We have previously evidenced that Mindfulness Meditation (MM) in experienced meditators (EMs) is associated with long-lasting topological changes in resting state condition. However, what occurs during the meditative phase is still debated.
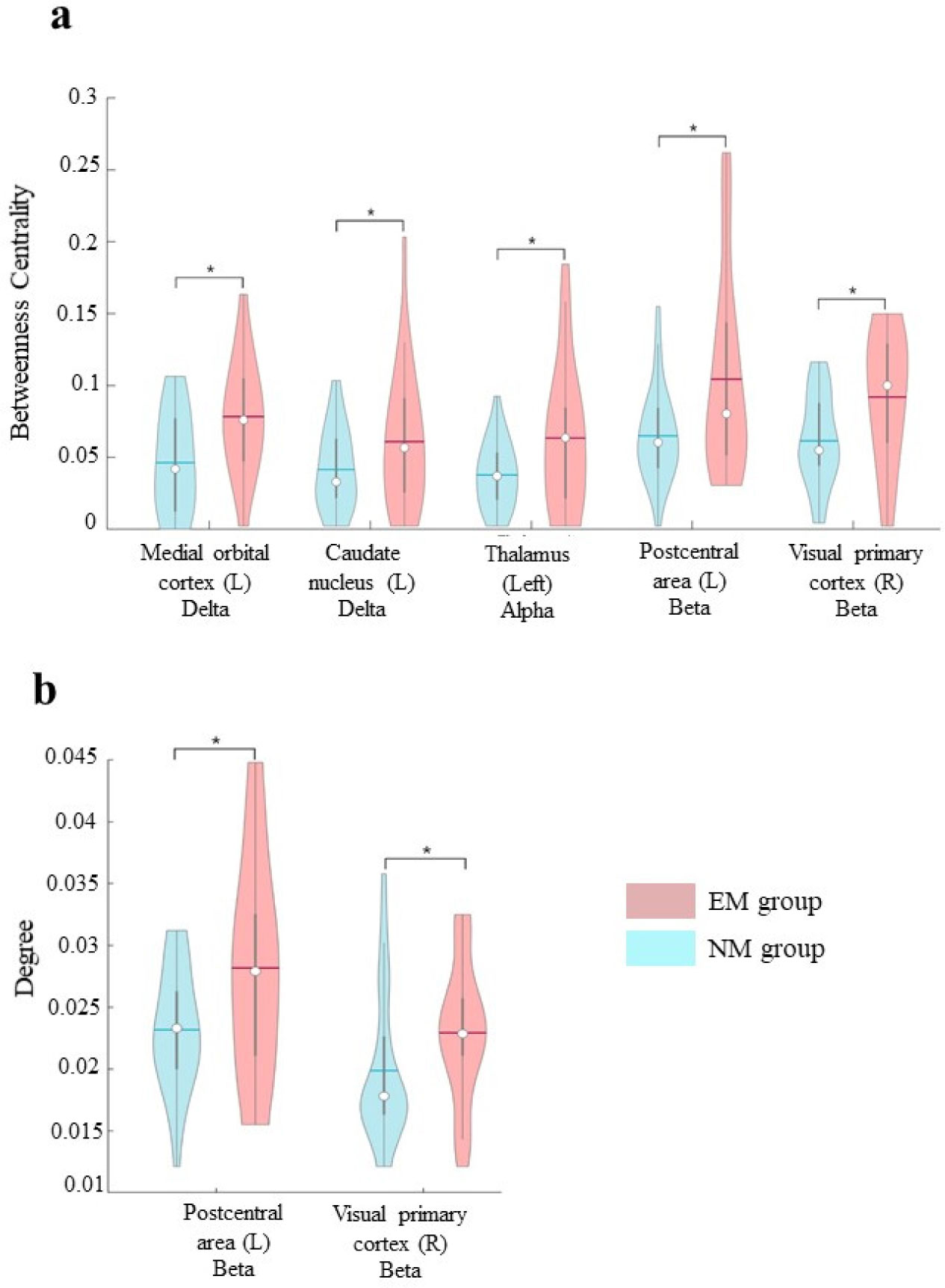
Utilizing magnetoencephalography (MEG), the present study is aimed at comparing the topological features of the brain network in a group of EMs (n = 26) during the meditative phase with those of individuals who had no previous experience of any type of meditation (NM group, n = 29). A wide range of topological changes in the EM group as compared to the NM group has been shown. Specifically, in EMs, we have observed increased betweenness centrality in delta, alpha, and beta bands in both cortical (left medial orbital cortex, left postcentral area, and right visual primary cortex) and subcortical (left caudate nucleus and thalamus) areas. Furthermore, the degree of beta band in parietal and occipital areas of EMs was increased too.
Our exploratory study suggests that the MM can change the functional brain network and provides an explanatory hypothesis on the brain circuits characterizing the meditative process.
Citation: Anna Lardone, Marianna Liparoti, Pierpaolo Sorrentino, Roberta Minino, Arianna Polverino, Emahnuel Troisi Lopez, Simona Bonavita, Fabio Lucidi, Giuseppe Sorrentino, Laura Mandolesi. Topological changes of brain network during mindfulness meditation: an exploratory source level magnetoencephalographic study[J]. AIMS Neuroscience, 2022, 9(2): 250-263. doi: 10.3934/Neuroscience.2022013
We have previously evidenced that Mindfulness Meditation (MM) in experienced meditators (EMs) is associated with long-lasting topological changes in resting state condition. However, what occurs during the meditative phase is still debated.
Utilizing magnetoencephalography (MEG), the present study is aimed at comparing the topological features of the brain network in a group of EMs (n = 26) during the meditative phase with those of individuals who had no previous experience of any type of meditation (NM group, n = 29). A wide range of topological changes in the EM group as compared to the NM group has been shown. Specifically, in EMs, we have observed increased betweenness centrality in delta, alpha, and beta bands in both cortical (left medial orbital cortex, left postcentral area, and right visual primary cortex) and subcortical (left caudate nucleus and thalamus) areas. Furthermore, the degree of beta band in parietal and occipital areas of EMs was increased too.
Our exploratory study suggests that the MM can change the functional brain network and provides an explanatory hypothesis on the brain circuits characterizing the meditative process.
Automated Anatomical Labeling
betweenness centrality
electroencephalography
experienced meditators
False Discovery Rate
functional Magnetic Resonance Imaging
Independent Component Analysis
magnetoencephalography
Mindfulness Meditation
minimum spanning tree
individuals who had no previous experience of any type of meditation
Phase Lag Index

| [1] |
Chiesa A (2010) Vipassana meditation: systematic review of current evidence. J Altern Complem Med 16: 37-46. https://doi.org/10.1089/acm.2009.0362 
|
| [2] |
Kabat-Zinn J (2003) Mindfulness-based interventions in context: past, present, and future. Clin Psychol-Sci Pr 10: 144-156. https://doi.org/10.1093/clipsy.bpg016
|
| [3] |
Hölzel BK, Ott U, Hempel H, et al. (2007) Differential engagement of anterior cingulate and adjacent medial frontal cortex in adept meditators and non-meditators. Neurosci Lett 421: 16-21. https://doi.org/10.1016/j.neulet.2007.04.074
|
| [4] |
Jung YH, Kang DH, Jang JH, et al. (2007) The effects of mind–body training on stress reduction, positive affect, and plasma catecholamines. Neurosci Lett 479: 138-142. https://doi.org/10.1016/j.neulet.2010.05.048
|
| [5] |
Lutz A, Dunne JD, Davidson RJ (2007) Meditation and the neuroscience of consciousness: An introduction. The Cambridge handbook of consciousness . Cambridge University Press pp 499-551. https://doi.org/10.1017/CBO9780511816789.020
|
| [6] |
Tang Y-Y, Tang R, Posner MI (2016) Mindfulness meditation improves emotion regulation and reduces drug abuse. Drug Alcohol Depen 163: S13-S18. https://doi.org/10.1016/j.drugalcdep.2015.11.041
|
| [7] |
Gardi C, Fazia T, Stringa B, et al. (2022) A short Mindfulness retreat can improve biological markers of stress and inflammation. Psychoneuroendocrinology 135: 105579. https://doi.org/10.1016/j.psyneuen.2021.105579
|
| [8] |
Tang Y-Y, Hölzel BK, Posner MI (2015) The neuroscience of mindfulness meditation. Nat Rev Neurosci 16: 213-225. https://doi.org/10.1038/nrn3916
|
| [9] |
Kurth F, MacKenzie-Graham A, Toga A, et al. (2014) Shifting brain asymmetry: the link between meditation and structural lateralization. Soc Cogn Affect Neur 10: 55-61. https://doi.org/10.1093/scan/nsu029
|
| [10] |
Luders E, Toga AW, Lepore N, et al. (2009) The underlying anatomical correlates of long-term meditation: larger hippocampal and frontal volumes of gray matter. Neuroimage 45: 672-678. https://doi.org/10.1016/j.neuroimage.2008.12.061
|
| [11] |
van Lutterveld R, van Dellen E, Pal P, et al. (2017) Meditation is associated with increased brain network integration. NeuroImage 158: 18-25. https://doi.org/10.1016/j.neuroimage.2017.06.071
|
| [12] |
Raffone A, Marzetti L, Del Gratta C, et al. (2019) Toward a brain theory of meditation. Prog Brain Res 244: 207-232. https://doi.org/10.1016/bs.pbr.2018.10.028
|
| [13] |
Mooneyham BW, Mrazek MD, Mrazek AJ, et al. (2016) Signal or noise: brain network interactions underlying the experience and training of mindfulness. Ann NY Acad Sci 1369: 240-256. https://doi.org/10.1111/nyas.13044
|
| [14] |
Jang JH, Jung WH, Kang DH, et al. (2011) Increased default mode network connectivity associated with meditation. Neurosci Lett 487: 358-362. https://doi.org/10.1016/j.neulet.2010.10.056
|
| [15] |
Zhang Z, Luh WM, Duan W, et al. (2021) Longitudinal effects of meditation on brain resting-state functional connectivity. Sci Rep 11: 1-14. https://doi.org/10.1038/s41598-021-90729-y
|
| [16] |
Friston KJ (2011) Functional and effective connectivity: a review. Brain Connect 1: 13-36. https://doi.org/10.1089/brain.2011.0008
|
| [17] |
Poldrack RA, Laumann TO, Koyejo O, et al. (2015) Long-term neural and physiological phenotyping of a single human. Nat Commun 6: 1-15. https://doi.org/10.1038/ncomms9885
|
| [18] |
Spoormaker VI, Schröter MS, Gleiser PM, et al. (2010) Development of a large-scale functional brain network during human non-rapid eye movement sleep. J Neurosci 30: 11379-11387. https://doi.org/10.1523/JNEUROSCI.2015-10.2010
|
| [19] |
Jacini F, Sorrentino P, Lardone A, et al. (2018) Amnestic mild cognitive impairment is associated with frequency-specific brain network alterations in temporal poles. Front Aging Neurosci 10: 400. https://doi.org/10.3389/fnagi.2018.00400
|
| [20] |
Sorrentino P, Rucco R, Jacini F, et al. (2018) Brain functional networks become more connected as amyotrophic lateral sclerosis progresses: a source level magnetoencephalographic study. NeuroImage-Clin 20: 564-571. https://doi.org/10.1016/j.nicl.2018.08.001
|
| [21] |
Bullmore E, Sporns O (2009) Complex brain networks: graph theoretical analysis of structural and functional systems. Nat Rev Neurosci 10: 186. https://doi.org/10.1038/nrn2575
|
| [22] |
de Vico Fallani F, Richiardi J, Chavez M, et al. (2014) Graph analysis of functional brain networks: practical issues in translational neuroscience. Philos T R Soc B 369: 20130521. https://doi.org/10.1098/rstb.2013.0521
|
| [23] |
Baillet S (2017) Magnetoencephalography for brain electrophysiology and imaging. Nat Neurosci 20: 327-339. https://doi.org/10.1038/nn.4504
|
| [24] |
Marzetti L, Di Lanzo C, Zappasodi F, et al. (2014) Magnetoencephalographic alpha band connectivity reveals differential default mode network interactions during focused attention and open monitoring meditation. Front Hum Neurosci 8. https://doi.org/10.3389/fnhum.2014.00832
|
| [25] |
Wong WP, Camfield DA, Woods W, et al. (2015) Spectral power and functional connectivity changes during mindfulness meditation with eyes open: A magnetoencephalography (MEG) study in long-term meditators. Int J Psychophysiol 98: 95-111. https://doi.org/10.1016/j.ijpsycho.2015.07.006
|
| [26] | Lardone A, Liparoti M, Sorrentino P, et al. (2018) Mindfulness meditation is related to long-lasting changes in hippocampal functional topology during resting state: a magnetoencephalography study. Neural Plast . https://doi.org/10.1155/2018/5340717 |
| [27] |
Jao T, Li CW, Vértes PE, et al. (2016) Large-scale functional brain network reorganization during Taoist meditation. Brain Connect 6: 9-24. https://doi.org/10.1089/brain.2014.0318
|
| [28] |
Stam CJ, Nolte G, Daffertshofer A (2007) Phase lag index: assessment of functional connectivity from multi channel EEG and MEG with diminished bias from common sources. Hum Brain Mapp 28: 1178-1193. https://doi.org/10.1002/hbm.20346
|
| [29] |
van Wijk B, Stam C, Daffertshofer A (2010) Comparing brain networks of different size and connectivity density using graph theory. PLoS One 5: e13701. https://doi.org/10.1371/journal.pone.0013701
|
| [30] |
Tewarie P, van Dellen E, Hillebrand A, et al. (2015) The minimum spanning tree: An unbiased method for brain network analysis. NeuroImage 104: 177-188. https://doi.org/10.1016/j.neuroimage.2014.10.015
|
| [31] |
Gross J, Baillet S, Barnes GR, et al. (2013) Good practice for conducting and reporting MEG research. NeuroImage 65: 349-363. https://doi.org/10.1016/j.neuroimage.2012.10.001
|
| [32] |
De Cheveigné A, Simon JZ (2007) Denoising based on time-shift PCA. J Neurosci Meth 165: 297-305. https://doi.org/10.1016/j.jneumeth.2007.06.003
|
| [33] |
Sadasivan PK, Dutt DN (1996) SVD based technique for noise reduction in electroencephalographic signals. Signal Process 55: 179-189. https://doi.org/10.1016/S0165-1684(96)00129-6
|
| [34] |
Barbati G, Porcaro C, Zappasodi F, et al. (2004) Optimization of an independent component analysis approach for artifact identification and removal in magnetoencephalographic signals. Clin Neurophysiol 115: 1220-1232. https://doi.org/10.1016/j.clinph.2003.12.015
|
| [35] |
Fraschini M, Demuru M, Crobe A, et al. (2016) The effect of epoch length on estimated EEG functional connectivity and brain network organisation. J Neural Eng 13: 36015. https://orcid.org/0000-0003-2784-6527
|
| [36] | Oostenveld R, Fries P, Maris E, et al. (2011) Field Trip: open source software for advanced analysis of MEG, EEG, and invasive electrophysiological data. Comput Intel Neurosc 1. https://doi.org/10.1155/2011/156869 |
| [37] |
Nolte G (2003) The magnetic lead field theorem in the quasi-static approximation and its use for magnetoencephalography forward calculation in realistic volume conductors. Phys Med Biol 48: 3637-3652. https://doi.org/10.1088/0031-9155/48/22/002
|
| [38] |
Van Veen BD, Van Drongelen W, Yuchtman M (1997) Localization of Brain Electrical Activity via Linearly Constrained Minimum Variance Spatial Filtering. IEEE T Biomed Eng 44. https://doi.org/10.1109/10.623056
|
| [39] |
Gong G, He Y, Concha L, et al. (2009) Mapping anatomical connectivity patterns of human cerebral cortex using in vivo diffusion tensor imaging tractography. Cereb Cortex 19: 524-536. https://doi.org/10.1093/cercor/bhn102
|
| [40] |
Hillebrand A, Tewarie P, van Dellen E, et al. (2016) Direction of information flow in large-scale resting-state networks is frequency-dependent. P Natl Acad Sci USA 113: 3867-3872. https://doi.org/10.1073/pnas.1515657113
|
| [41] |
Tzourio-Mazoyer N, Landeau B, Papathanassiou D, et al. (2002) Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. NeuroImage 15: 273-289. https://doi.org/10.1006/nimg.2001.0978
|
| [42] | Brookes MJ, Woolrich M, Luckhoo H, et al. (2011) Investigating the electrophysiological basis of resting state networks using magnetoencephalography. P Natl Acad Sci 201112685. https://doi.org/10.1073/pnas.1112685108 |
| [43] |
Jerbi K, Lachaux J-P, Karim N, et al. (2007) Coherent neural representation of hand speed in humans revealed by MEG imaging. P Natl Acad Sci 104: 7676-7681. https://doi.org/10.1073/pnas.0609632104
|
| [44] |
Kruskal JB (1956) On the Shortest Spanning Subtree of a Graph and the Traveling Salesman Problem. P Am Math Soc 7: 48. https://doi.org/10.2307/2033241
|
| [45] |
Stam CJ, Tewarie P, Van Dellen E, et al. (2014) The trees and the forest: Characterization of complex brain networks with minimum spanning trees. Int J Psychophysiol 92: 129-138. https://doi.org/10.1016/j.ijpsycho.2014.04.001
|
| [46] |
Boersma M, Smit DJA, Boomsma DI, et al. (2013) Growing Trees in Child Brains: Graph Theoretical Analysis of Electroencephalography-Derived Minimum Spanning Tree in 5- and 7-Year-Old Children Reflects Brain Maturation. Brain Connect 3: 50-60. https://doi.org/10.1089/brain.2012.0106
|
| [47] |
Freeman LC (1977) A Set of Measures of Centrality Based on Betweenness. Sociometry 40: 35. https://doi.org/10.2307/3033543
|
| [48] |
Nichols TE, Holmes AP (2002) Nonparametric permutation tests for functional neuroimaging: a primer with examples. Hum Brain Mapp 15: 1-25. https://doi.org/10.1002/hbm.1058
|
| [49] | Benjamini Y, Hochberg Y (1995) Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J R Stat Soc 57: 289-300. https://doi.org/10.2307/2346101 |
| [50] |
van der Meer L, Costafreda S, Aleman A, et al. (2010) Self-reflection and the brain: a theoretical review and meta-analysis of neuroimaging studies with implications for schizophrenia. Neurosci Biobehav R 34: 935-946. https://doi.org/10.1016/j.neubiorev.2009.12.004
|
| [51] |
Sperduti M, Martinelli P, Piolino P (2012) A neurocognitive model of meditation based on activation likelihood estimation (ALE) meta-analysis. Conscious Cogn 21: 269-276. https://doi.org/10.1016/j.concog.2011.09.019
|
| [52] |
Tang Y-Y, Ma Y, Fan Y, et al. (2009) Central and autonomic nervous system interaction is altered by short-term meditation. P Natl Acad Sci 106: 8865-8870. https://doi.org/10.1073/pnas.0904031106
|
| [53] |
Ray WJ, Cole HW (1985) EEG alpha activity reflects attentional demands, and beta activity reflects emotional and cognitive processes. Science 228: 750-752. https://doi.org/10.1126/science.3992243
|
| [54] |
Cantero JL, Atienza M, Salas RM (2002) Human alpha oscillations in wakefulness, drowsiness period, and REM sleep: different electroencephalographic phenomena within the alpha band. Neurophysiol Clin 32: 54-71. https://doi.org/10.1016/S0987-7053(01)00289-1
|
| [55] |
Braboszcz C, Cahn BR, Levy J, et al. (2017) Increased gamma brainwave amplitude compared to control in three different meditation traditions. PloS One 12: e0170647. https://doi.org/10.1371/journal.pone.0170647
|
| [56] |
Cahn BR, Delorme A, Polich J (2012) Event-related delta, theta, alpha and gamma correlates to auditory oddball processing during Vipassana meditation. Soc Cogn Affect Neur 8: 100-111. https://doi.org/10.1093/scan/nss060
|
| [57] |
Ungerleider LG, Haxby JV (1992) ‘What’ and ‘where’ in the human brain. Curr Opin Neurobiol 4: 157-165. https://doi.org/10.1016/0959-4388(94)90066-3
|
| [58] |
Winlove CIP, Milton F, Ranson J, et al. (1992) The neural correlates of visual imagery: a co-ordinate-based meta-analysis. Cortex 105: 4-25. https://doi.org/10.1016/j.cortex.2017.12.014
|
| [59] |
Lindahl JR, Kaplan CT, Winget EM, et al. (2014) A phenomenology of meditation-induced light experiences: traditional Buddhist and neurobiological perspectives. Front Psychol 4: 973. https://doi.org/10.3389/fpsyg.2013.00973
|
| [60] |
Ahani A, Wahbeh H, Nezamfar H, et al. (2014) Quantitative change of EEG and respiration signals during mindfulness meditation. J Neuroeng Rehabil 11: 87. https://doi.org/10.1186/1743-0003-11-87
|
| [61] |
Khoury B, Lecomte T, Fortin G, et al. (2013) Mindfulness-based therapy: A comprehensive meta-analysis. Clin Psychol Rev 33: 763-771. https://doi.org/10.1016/j.cpr.2013.05.005
|
| [62] |
Khoury B, Sharma M, Rush SE, et al. (2015) Mindfulness-based stress reduction for healthy individuals: A meta-analysis. J Psychosom Res 78: 519-528. https://doi.org/10.1016/j.jpsychores.2015.03.009
|
 neurosci-09-02-013-s001.pdf neurosci-09-02-013-s001.pdf |
 |
Figures(1)

Anna Lardone, Marianna Liparoti, Pierpaolo Sorrentino, Roberta Minino, Arianna Polverino, Emahnuel Troisi Lopez, Simona Bonavita, Fabio Lucidi, Giuseppe Sorrentino, Laura Mandolesi. Topological changes of brain network during mindfulness meditation: an exploratory source level magnetoencephalographic study[J]. AIMS Neuroscience, 2022, 9(2): 250-263. doi: 10.3934/Neuroscience.2022013







 DownLoad:
DownLoad: