity measurement-Parts 1 and 2", Mech. Syst. Signal Process., 40 (2013), 520–544. https://doi.org/10.1016/j.ymssp.2013.05.018 doi: 10.1016/j.ymssp.2013.05.018
|
| [27] |
Y. Jiang, B. Tang, Y. Qin, W. Liu, Feature extraction method of wind turbine based on adaptive Morlet wavelet and SVD, Renewable Energy, 36 (2011), 2146–2153. https://doi.org/10.1016/j.renene.2011.01.009 doi: 10.1016/j.renene.2011.01.009
|
| [28] |
M. Behzad, A. Kiakojouri, H. A. Arghand, A. Davoodabadi, Inaccessible rolling bearing diagnosis using a novel criterion for Morlet wavelet optimization, J. Vib. Control, 28 (2022), 1239–1250. https://doi.org/10.1177/1077546321989503 doi: 10.1177/1077546321989503
|
| [29] |
X. Gu, S. Yang, Y. Liu, F. Deng, B. Ren, Compound faults detection of the rolling element bearing based on the optimal complex Morlet wavelet filter, Proc. Inst. Mech. Eng., Part C: J. Mech. Eng. Sci., 232 (2018), 1786–1801. https://doi.org/10.1177/0954406217710673 doi: 10.1177/0954406217710673
|
| [30] |
Y. Zhang, B. P. Tang, Z. R. Liu, R. X. Chen, An adaptive demodulation approach for bearing fault detection based on adaptive wavelet filtering and spectral subtraction, Meas. Sci. Technol., 27 (2015), 025001. https://doi.org/10.1088/0957-0233/27/2/025001 doi: 10.1088/0957-0233/27/2/025001
|
| [31] |
W. Su, F. Wang, H. Zhu, Z. Zhang, Z. Guo, Rolling element bearing faults diagnosis based on optimal Morlet wavelet filter and autocorrelation enhancement, Mech. Syst. Signal Process., 24 (2010), 1458–1472. https://doi.org/10.1016/j.ymssp.2009.11.011 doi: 10.1016/j.ymssp.2009.11.011
|
| [32] |
X. Han, J. Xu, S. Song, J. Zhou, Crack fault diagnosis of vibration exciter rolling bearing based on genetic algorithm–optimized Morlet wavelet filter and empirical mode decomposition, Int. J. Distrib. Sens. Netw., 18 (2022). https://doi.org/10.1177/15501329221114566 doi: 10.1177/15501329221114566
|
| [33] |
M. X. Cohen, A better way to define and describe Morlet wavelets for time-frequency analysis, Neuroimage, 199 (2019), 81–86. https://doi.org/10.1016/j.neuroimage.2019.05.048 doi: 10.1016/j.neuroimage.2019.05.048
|
| [34] |
A. Dey, S. Bhattacharyya, S. Dey, D. Konar, J. Platos, V. Snasel, et al., A review of quantum-inspired metaheuristic algorithms for automatic clustering, Mathematics, 11 (2023), 2018. https://doi.org/10.3390/math11092018 doi: 10.3390/math11092018
|
| [35] |
A. Faramarzi, M. Heidarinejad, S. Mirjalili, A. H. Gandomi, Marine Predators Algorithm: a nature-inspired metaheuristic, Expert Syst. Appl., 152 (2020), 113377. https://doi.org/10.1016/j.eswa.2020.113377 doi: 10.1016/j.eswa.2020.113377
|
| [36] | S. Devendiran, K. Manivannan, Vibration based condition monitoring and fault diagnosis technologies for bearing and gear components a review, Int. J. Appl. Eng. Res., 11 (2016), 3966–3975. |
| [37] |
N. G. Nikolaou, I. A. Antoniadis, Demodulation of vibration signals generated by defects in rolling element bearings using complex shifted Morlet wavelets, Mech. Syst. Signal Process., 16 (2002), 677–694. https://doi.org/10.1006/mssp.2001.1459 doi: 10.1006/mssp.2001.1459
|
| [38] |
P. K. Kankar, S. C. Sharma, S. P. Harsha, Rolling element bearing fault diagnosis using wavelet transform, Neurocomputing, 74 (2011), 1638–1645. https://doi.org/10.1016/j.neucom.2011.01.021 doi: 10.1016/j.neucom.2011.01.021
|
| [39] |
R. Dubey, V. Rajpoot, A. Chaturvedi, A. Dixit, S. Maheshwari, Ball-bearing fault classification using comparative analysis of wavelet coefficient based on entropy measurement, IETE J. Res., 25 (2022). https://doi.org/10.1080/03772063.2022.2142685 doi: 10.1080/03772063.2022.2142685
|
| [40] |
S. Dong, X. Xu, R. Chen, Application of fuzzy C-means method and classification model of optimized K-nearest neighbor for fault diagnosis of bearing, J. Braz. Soc. Mech. Sci. Eng., 38 (2016), 2255–2263. https://doi.org/10.1007/s40430-015-0455-9 doi: 10.1007/s40430-015-0455-9
|
| [41] |
B. Wang, Y. Lei, N. Li, N. Li, A hybrid prognostics approach for estimating remaining useful life of rolling element bearings, IEEE Trans. Reliab., 69 (2018), 401–412. https://doi.org/10.1109/TR.2018.2882682 doi: 10.1109/TR.2018.2882682
|
| [42] |
T. H. Loutas, D. Roulias, G. Georgoulas, Remaining useful life estimation in rolling bearings utilizing data-driven probabilistic e-support vectors regression, IEEE Trans. Reliab., 62 (2013), 821–832. https://doi.org/10.1109/TR.2013.2285318 doi: 10.1109/TR.2013.2285318
|
| [43] |
X. F. Xu, B. Li, Z. J. Qiao, P. M. Shi, H. S. Shao, R. X. Li, Caputo-Fabrizio fractional order derivative stochastic resonance enhanced by ADOF and its application in fault diagnosis of wind turbine drivetrain, Renewable Energy, 219 (2023), 119398. https://doi.org/10.1016/j.renene.2023.119398 doi: 10.1016/j.renene.2023.119398
|
| [44] |
W. A. Smith, R. B. Randall, Rolling element bearing diagnostics using the Case Western Reserve University data: a benchmark study, Mech. Syst. Signal Process., 64–65 (2015), 100–131. https://doi.org/10.1016/j.ymssp.2015.04.021 doi: 10.1016/j.ymssp.2015.04.021
|








Figures(9) / Tables(6)
Yu Chen, Qingyang Meng, Zhibo Liu, Zhuanzhe Zhao, Yongming Liu, Zhijian Tu, Haoran Zhu. Research on filtering method of rolling bearing vibration signal based on improved Morlet wavelet[J]. Electronic Research Archive, 2024, 32(1): 241-262. doi: 10.3934/era.2024012







 DownLoad:
DownLoad: