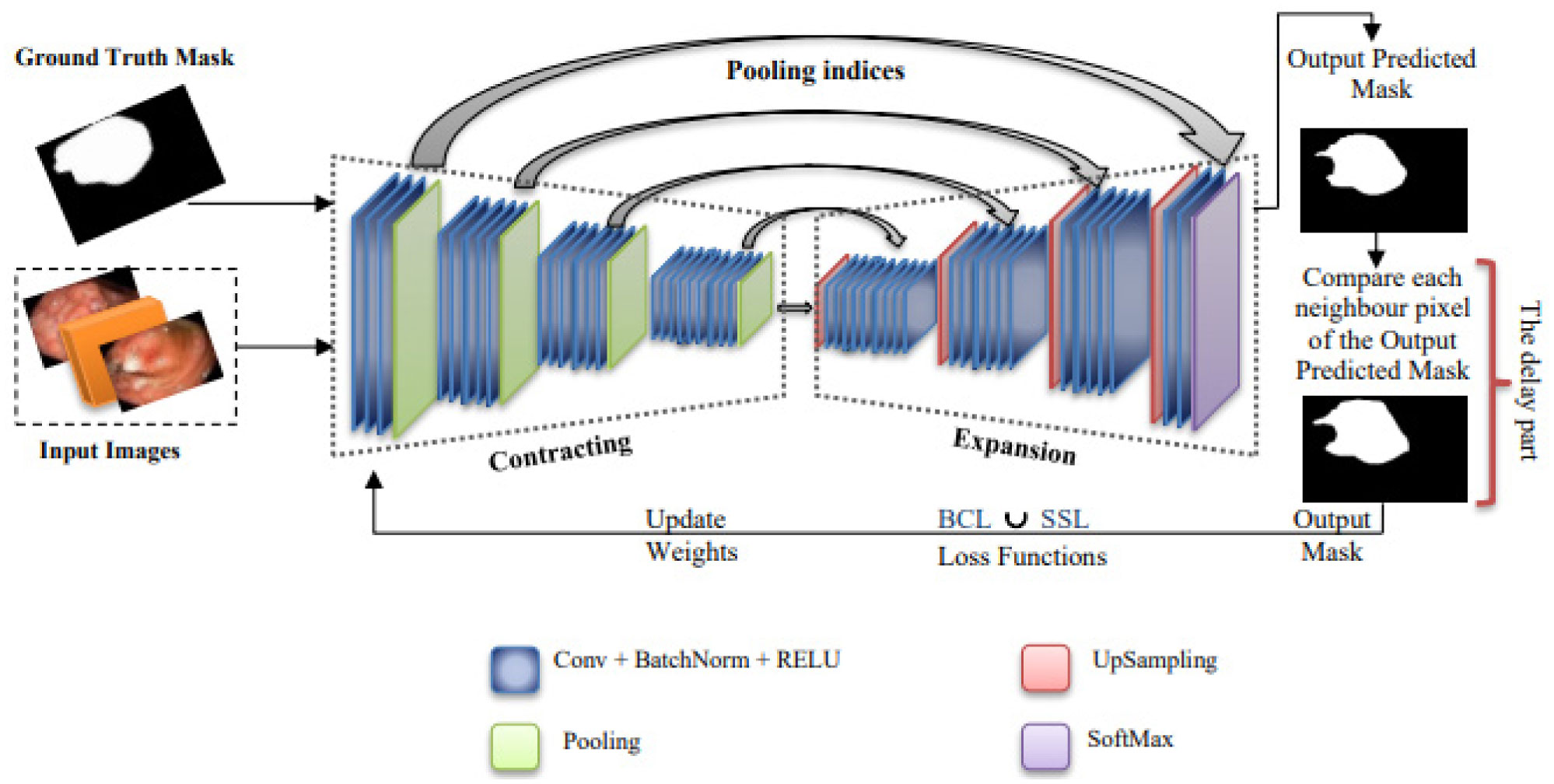
Currently, the gastric cancer is the source of the high mortality rate where it is diagnoses from the stomach and esophagus tests. To this end, the whole of studies in the analysis of cancer are built on AI (artificial intelligence) to develop the analysis accuracy and decrease the danger of death. Mostly, deep learning methods in images processing has made remarkable advancement. In this paper, we present a method for detection, recognition and segmentation of gastric cancer in endoscopic images. To this end, we propose a deep learning method named GAS-Net to detect and recognize gastric cancer from endoscopic images. Our method comprises at the beginning a preprocessing step for images to make all images in the same standard. After that, the GAS-Net method is based an entire architecture to form the network. A union between two loss functions is applied in order to adjust the pixel distribution of normal/abnormal areas. GAS-Net achieved excellent results in recognizing lesions on two datasets annotated by a team of expert from several disciplines (Dataset1, is a dataset of stomach cancer images of anonymous patients that was approved from a private medical-hospital clinic, Dataset2, is a publicly available and open dataset named HyperKvasir
Citation: Lamia Fatiha KAZI TANI, Mohammed Yassine KAZI TANI, Benamar KADRI. Gas-Net: A deep neural network for gastric tumor semantic segmentation[J]. AIMS Bioengineering, 2022, 9(3): 266-282. doi: 10.3934/bioeng.2022018
Currently, the gastric cancer is the source of the high mortality rate where it is diagnoses from the stomach and esophagus tests. To this end, the whole of studies in the analysis of cancer are built on AI (artificial intelligence) to develop the analysis accuracy and decrease the danger of death. Mostly, deep learning methods in images processing has made remarkable advancement. In this paper, we present a method for detection, recognition and segmentation of gastric cancer in endoscopic images. To this end, we propose a deep learning method named GAS-Net to detect and recognize gastric cancer from endoscopic images. Our method comprises at the beginning a preprocessing step for images to make all images in the same standard. After that, the GAS-Net method is based an entire architecture to form the network. A union between two loss functions is applied in order to adjust the pixel distribution of normal/abnormal areas. GAS-Net achieved excellent results in recognizing lesions on two datasets annotated by a team of expert from several disciplines (Dataset1, is a dataset of stomach cancer images of anonymous patients that was approved from a private medical-hospital clinic, Dataset2, is a publicly available and open dataset named HyperKvasir

| [1] |
Borgli H, de Lange T, Eskeland SL, et al. (2020) HyperKvasir, a comprehensive multi-class image and video dataset for gastrointestinal endoscopy. Sci Data 7: 283. https://doi.org/10.1038/s41597-020-00622-y 
|
| [2] |
Cutler J, Grannell A, Rae R (2021) Size-susceptibility of Cornu aspersum exposed to the malacopathogenic nematodes Phasmarhabditis hermaphrodita and P. californica. Biocontrol Sci Technol 31: 1149-1160. https://doi.org/10.1080/09583157.2021.1929072
|
| [3] | Kitagawa Y, Wada N (2021) Application of AI in Endoscopic Surgical Operations. Surgery and Operating Room Innovation . Singapore: Springer 71-77. https://doi.org/10.1007/978-981-15-8979-9_8 |
| [4] |
Jia Y, Shelhamer E, Donahue J, et al. (2014) Caffe: Convolutional architecture for fast feature embedding. Proceedings of the 22nd ACM international conference on Multimedia MM14: 675-678. https://doi.org/10.1145/2647868.2654889
|
| [5] |
Hirasawa T, Aoyama K, Tanimoto T, et al. (2018) Application of artificial intelligence using a convolutional neural network for detecting gastric cancer in endoscopic images. Gastric Cancer 21: 653-660. https://doi.org/10.1007/s10120-018-0793-2
|
| [6] |
Kim JH, Yoon HJ (2020) Lesion-based convolutional neural network in diagnosis of early gastric cancer. Clin Endosc 53: 127-131. https://doi.org/10.5946/ce.2020.046
|
| [7] | Sakai Y, Takemoto S, Hori K, et al. (2018) Automatic detection of early gastric cancer in endoscopic images using a transferring convolutional neural network. In 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE : 4138-4141. https://doi.org/10.1109/EMBC.2018.8513274 |
| [8] |
de Groof AJ, Struyvenberg MR, van der Putten J, et al. (2020) Deep-learning system detects neoplasia in patients with barrett's esophagus with higher accuracy than endoscopists in a multistep training and validation study with benchmarking. Gastroenterology 158: 915-929. e4. https://doi.org/10.1053/j.gastro.2019.11.030
|
| [9] | Haque A, Lyu B (2018) Deep learning based tumor type classification using gene expression data. Proceedings of the 2018 ACM international conference on bioinformatics, computational biology, and health informatics 18: 89-96. https://doi.org/10.1145/3233547.3233588 |
| [10] |
Wang P, Xiao X, Glissen Brown JR, et al. (2018) Development and validation of a deep-learning algorithm for the detection of polyps during colonoscopy. Nat Biomed Eng 2: 741-748. https://doi.org/10.1038/s41551-018-0301-3
|
| [11] |
Arsalan M, Owais M, Mahmood T, et al. (2020) Artificial intelligence-based diagnosis of cardiac and related diseases. J Clin Med 9: 871. https://www.mdpi.com/2077-0383/9/3/871
|
| [12] | Nopour R, Shanbehzadeh M, Kazemi-Arpanahi H (2021) Developing a clinical decision support system based on the fuzzy logic and decision tree to predict colorectal cancer. Med J Islam Repub Iran 35: 44. https://doi.org/10.47176/mjiri.35.44 |
| [13] | Darrell T, Long J, Shelhamer E (2016) Fully convolutional networks for semantic segmentation. IEEE transactions on pattern analysis and machine intelligence 39: 640-651. https://doi.org/10.1109/TPAMI.2016.2572683 |
| [14] |
Ghomari A, Kazi Tani MY, Lablack A, et al. (2017) OVIS: ontology video surveillance indexing and retrieval system. Int J Multimed Info Retr 6: 295-316. https://doi.org/10.1007/s13735-017-0133-z
|
| [15] | He K, Gkioxari G, Dollár P, et al. (2017) Mask r-cnn. In Proceedings of the IEEE international conference on computer vision. IEEE : 2961-2969. https://doi.org/10.48550/arXiv.1703.06870 |
| [16] | Tani LFK, Ghomari A, Tani MYK (2019) A semi-automatic soccer video annotation system based on Ontology paradigm. 2019 10th International Conference on Information and Communication Systems. ICICS: : 88-93. https://doi.org/0.1109/IACS.2019.8809161 |
| [17] | KAZI TANI LF Conception and Implementation of a Semi-Automatic Tool Dedicated To The Analysis And Research Of Web Video Content. Doctoral Thesis, Oran, Algeria, 2020. Available from: https://theses.univ-oran1.dz/document/TH5141.pdf |
| [18] |
Tani LFK, Ghomari A, Tani MYK (2019) Events recognition for a semi-automatic annotation of soccer videos: a study based deep learning. The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences 42: 135-141. https://doi.org/10.5194/isprs-archives-XLII-2-W16-135-2019
|
| [19] |
Sun JY, Lee SW, Kang MC, et al. (2018) A novel gastric ulcer differentiation system using convolutional neural networks. 2018 IEEE 31st International Symposium on Computer-Based Medical Systems (CBMS). IEEE : 351-356. https://doi.org/10.1109/CBMS.2018.00068
|
| [20] |
Martin DR, Hanson JA, Gullapalli RR, et al. (2020) A deep learning convolutional neural network can recognize common patterns of injury in gastric pathology. Arch Pathol Lab Med 144: 370-378. https://doi.org/10.5858/arpa.2019-0004-OA
|
| [21] | Gammulle H, Denman S, Sridharan S, et al. (2020) Two-stream deep feature modelling for automated video endoscopy data analysis. International Conference on Medical Image Computing and Computer-Assisted Intervention . Cham: Springer 742-751. https://doi.org/10.1007/978-3-030-59716-0_71 |
| [22] | Li Z, Togo R, Ogawa T, et al. (2019) Semi-supervised learning based on tri-training for gastritis classification using gastric X-ray images. 2019 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE : 1-5. https://doi.org/10.1109/ISCAS.2019.8702261 |
| [23] |
Kanai M, Togo R, Ogawa T, et al. (2019) Gastritis detection from gastric X-ray images via fine-tuning of patch-based deep convolutional neural network. 2019 IEEE International Conference on Image Processing (ICIP). IEEE : 1371-1375. https://doi.org/0.1109/ICIP.2019.8803705
|
| [24] |
Cho BJ, Bang CS, Park SW, et al. (2019) Automated classification of gastric neoplasms in endoscopic images using a convolutional neural network. Endoscopy 51: 1121-1129. https://doi.org/10.1055/a-0981-6133
|
| [25] | Redmon J, Divvala S, Girshick R, et al. (2015) You look only once: unified real-time object detection. arXiv preprint arXiv : 1506.02640. https://doi.org/10.48550/arXiv.1506.02640 |
| [26] | Islam M, Seenivasan L, Ming LC, et al. (2020) Learning and reasoning with the graph structure representation in robotic surgery. International Conference on Medical Image Computing and Computer-Assisted Intervention . Cham: Springer 627-636. https://doi.org/10.1007/978-3-030-59716-0_60 |
| [27] |
Tran VP, Tran TS, Lee HJ, et al. (2021) One stage detector (RetinaNet)-based crack detection for asphalt pavements considering pavement distresses and surface objects. J Civil Struct Health Monit 11: 205-222. https://doi.org/0.1007/s13349-020-00447-8
|
| [28] |
Badrinarayanan V, Cipolla R, Kendall A (2017) Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence 39: 2481-2495. https://doi.org/10.1109/TPAMI.2016.2644615
|
| [29] |
Urbanos G, Martín A, Vázquez G, et al. (2021) Supervised machine learning methods and hyperspectral imaging techniques jointly applied for brain cancer classification. Sensors 21: 3827. https://doi.org/10.3390/s21113827
|
| [30] |
Urban G, Tripathi P, Alkayali T, et al. (2018) Deep learning localizes and identifies polyps in real time with 96% accuracy in screening colonoscopy. Gastroenterology 155: 1069-1078.e8. https//doi.org/10.1053/j.gastro.2018.06.037
|
| [31] |
Li L, Chen Y, Shen Z, et al. (2020) Convolutional neural network for the diagnosis of early gastric cancer based on magnifying narrow band imaging. Gastric Cancer 23: 126-132. https://doi.org/10.1007/s10120-019-00992-2
|
| [32] |
Ishihara K, Ogawa T, Haseyama M (2017) Detection of gastric cancer risk from X-ray images via patch-based convolutional neural network. 2017 IEEE International Conference on Image Processing (ICIP). IEEE : 2055-2059. https://doi.org/10.1109/ICIP.2017.8296643
|
| [33] |
Song Z, Zou S, Zhou W, et al. (2020) Clinically applicable histopathological diagnosis system for gastric cancer detection using deep learning. Nat Commun 11: 1-9. https://doi.org/10.1038/s41467-020-18147-8
|
| [34] |
Ikenoyama Y, Hirasawa T, Ishioka M, et al. (2021) Detecting early gastric cancer: Comparison between the diagnostic ability of convolutional neural networks and endoscopists. Digest Endosc 33: 141-150. https://doi.org/10.1111/den.13688
|
| [35] | Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical image computing and computer-assisted intervention . Cham: Springer 234-241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [36] | Folgoc LL, Heinrich M, Lee M, et al. Attention u-net: Learning where to look for the pancreas (2018). Available from: https://arxiv.org/pdf/1804.03999.pdf%E4%BB%A3%E7%A0%81%E5%9C%B0%E5%9D%80%EF%BC%9Ahttps://github.com/ozan-oktay/Attention-Gated-Networks |
| [37] |
Li X, Chen H, Qi X, et al. (2018) H-DenseUNet: hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE transactions on medical imaging 37: 2663-2674. https://doi.org/10.1109/TMI.2018.2845918
|
| [38] |
Zhou Z, Rahman Siddiquee MM, Tajbakhsh N, et al. (2018) Unet++: A nested u-net architecture for medical image segmentation. Deep learning in medical image analysis and multimodal learning for clinical decision support : 3-11. https://doi.org/10.1007/978-3-030-00889-5_1
|





Figures(6) / Tables(5)

Lamia Fatiha KAZI TANI, Mohammed Yassine KAZI TANI, Benamar KADRI. Gas-Net: A deep neural network for gastric tumor semantic segmentation[J]. AIMS Bioengineering, 2022, 9(3): 266-282. doi: 10.3934/bioeng.2022018







 DownLoad:
DownLoad: