Citation: Wenxue Huang, Yuanyi Pan. On Balancing between Optimal and Proportional categorical predictions[J]. Big Data and Information Analytics, 2016, 1(1): 129-137. doi: 10.3934/bdia.2016.1.129

| [1] | [ A. C. Acock, Working with missing values, Journal of Marriage and Family, 67(2005), 1012-1028. |
| [2] | [ E. Acuna and C. Rodriguez, The treatment of missing values and its effect in the classifier accuracy, In Classification, Clustering and Data Mining Applications, (2004), 639-647. |
| [3] | [ G. E. Batista and M. C. Monard, An analysis of four missing data treatment methods for supervised learning, Applied Artificial Intelligence, 17(2003), 519-533. |
| [4] | [ J. Doak, An Evaluation of Feature Selection Methods and Their Application to Computer Security, UC Davis Department of Computer Science, 1992. |
| [5] | [ P. Domingos, A unified bias-variance decomposition, In Proceedings of 17th International Conference on Machine Learning. Stanford CA Morgan Kaufmann, 2000, 231-238. |
| [6] | [ Survey of Family Expenditures-1996, STATCAN, 1998. |
| [7] | [ A. Farhangfar, L. Kurgan and J. Dy, Impact of imputation of missing values on classification error for discrete data, Pattern Recognition, 41(2008), 3692-3705. |
| [8] | [ H. H. Friedman, On bias, variance, 0/1-loss, and the curse-of-dimensionality, Data mining and knowledge discovery, 1(1997), 55-77. |
| [9] | [ S. Geman, E. Bienenstock and R. Doursaté, Neural networks and the bias/variance dilemma, Neural computation, 4(1992), 1-58. |
| [10] | [ L. A. Goodman and W. H. Kruskal, Measures of association for cross classification, J. American Statistical Association, 49(1954), 732-764. |
| [11] | [ I. Guyon and A. Elisseeff, An introduction to variable and feature selection, J. Mach. Learn. Res., 3(2003), 1157-1182. |
| [12] | [ L. Himmelspach and S. Conrad, Clustering approaches for data with missing values:Comparison and evaluation, In Digital Information Management (ICDIM), 2010 Fifth International Conference on,IEEE 2010, 19-28. |
| [13] | [ P. T. V. Hippel, Regression with missing Ys:An improved strategy for analyzing multiply imputed data, Sociological Methodology, 37(2007), 83-117. |
| [14] | [ W. Huang, Y. Shi and X. Wang, A nomminal association matrix with feature selection for categorical data, Communications in Statistics-Theory and Methods, to appear, 2015. |
| [15] | [ W. Huang, Y. Pan and J. Wu, Supervised Discretization for Optimal Prediction, Procedia Computer Science, 30(2014), 75-80. |
| [16] | [ G. James and T. Hastie, Generalizations of the Bias/Variance Decomposition for Prediction Error, Dept. Statistics, Stanford Univ., Stanford, CA, Tech. Rep, 1997. |
| [17] | [ S. Kullback and R. A. Leibler, On information and sufficiency, Annals of Mathematical Statistics, 22(1951), 79-86. |
| [18] | [ R. J. A. Little and D. B. Rubin, Statistical Analysis with Missing Data, John Wiley & Sons, Inc. 1987, New York, NY, USA. |
| [19] | [ H. Liu and H. Motoda, Feature Selection for Knowledge Discovery and Data Mining, Kluwer Academic Publishers 1998, Norwell, MA, USA. |
| [20] | [ J. Luengo, S. García and F. Herrera, On the choice of the best imputation methods for missing values considering three groups of classification methods, Knowledge and information systems, 32(2012), 77-108. |
| [21] | [ Z. Mark and Y. Baram, The bias-variance dilemma of the Monte Carlo method, Artificial Neural Networks,ICANN, 2130(2001), 141-147. |
| [22] | [ R. Tibshirani, Bias, Variance and Prediction Error for Classification Rules, Citeseer 1996. |
| [23] | [ I. Yaniv and D. P. Foster, Graininess of judgment under uncertainty:An accuracyinformativeness trade-off, Journal of Experimental Psychology:General, 124(1995), 424-432. |
| [24] | [ L. Yu, K. K. Lai, S. Wang and W. Huang, A bias-variance-complexity trade-off framework for complex system modeling, In Computational Science and Its Applications-ICCSA 2006, Springer, 3980(2006), 518-527. |
| [25] | [ T. Zhou, Z. Kuscsik, J. Liu, M. Medo, J. R. Wakeling and Y. Zhang, Solving the apparent diversity-accuracy dilemma of recommender systems, Proceedings of the National Academy of Sciences, 107(2010), 4511-4515. |
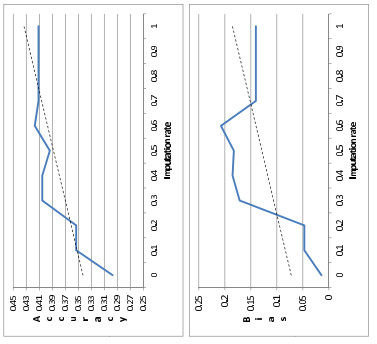
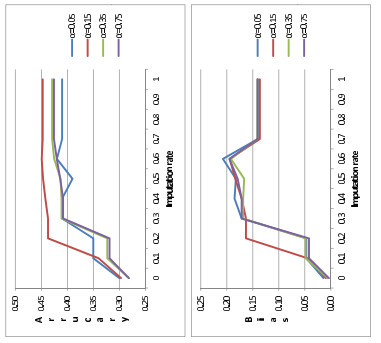
Figures(2) / Tables(4)

Wenxue Huang, Yuanyi Pan. On Balancing between Optimal and Proportional categorical predictions[J]. Big Data and Information Analytics, 2016, 1(1): 129-137. doi: 10.3934/bdia.2016.1.129









 DownLoad:
DownLoad: