Citation: Yi-Wen Chang, Kang-Ping Lu, Shao-Tung Chang. Cluster validity indices for mixture hazards regression models[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1616-1636. doi: 10.3934/mbe.2020085

| [1] | D. R. Cox, Regression models and life-tables with discussion, J. R. Stat. Soc. Ser. B-Stat. Methodol., 34 (1972), 187-220. |
| [2] | G. Escarela, and R. Bowater, Fitting a semi-parametric mixture model for competing risks in survival data, Commun. Stat.-Theory Methods, 37 (2008), 277-293. |
| [3] | S. C. Cheng, J. P. Fine, and L. J. Wei, Prediction of cumulative incidence function under the proportional hazards model, Biometrics 54 (1998), 219-228. |
| [4] | G. J. McLachlan and D. Peel, Finite mixture models, Wiley Series in Probability and Statistics: Applied Probability and Statistics, Wiley-Interscience, New York, 2000. |
| [5] | S. K. Ng and G. J. McLachlan, An EM-based semi-parametric mixture model approach to the regression analysis of competing risks data, Stat. Med., 22 (2003), 1097-1111. |
| [6] | I. S. Chang, C. A. Hsiung, C. C. Wen and W. C. Yang, Non-parametric maximum likelihood estimation in a semiparametric mixture model for competing risks data, Scand. J. Stat., 34 (2007), 870-895. |
| [7] | W. Lu and L. Peng, Semiparametric analysis of mixture regression models with competing risks data, Lifetime Data Anal., 14 (2008), 231-252. |
| [8] | S. Choi and X. Huang, Maximum likelihood estimation of semiparametric mixture component models for competing risks data, Biometrics, 70 (2014), 588-598. |
| [9] | A. K. Jain and R. C. Dubes, Algorithms for clustering data, Prentice-Hall, Englewood Cliffs, NJ, 1988. |
| [10] | Y. G. Tang, F. C. Sun and Z. Q. Sun, Improved validation index for fuzzy clustering, in American Control Conference, June 8-10, 2005. Portland, OR, USA, (2005), 1120-1125. |
| [11] | W. Wang and Y. Zhang, On fuzzy cluster validity indices, Fuzzy Sets Syst., 158 (2007), 2095-2117. |
| [12] | K. L. Wu, M. S. Yang and J. N. Hsieh, Robust cluster validity indexes, Pattern Recognit., 42 (2009), 2541-2550. |
| [13] | K. L. Zhou, S. Ding, C. Fu and S. L. Yang, Comparison and weighted summation type of fuzzy cluster validity indices, Int. J. Comput. Commun. Control, 9 (2014), 370-378. |
| [14] | J. M. Henson, S. P. Reise and K. H. Kim, Detecting mixtures from structural model differences using latent variable mixture modeling: A comparison of relative model fit statistics, Struct. Equ. Modeling, 14 (2007), 202-226. |
| [15] | J. R. Busemeyer, J. Wang, J. T. Townsend and A. Eidels, The Oxford Handbook of Computational and Mathematical Psychology. Oxford University Press 2015. |
| [16] | R. Bender, T. Augustin and M. Blettner, Generating survival times to simulate Cox proportional hazards models, Stat. Med., 24 (2005), 1713-1723. |
| [17] | P. Royston, Estimating a smooth baseline hazard function for the Cox model. Technical Report No. 314. University College London, London 2011. Available from: https://www.semanticscholar.org/paper/Estimating-a-smooth-baseline-hazard-function-for-Royston/2f329b48f674a74253eb428b71ff237365fd4051. |
| [18] | A. Guilloux, S. Lemler and M. L. Taupin, Adaptive kernel estimation of the baseline function in the Cox model with high-dimensional covariates, J. Multivar. Anal., 148 (2016) 141-159. |
| [19] | M. Zhou, Empirical likelihood method in survival analysis, CRC Press 2016 |
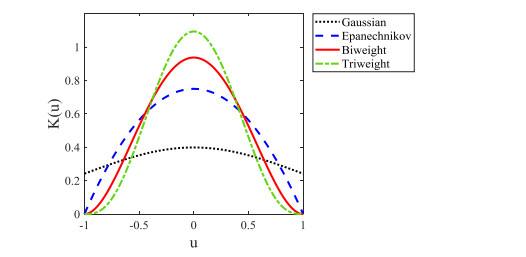
| [20] | I. Horova, J. Kolacek, and J. Zelinka, Kernel smoothing in Matlab theory and practice of kernel smoothing, World Scientific Publishing, 2012. |
| [21] | P. N. Patil, Bandwidth choice for nonparametric hazard rate estimation, J. Stat. Plan. Infer., 35 (1993), 15-30. |
| [22] | J. C. Bezdek, Numerical taxonomy with fuzzy sets, J. Math. Biol., 7 (1974), 57-71. |
| [23] | R. N. Dave, Validating fuzzy partition obtained through c-shells clustering, Pattern Recognit. Lett., 17 (1996), 613-623. |
| [24] | J. C. Bezdek, Cluster validity with fuzzy sets, Journal of Cybernetics, 3 (1974), 58-73. DOI: 10.1080/01969727308546047. |
| [25] | J. C. Dunn, Indices of partition fuzziness and the detection of clusters in large data sets, in Fuzzy Automata and Decision Processes, (ed. M.M. Gupta, Elsevier), NY, 1977. |
| [26] | D. P. Byar and S. B. Green, The choice of treatment for cancer patients based on covariate information: application to prostate cancer, Bull. Cancer, 67 (1980), 477-490. |
| [27] | D. F. Andrews and A. M. Herzberg, Data: a collection of problems from many fields for the student and research worker, Springer-Verlag, New York, (1985), 261-274. |
| [28] | R. Kay, Treatment effects in competing-risks analysis of prostate cancer data, Biometrics, 42 (1986), 203-211. |
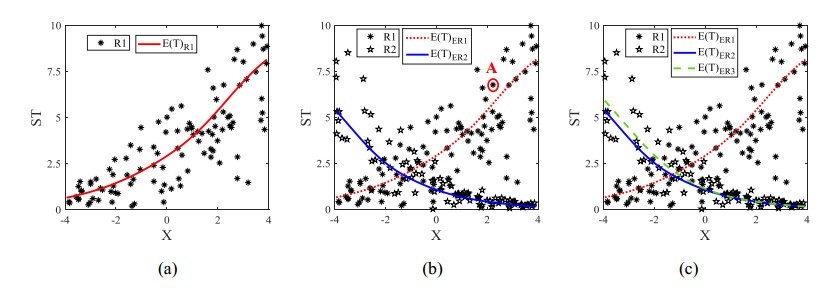
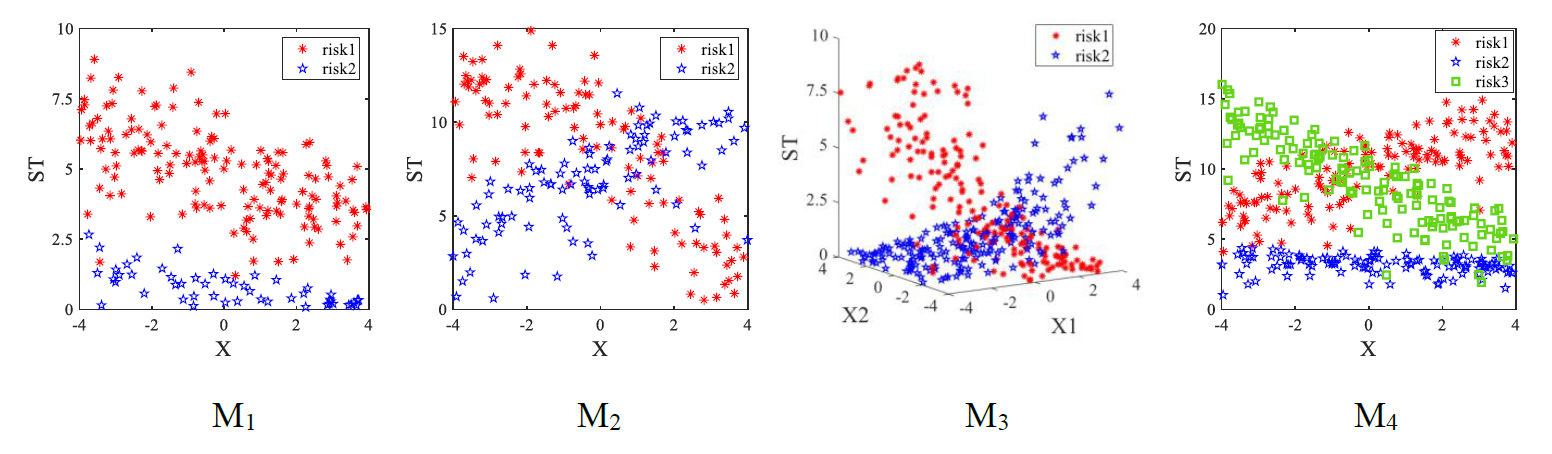
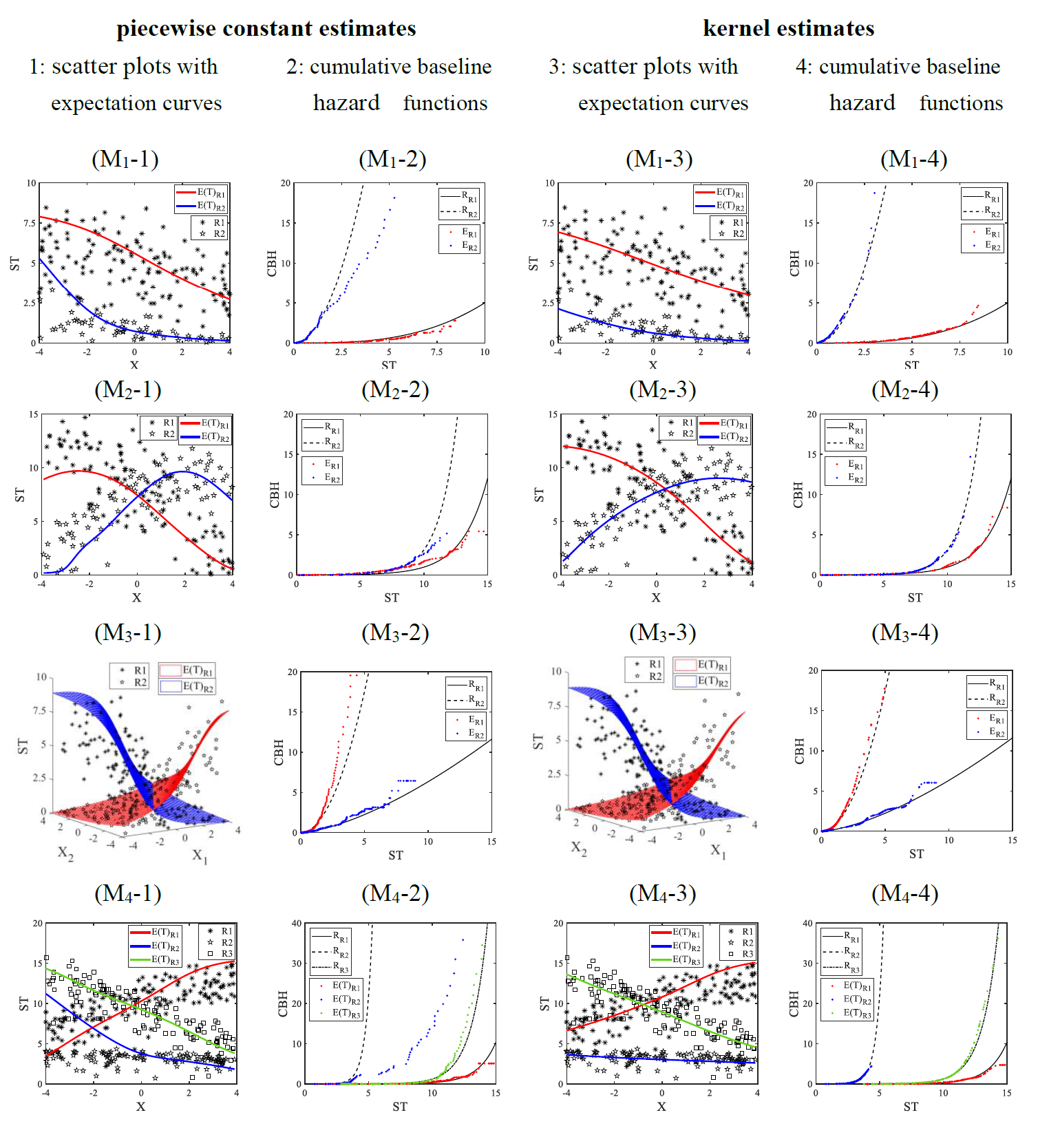
Figures(4) / Tables(7)

Yi-Wen Chang, Kang-Ping Lu, Shao-Tung Chang. Cluster validity indices for mixture hazards regression models[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1616-1636. doi: 10.3934/mbe.2020085







 DownLoad:
DownLoad: