Citation: Jerome Mungwe, Stefano Mandelli, Emanuela Colombo. Community pico and micro hydropower for rural electrification: experiences from the mountain regions of Cameroon[J]. AIMS Energy, 2016, 4(1): 190-205. doi: 10.3934/energy.2016.1.190

| [1] | IEA. World Energy Outlook 2014 (2014) OECD Publishing. |
| [2] | Mandelli S, Mereu R (2013) Distributed Generation for Access to Electricity: “Off-Main-Grid” Systems from Home-Based to Microgrid. In: Colombo E, Bologna S, Masera D, editors. Renewable Energy for Unleashing Sustainable Development: Blending techinology, Finance and policy in low and middle income eonomies, Springer International Publishing, 75-97. |
| [3] | ESMAP (2007) Technical and Economic Assessment of Off-grid, Mini-grid and Grid Electrification Technologies. Washington DC. |
| [4] | USAID, ARE (2011) Hybrid Mini-Grids for Rural Electrification: Lessons Learned. |
| [5] | World Bank (2008) REToolkit : A Resource for Renewable Energy Development. |
| [6] |
Schnitzer D, Lounsbury DS, Carvallo JP, et al. (2014) Microgrids for Rural Electrification : A critical review of best practices based on seven case studies. Availabe from: http://120.52.72.43/www.ourenergypolicy.org/c3pr90ntcsf0/wp-content/uploads/2014/02/MicrogridsReportFINAL_low.pdf |
| [7] |
Mandelli S, Barbieri J, Mattarolo L, et al. (2014) Sustainable energy in Africa: A comprehensive data and policies review. Renew Sustain Energy Rev 37: 656-686. doi: 10.1016/j.rser.2014.05.069

|
| [8] | IEA (2004) World Energy Outlook 2004. OECD Publishing. |
| [9] | UNDP (2010) Human Development Report 2010: 20th Anniversary Edition. New York: Palgrave Macmillan. |
| [10] | Institut National de la Statistique du Cameroun (2011) Annuaire statistique du Cameroun. |
| [11] | Liu H, Masera D, Esser L (2013) World Small Hydropower Development Report 2013. United Nations Industrial Development Organization; International Center on Small Hydro Power. Available from: www.smallhydroworld.org. |
| [12] | Lighting Africa (2012) Lighting Africa Policy Report: Ethiopia,Policy Report Note. |
| [13] | European Small Hydropower Association (2004) Guide on How to Develop a Small Hydropower Plant. |
| [14] |
Murni S, Whale J, Urmee T, et al. (2012) The role of micro hydro power systems in remote rural electrification: A case study in the Bawan Valley, Borneo. Procedia Eng 49: 189-196. doi: 10.1016/j.proeng.2012.10.127
|
| [15] | ESMAP (2000) Mini Grid Manual. Washington DC. |
| [16] | Williams AA, Simpson R (2009) Pico hydro – Reducing technical risks for rural electrification. Renew Energy 34: 1986-1991. |
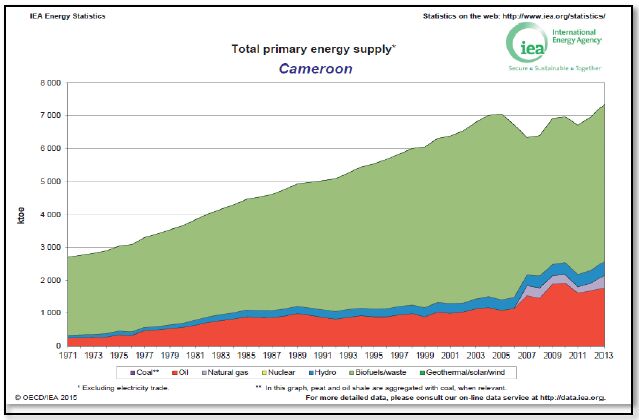
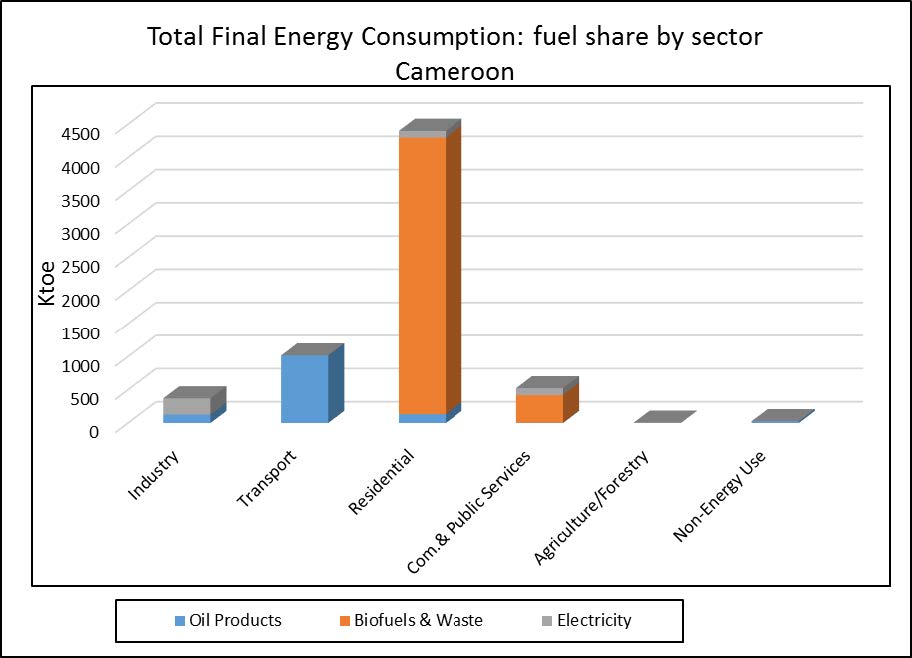
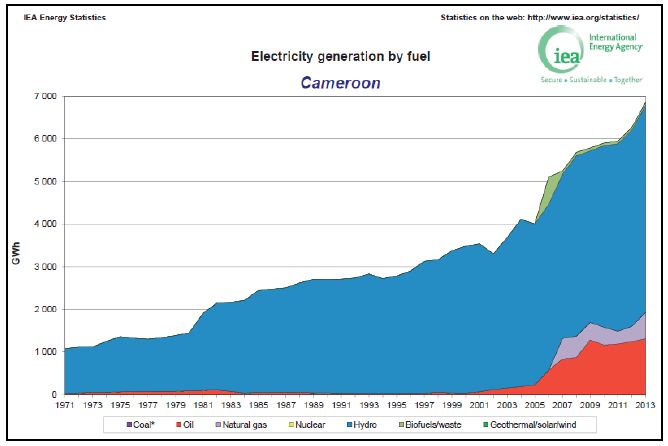
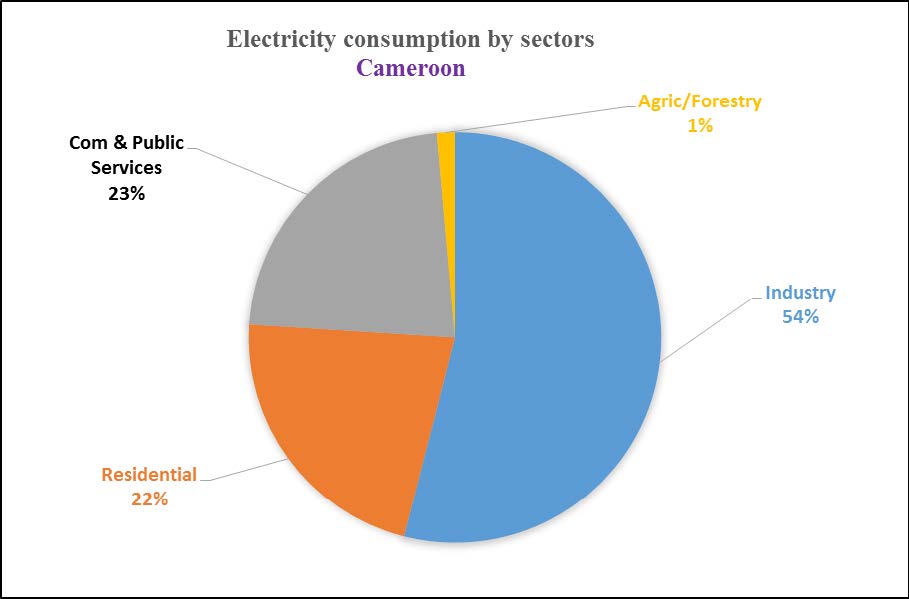

Figures(6) / Tables(1)

Jerome Mungwe, Stefano Mandelli, Emanuela Colombo. Community pico and micro hydropower for rural electrification: experiences from the mountain regions of Cameroon[J]. AIMS Energy, 2016, 4(1): 190-205. doi: 10.3934/energy.2016.1.190







 DownLoad:
DownLoad: