Citation: Pamila Sadeeka Adikari, KGRV Pathirathna, WKWS Kumarawansa, PD Koggalage. Role of MOH as a grassroots public health manager in preparedness and response for COVID-19 pandemic in Sri Lanka[J]. AIMS Public Health, 2020, 7(3): 606-619. doi: 10.3934/publichealth.2020048

| [1] | Guo YR, Cao QD, Hong ZS, et al. (2020) The origin, transmission and clinical therapies on coronavirus disease 2019 (COVID-19) outbreak-an update on the status. Mil Med Res 7: 11. |
| [2] | Kohona P (2020) Sri Lanka Has Been Successful in Countering COVID-19, The Small Indian Ocean Island Deserves Recognition, 2020.Available from: https://www.indepthnews.net/index.php/opinion/3518-sri-lanka-has-been-successful-in-countering-covid-19. |
| [3] | Worldometer (2020) Sri Lanka Population (2020)-Worldometer, 2020.Available from: https://www.worldometers.info/world-population/sri-lanka-population/. |
| [4] | World Health Organization (2015) Climate and Health Country Profile-2015, Sri Lanka.Available from: https://www.who.int/docs/default-source/searo/wsh-och-searo/srl-c-h-profile.pdf?sfvrsn=1b62c800_2. |
| [5] | Perera A, Perera HSR (2017) Primary Healthcare Systems (PRIMASYS)-case study from Sri Lanka, World Health Organization.Available from: https://www.who.int/alliance-hpsr/projects/alliancehpsr_srilankaprimasys.pdf?ua=1. |
| [6] | World Health Organization (2018) Technical Series on Primary Health Care.Available from: https://www.who.int/docs/default-source/primary-health-care-conference/public-health. |
| [7] | Ministry of Health (2005) General Circular No:01-09/2005; Working hours of staff in DDHS/MOH office.Available from: http://www.health.gov.lk/CMS/cmsmoh1/upload/english/01-09-2005-eng.pdf. |
| [8] |
Ratnayake HE, Rowel D (2018) Prevalence of exclusive breastfeeding and barriers for its continuation up to six months in Kandy district, Sri Lanka. Int Breastfeed J 13: 1-8. doi: 10.1186/s13006-018-0180-y

|
| [9] | The World Bank (2018) World Bank, Elevating Sri Lanka's Public Health to the Next Level, 2018.Available from: http://projects-beta.worldbank.org/en/results/2018/09/14/elevating-sri-lankas-public-health-next-level. |
| [10] | Sri Lanka (2017) Reorganising Primary Health Care in Sri Lanka, Preserving our progress, preparing our future.Available from: http://www.health.gov.lk/moh_final/english/public/elfinder/files/publications/2018/ReorgPrimaryHealthCare.pdf. |
| [11] | Center for Global Development Saving mothers' lives in Sri Lanka.Available from: https://www.cgdev.org/sites/default/files/archive/doc/millions/MS_case_6.pdf. |
| [12] | Hewa S (2011) Sri Lanka's Health Unit Program: A Model of “Selective” Primary Health Care. Hygiea Int Interdiscip J Hist Public Health 10: 7-33. |
| [13] | World Health Organization (2020) Critical preparedness, readiness and response actions for COVID-19-Interim Guidance.Available from: https://www.who.int/publications/i/item/critical-preparedness-readiness-and-response-actions-for-covid-19. |
| [14] | Office of the Provincial Director of Health Services Medical Officer of Health.Available from: http://healthdept.wp.gov.lk/web/?page_id=523. |
| [15] | Sri lanka (2010) Manual for the Sri Lanka Public Health Inspector.Available from: https://medicine.kln.ac.lk/depts/publichealth/Fixed_Learning/PHI%20manual/PHI%20New%20Documents%20Including%20full%20PHI%20Manual%20$%20Office%20Documents/PHI%20Manual%20Full/03%20Chapter%201%20-Duties%20&%20Responsibilities%20(1-78).pdf. |
| [16] | Rizan ILM (2018) Daily News, Dengue on the rise in Ampara, 2018.Available from: http://www.dailynews.lk/2018/02/02/local/141771/dengue-rise-ampara. |
| [17] | Sri Lanka (2017) Public health measures to be adopted in the event of floods. |
| [18] | Sri Lanka (2016) Policy repository of Ministry of Health 2016.Available from: http://www.health.gov.lk/moh_final/english/public/elfinder/files/publications/publishpolicy/PolicyRepository.pdf. |
| [19] | Director General of Health Services (2020) Delegation of authority to carry out functions under the quarantine and prevention of diseases ordinance. |
| [20] | Faculty of Medicine, University of Jaffna (2020) Community engagement; Department of Community and Family Medicine, 2020.Available from: http://www.med.jfn.ac.lk/index.php/community-medicine/service-functions/. |
| [21] | Amarasinghe SN, Dalpatadu KCS, Rannan-Eliya RP (2018) Sri Lanka Health Accounts: National Health Expenditure 1990–2016.Available from: http://www.ihp.lk/publications/docs/HES1805.pdf. |
| [22] | Sri Lanka (2020) Live updates on New Coronavirus (COVID-19) outbreak, 2020.Available from: https://www.hpb.health.gov.lk/en. |
| [23] | World Health Organization (2020) Surveillance strategies for COVID-19 human infection, 2020.Available from: https://www.who.int/publications-detail/surveillance-strategies-for-covid-19-human-infection. |
| [24] | Sri Lanka (2019) Annual Health Statistics 2017, Sri Lanka.Available from: http://www.health.gov.lk/moh_final/english/public/elfinder/files/publications/AHB/2017/AHS2017.pdf. |
| [25] | Sri Lanka (2020) Updated interim case definition and advice on initial management.Available from: http://epid.gov.lk/web/index.php?option=com_content&view=article&id=230&lang=en. |
| [26] | Sri Lanka (2020) COVID-19 (New Coronavirus) Outbreak in Sri Lanka, Interim Guidelines for Sri Lankan Primary Care Physicians.Available from: http://epid.gov.lk/web/index.php?option=com_content&view=article&id=230&lang=en. |
| [27] | Epidemiology Unit, Ministry of Health, Sri Lanka Brochure on Influenza.Available from: https://www.epid.gov.lk/web/images/pdf/Influenza/Message/influenza_disease.pdf. |
| [28] |
Rao RU, Nagodavithana KC, Samarasekera SD, et al. (2014) A Comprehensive Assessment of Lymphatic Filariasis in Sri Lanka Six Years after Cessation of Mass Drug Administration. PLoS Negl Trop Dis 8: e3281. doi: 10.1371/journal.pntd.0003281
|
| [29] | News First (2020) Sri Lanka News-Newsfirst, Sri Lanka to boost its PCR testing capacity to combat COVID-19, 2020.Available from: https://www.newsfirst.lk/2020/04/27/sri-lanka-to-boost-its-pcr-testing-capacity-to-combat-covid-19/. |
| [30] | Sri Lanka (2020) Guidance on resumption of immunization services during COVID-19 outbreak.Available from: http://epid.gov.lk/web/index.php?option=com_content&view=article&id=230&lang=en. |
| [31] |
Chughtai AA, Seale H, Islam MS, et al. (2020) Policies on the use of respiratory protection for hospital health workers to protect from coronavirus disease (COVID-19). Int J Nurs Stud 105: 103567. doi: 10.1016/j.ijnurstu.2020.103567
|
| [32] | Sri Lanka (2020) Maintenance of a register for healthcare workers exposed to COVID-19 at health care institutions.Available from: http://epid.gov.lk/web/index.php?option=com_content&view=article&id=230&lang=en. |
| [33] | Ozili PK, Arun T (2020) Spillover of COVID-19: Impact on the Global Economy. MPRA Paper 99317 Germany: University Library of Munich. |
| [34] | Directorate of Environmental health, Occupational health and Food safety, Ministry of Health and Indigenous Medical Services (2020) Guidelines on COVID-19 preparedness for workplaces.Available from: http://epid.gov.lk/web/index.php?option=com_content&view=article&id=230&lang=en. |
| [35] |
Jayatilleke AC, Yoshikawa K, Yasuoka J, et al. (2015) Training Sri Lankan public health midwives on intimate partner violence: a pre- and post-intervention study. BMC Public Health 15: 331. doi: 10.1186/s12889-015-1674-9
|
| [36] | Sri Lanka Medical Association (2017) SLMA guidelines and information on vaccines.Available from: https://slma.lk/wp-content/uploads/2017/12/GSK-SLMA-Guidelines-Information-on-Vaccines.pdf. |
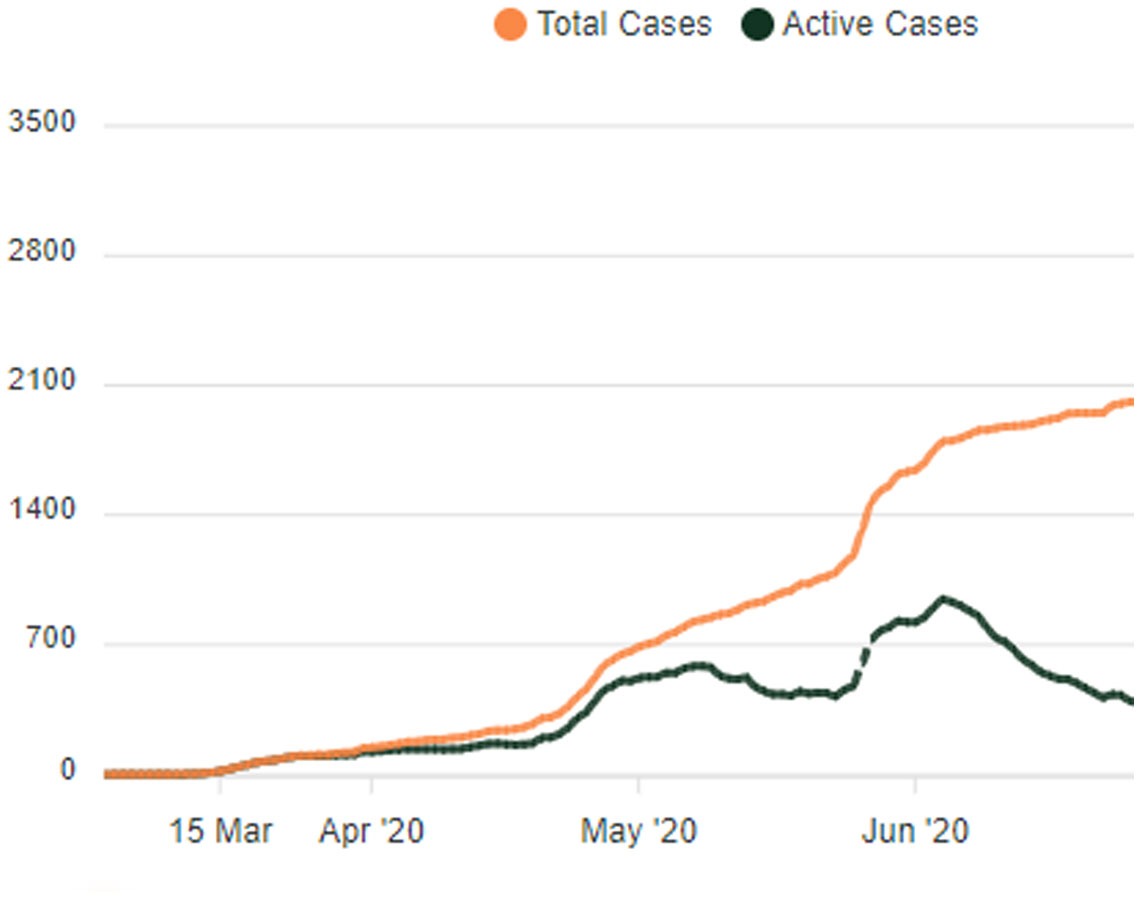
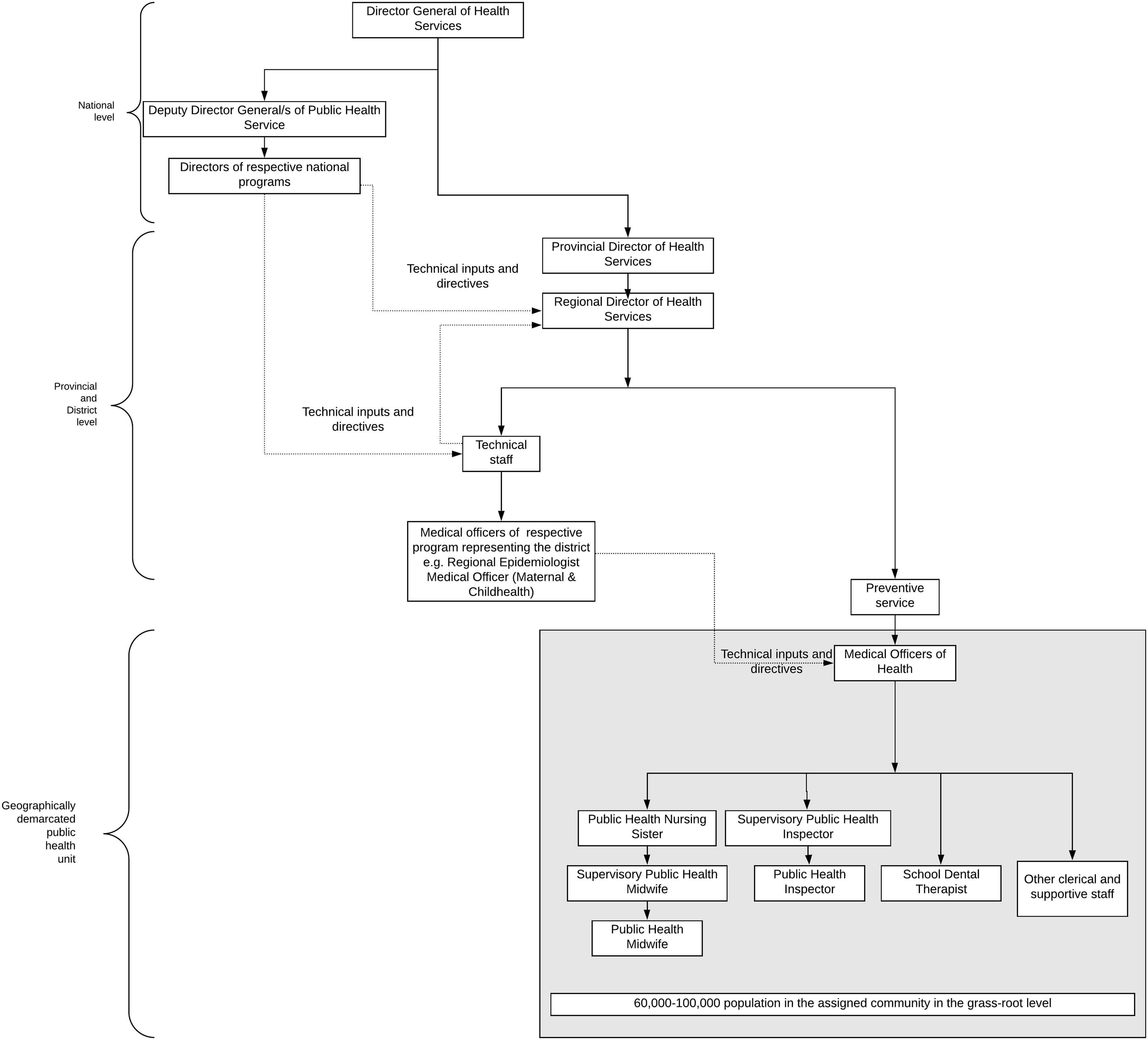
Figures(2) / Tables(1)

Pamila Sadeeka Adikari, KGRV Pathirathna, WKWS Kumarawansa, PD Koggalage. Role of MOH as a grassroots public health manager in preparedness and response for COVID-19 pandemic in Sri Lanka[J]. AIMS Public Health, 2020, 7(3): 606-619. doi: 10.3934/publichealth.2020048







 DownLoad:
DownLoad: