Citation: Margarida Casadevall, Conxi Rodríguez-Prieto, Jordi Torres. The importance of the age when evaluating mercury pollution in fishes: the case of Diplodus sargus (Pisces, Sparidae) in the NW Mediterranean[J]. AIMS Environmental Science, 2017, 4(1): 17-26. doi: 10.3934/environsci.2017.1.17

| [1] |
Ferrantelli V, Giangrosso G, Cicero A, et al. (2012) Evaluation of mercury levels in pangasius and cod fillets traded in Sicily (Italy). Food Addit Contam, Part A, Chem Anal Control Expo Risk Assess 29: 1046-1051. doi: 10.1080/19440049.2012.675595

|
| [2] | EFSA, European food safety agency (2012) Mercury in food – EFSA updates advice on risks for public Health. Available from: https://www.efsa.europa.eu/en/press/news/121220. |
| [3] | FAO, Food and Agriculture Organization (2006) The international fish trade and world fisheries. Available from: http://www.fao.org/newsroom/common/ecg/1000301/en/enfactsheet2.pdf. |
| [4] | EFSA, European food safety agency (2004) Opinion of the Scientific Panel on contaminants in the food chain [CONTAM] related to mercury and methylmercury in food. EFSA J 34: 1-14. |
| [5] | Castoldi AF, Coccini T, Manzo L (2003) Neurotoxic and molecular effects of methylmercury in humans. Rev Environ Health 18: 19-31. |
| [6] | European Commission. Commission Regulation (EC) No. 221/ 2002 of 6 February 2002, amending Regulation (EC) No. 466/2001 setting maximum levels for certain contaminants in foodstuffs. Off. J. Eur. Communities: Legis 37: 4. Available from: http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2002:037:0004:0006:EN:PDF. |
| [7] | FAO/WHO FOOD STANDARDS PROGRAMME (2013) Discussion paper on the review of the guideline levels for methylmercury in fish and predatory fish. Codex committee on contaminants in food. Available from: ftp://ftp.fao.org/codex/meetings/cccf/cccf7/cf07_16e.pdf . |
| [8] |
Ralston NVC, Ralston CR, Blackwell JL, et al. (2008) Dietary and tissue selenium in relation to methylmercury toxicity. Neurotoxicology 29: 802-811. doi: 10.1016/j.neuro.2008.07.007
|
| [9] |
Peterson SA, Ralston NVC, Whanger PD, et al. (2009) Selenium and Mercury Interactions with Emphasis on Fish Tissue. Environ Bioindicator 4: 318-334. doi: 10.1080/15555270903358428
|
| [10] |
Burger J, Gochfeld M (2011) Mercury and selenium levels in 19 species of saltwater fish from New Jersey as a function of species, size, and season. Sci Total Environ 409: 1418-1429. doi: 10.1016/j.scitotenv.2010.12.034
|
| [11] |
Burger J, Gaines KF, Boring CS, et al. (2001) Mercury and selenium in fish from the Savannah River: species, trophic level, and locational differences. Environ Res 87: 108-118. doi: 10.1006/enrs.2001.4294
|
| [12] |
Monteiro LR, Lopes HD (1990) Mercury content of swordfish Xiphias gladiusin relation to length, weight, age and sex. Mar Pollut Bull 21: 293-296. doi: 10.1016/0025-326X(90)90593-W
|
| [13] |
Nakagawa R, Yumita Y, Hiromoto M (1997) Total mercury intake from fish and shellfish by Japanese people. Chemosphere 35: 2909-2913. doi: 10.1016/S0045-6535(97)00351-2
|
| [14] |
Storelli MM, Marcotrigiano GO (2000) Fish for human consumption: risk of contamination by mercury. Food Addit Contam 17: 1007-1011. doi: 10.1080/02652030050207792
|
| [15] |
Senn DB, Chesney EJ, Blum JD, et al. (2010) Stable Isotope (N, C, Hg) Study of Methylmercury Sources and Trophic Transfer in the Northern Gulf of Mexico. Environ Sci Technol 44: 1630-1637. doi: 10.1021/es902361j
|
| [16] |
Burger J, Gochfeld M (2006) Mercury in fish available in supermarkets in Illinois: are there regional differences? Sci Total Environ 367: 1010-1016. doi: 10.1016/j.scitotenv.2006.04.018
|
| [17] |
Kojadinovic J, Potier M, Le Corre M, et al. (2006) Mercury content in commercial pelagic fish and its risk assessment in the Western Indian Ocean. Sci Total Environ 366: 688-700. doi: 10.1016/j.scitotenv.2006.02.006
|
| [18] | Herreros MA, Iñigo-Nuñez S, Sánchez-Pérez E, et al. (2008) Contribution of fish consumption to heavy metals exposure in women of childbearing age from a Mediterranean country (Spain). Food Chem Toxicol 46: 1591-1595. |
| [19] | Naccari C, Cicero N, Ferrantelli V, et al. (2015) Toxic metals in pelagic, benthic and demersal fish species from Mediterranean FAO Zone 37. Bull Environ Contam Toxicol 95: 567-573. |
| [20] |
Torres J, Eira C, Miquel J, et al. (2015) Effect of Intestinal Tapeworm Clestobothrium crassiceps on concentrations of Toxic Elements and Selenium in European Hake Merluccius merluccius from the Gulf of Lion (Northwestern Mediterranean Sea). J Agr Food Chem 63: 9349-9356. doi: 10.1021/acs.jafc.5b03886
|
| [21] |
Storelli MM, Giacominelli-Stuffler R, Marcotrigiano GO (1998) Total mercury in muscle of benthic and pelagic fish from the South Adriatic Sea (Italy). Food Addit Contam 15: 876-883. doi: 10.1080/02652039809374724
|
| [22] |
Berge JA, Brevik EM (1996) Uptake of metals and persistent organochlorines in crabs (Cancer pagurus) and flounder (Platichthys flesus) from contaminated sediments: mesocosm and field experiments. Mar Pollut Bull 33: 46-55. doi: 10.1016/S0025-326X(96)00144-0
|
| [23] |
Burger J, Gaines KF, Gochfeld M (2001) Ethnic differences in risk from mercury among Savannah River fishermen. Risk Anal 21: 533-544. doi: 10.1111/0272-4332.213130
|
| [24] |
Casadevall M, Torres J, El Aoussimi A, et al. (2016) Pollutants and parasites in bycatch teleosts from south eastern Spanish Mediterranean’s fisheries: Concerns relating the foodstuff harnessing. Mar Poll Bull 104: 182-189. doi: 10.1016/j.marpolbul.2016.01.040
|
| [25] |
Burger J, Gochfeld M, Jeitner C, et al. (2014) Heavy metals in fish from the Aleutians: interspecific and locational differences. Environ Res 131: 119-130. doi: 10.1016/j.envres.2014.02.016
|
| [26] | Whitehead PJP, Bauchot ML, Hureau JC, et al. (eds.) (1986) Fishes of the North-eastern Atlantic and the Mediterranean. Paris: UNESCO, Vols. I-III: 1473 p. |
| [27] |
Sala E, Ballesteros E (1997) Partitioning of space and food resources by three fish of the genus Diplodus (Sparidae) in a Mediterranean rocky infralittoral ecosystem. Mar Ecol Prog Ser 152: 273-283. doi: 10.3354/meps152273
|
| [28] | Gordoa A, Molí B (1997) Age and growth of the sparids Diplodus vulgaris, D. sargus and D. annularis in adult populations and the differences in their juvenile growth patterns in the north-western Mediterranean Sea. Fish Res 33: 123-129. |
| [29] |
Abecasis D, Bentes L, Coelho R, et al. (2008) Ageing seabreams: A comparative study between scales and otoliths. Fish Res 89: 37-48. doi: 10.1016/j.fishres.2007.08.013
|
| [30] | Fischer W, Schneider M, Bauchot ML (1987) Fiches FAO d'identification des espèces pour les besoins de la pêche. Méditerranée et mer Noire vol. II Vertébrés. Rome: FAO: 763-1529. |
| [31] | UNEP (2013) Global Mercury Assessment 2013: Sources, Emissions, Releases and Environmental Transport. UNEP Chemical Branch, Geneva, Switzerland, p. 32. |
| [32] |
Durrieu de Madron X, Guieu C, Sempéré R, et al. (2011) Marine ecosystems’ responses to climatic and anthropogenic forcing in the Mediterranean. Prog Oceanogr 91: 97-166. doi: 10.1016/j.pocean.2011.02.003
|
| [33] | Ralston NVC (2008) Selenium health benefit values as seafood safety criteria. Eco Health 5: 442-455. |
| [34] | Rosecchi E (1983) Régime alimentaire du pageot, Pagellus erythrinus L., 1758, (Pisces, Sparidae) dans le Gulf de Lion. Cybium 7: 17-29. |
| [35] |
Juan-Jordá MJ, Mosqueira I, Freire J, et al. (2013) The Conservation and Management of Tunas and Their Relatives: Setting Life History Research Priorities. PLoS ONE 8: e70405. doi: 10.1371/journal.pone.0070405
|
| [36] |
Santamaria N, Bello G, Corriero A, et al. (2009) Age and growth of Atlantic bluefin tuna, Thunnus thynnus (Osteichthyes: Thunnidae), in the Mediterranean Sea. J Appl Ichthyol 25: 38-45. doi: 10.1111/j.1439-0426.2009.01191.x
|
| [37] |
Dixon R, Jones B (1994) Mercury concentrations in stomach contents and muscle of five fish species from the north east coast of England. Mar Poll Bull 28: 741-745. doi: 10.1016/0025-326X(94)90333-6
|
| [38] |
Lansen P, Leermakers M, Baeyens W (1991) Determination of methylmercury in fish by headspace-gas chromatography with microwave-induced-plasma detection. Water Air Soil Poll 56: 103-115. doi: 10.1007/BF00342265
|
| [39] |
Pellegrini D, Barghigiani C (1989) Feeding behaviour and mercury content in two flat fish in the northern Tyrrhenian Sea. Mar Poll Bull 20: 443-447. doi: 10.1016/0025-326X(89)90064-7
|
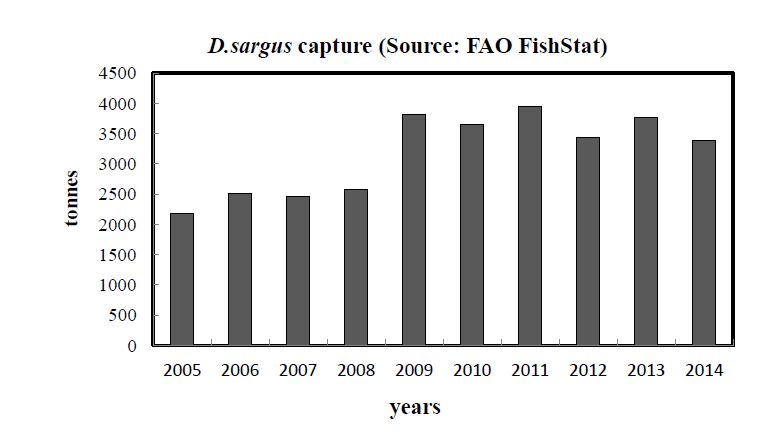
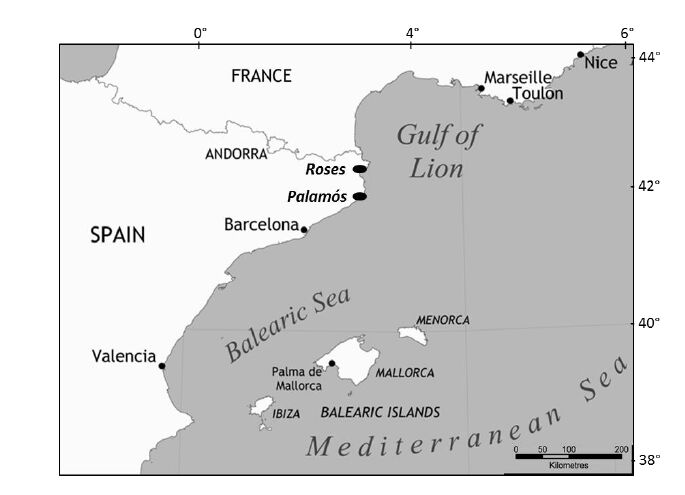
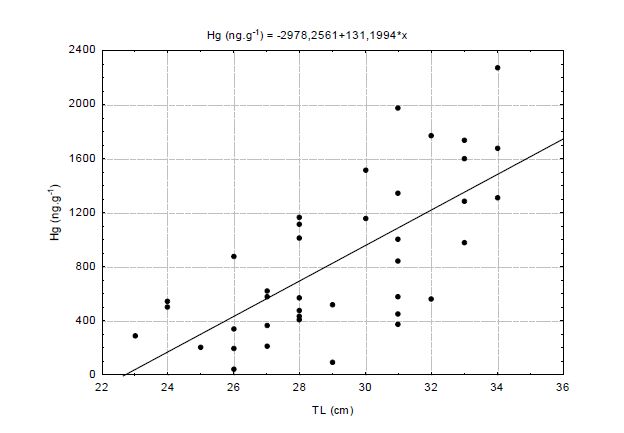
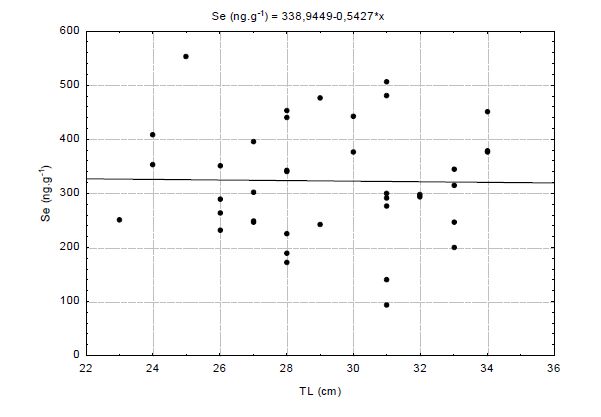
Figures(5) / Tables(1)

Margarida Casadevall, Conxi Rodríguez-Prieto, Jordi Torres. The importance of the age when evaluating mercury pollution in fishes: the case of Diplodus sargus (Pisces, Sparidae) in the NW Mediterranean[J]. AIMS Environmental Science, 2017, 4(1): 17-26. doi: 10.3934/environsci.2017.1.17







 DownLoad:
DownLoad: