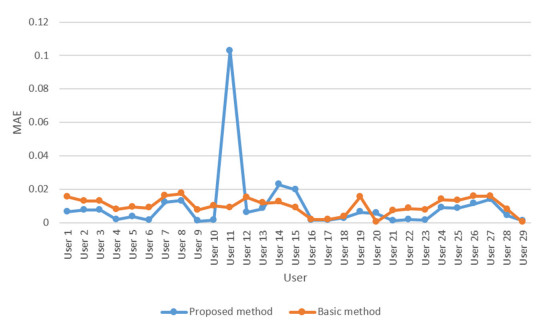
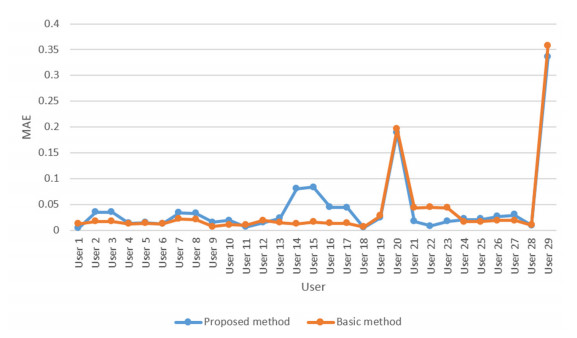
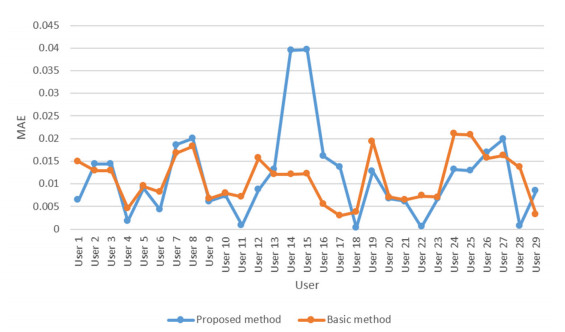
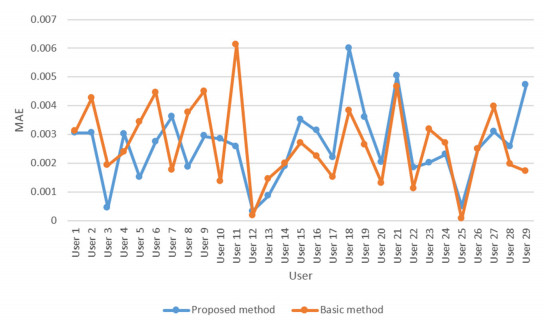
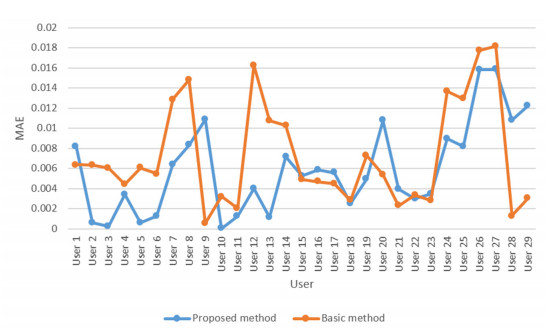
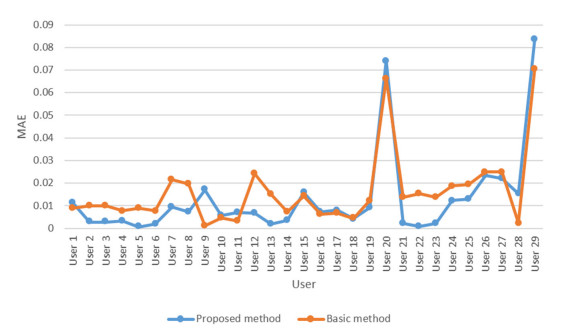
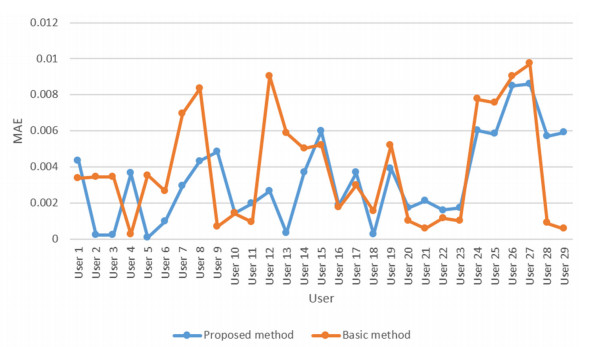
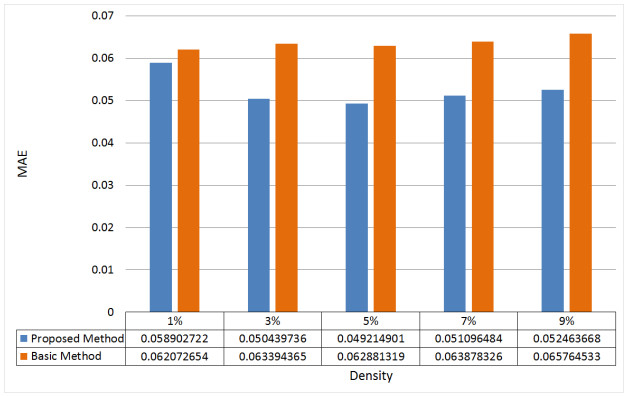
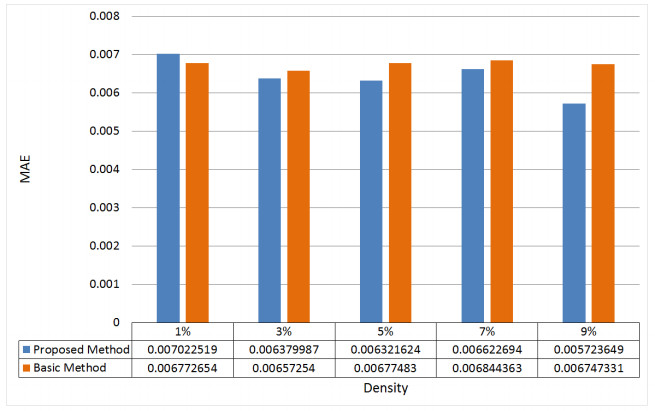
Cloud computing is an attractive model that provides users with a variety of services. Thus, the number of cloud services on the market is growing rapidly. Therefore, choosing the proper cloud service is an important challenge. Another major challenge is the availability of diverse cloud services with similar performance, which makes it difficult for users to choose the cloud service that suits their needs. Therefore, the existing service selection approaches is not able to solve the problem, and cloud service recommendation has become an essential and important need. In this paper, we present a new way for context-aware cloud service recommendation. Our proposed method seeks to solve the weakness in user clustering, which itself is due to reasons such as 1) lack of full use of contextual information such as cloud service placement, and 2) inaccurate method of determining the similarity of two vectors. The evaluation conducted by the WSDream dataset indicates a reduction in the cloud service recommendation process error rate. The volume of data used in the evaluation of this paper is 5 times that of the basic method. Also, according to the T-test, the service recommendation performance in the proposed method is significant.
Citation: Hossein Habibi, Abbas Rasoolzadegan, Amir Mashmool, Shahab S. Band, Anthony Theodore Chronopoulos, Amir Mosavi. SaaSRec+: a new context-aware recommendation method for SaaS services[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1471-1495. doi: 10.3934/mbe.2022068
Cloud computing is an attractive model that provides users with a variety of services. Thus, the number of cloud services on the market is growing rapidly. Therefore, choosing the proper cloud service is an important challenge. Another major challenge is the availability of diverse cloud services with similar performance, which makes it difficult for users to choose the cloud service that suits their needs. Therefore, the existing service selection approaches is not able to solve the problem, and cloud service recommendation has become an essential and important need. In this paper, we present a new way for context-aware cloud service recommendation. Our proposed method seeks to solve the weakness in user clustering, which itself is due to reasons such as 1) lack of full use of contextual information such as cloud service placement, and 2) inaccurate method of determining the similarity of two vectors. The evaluation conducted by the WSDream dataset indicates a reduction in the cloud service recommendation process error rate. The volume of data used in the evaluation of this paper is 5 times that of the basic method. Also, according to the T-test, the service recommendation performance in the proposed method is significant.

| [1] | P. Mell, T. Grance, The NIST Definition of Cloud Computing, 2011. Available from: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf. |
| [2] | B. P. Rimal, E. Choi, I. Lumb, A taxonomy and survey of cloud computing systems, in 2009 Fifth International Joint Conference on INC, IMS and IDC, (2009), 44-51. doi: 10.1109/NCM.2009.218. |
| [3] |
F. Aznoli, N. J. Navimipour, Cloud services recommendation: reviewing the recent advances and suggesting the future research directions, J. Netw. Comput. Appl., 77 (2017), 73-86. doi: 10.1016/j.jnca.2016.10.009. doi: 10.1016/j.jnca.2016.10.009

|
| [4] |
D. Fang, X. Liu, I. Romdhani, P. Jamshidi, C. Pahl, An agility-oriented and fuzziness-embedded semantic model for collaborative cloud service search, retrieval and recommendation, Futur. Gener. Comput. Syst., 56 (2016), 11-26. doi: 10.1016/j.future.2015.09.025. doi: 10.1016/j.future.2015.09.025
|
| [5] |
Y. M. Afify, I. F. Moawad, N. L. Badr, M. F. Tolba, A personalized recommender system for SaaS services, Concurr. Comput., 29 (2017), e3877. doi: 10.1002/cpe.3877. doi: 10.1002/cpe.3877
|
| [6] |
Y. Jiang, D. Tao, Y. Liu, J. Sun, H. Ling, Cloud service recommendation based on unstructured textual information, Futur. Gener. Comput. Syst., 97 (2019), 387-396. doi: 10.1016/j.future.2019.02.063. doi: 10.1016/j.future.2019.02.063
|
| [7] |
L. Qi, X. Zhang, W. Dou, Q. Ni, A distributed locality-sensitive hashing-based approach for cloud service recommendation from multi-source data, IEEE J. Sel. Areas Commun., 35 (2017), 2616-2624. doi: 10.1109/JSAC.2017.2760458. doi: 10.1109/JSAC.2017.2760458
|
| [8] |
M. Zhang, R. Ranjan, M. Menzel, S. Nepal, P. Strazdins, W. Jie, et al., An infrastructure service recommendation system for cloud applications with real-time QoS requirement constraints', IEEE Syst. J., 11 (2017), 2960-2970. doi: 10.1109/JSYST.2015.2427338. doi: 10.1109/JSYST.2015.2427338
|
| [9] | R. B. Bohn, J. Messina, F. Liu, J. Tong, J. Mao, NIST cloud computing reference architecture, in 2011 IEEE World Congress on Services, (2011), 594-596. doi: 10.1109/SERVICES.2011.105. |
| [10] | H. Schütze, C. D. Manning, P. Raghavan, Introduction to Information Retrieval, Cambridge University Press, 2008. |
| [11] |
X. Fan, Y. Hu, Z. Zheng, Y. Wang, P. Brézillon, W. Chen, CASR-TSE: context-aware web services recommendation for modeling weighted temporal-spatial effectiveness, IEEE Trans. Serv. Comput., 14 (2017), 58-70. doi: 10.1109/TSC.2017.2782793. doi: 10.1109/TSC.2017.2782793
|
| [12] | U. Shardanand, P. Maes, Social information filtering: algorithms for automating "word of mouth", in Proceedings of the SIGCHI conference on Human factors in computing systems, 1995, (1995), 210-217. doi: 10.1145/223904.223931. |
| [13] |
X. Wu, B. Cheng, J. Chen, Collaborative filtering service recommendation based on a novel similarity computation method, IEEE Trans. Serv. Comput., 10 (2015), 352-365. doi: 10.1109/TSC.2015.2479228. doi: 10.1109/TSC.2015.2479228
|
| [14] |
M. Deshpande, G. Karypis, Item-based top-N recommendation algorithms, ACM Trans. Inf. Syst., 22 (2004), 143-177. doi: 10.1145/963770.963776. doi: 10.1145/963770.963776
|
| [15] |
H. Sun, Z. Zheng, J. Chen, M. R. Lyu, Personalized web service recommendation via normal recovery collaborative filtering, IEEE Trans. Serv. Comput., 6 (2013), 573-579. doi: 10.1109/TSC.2012.31. doi: 10.1109/TSC.2012.31
|
| [16] |
H. Mezni, T. Abdeljaoued, A cloud services recommendation system based on Fuzzy Formal Concept Analysis, Data Knowl. Eng., 116 (2018), 100-123. doi: 10.1016/j.datak.2018.05.008. doi: 10.1016/j.datak.2018.05.008
|
| [17] |
Q. Wei, W. Wang, G. Zhang, T. Shao, Privacy-aware cross-cloud service recommendations based on Boolean historical invocation records, Eur. J. Wirel. Commun. Netw., 2019 (2019), 1-8. doi: 10.1186/s13638-018-1318-8. doi: 10.1186/s13638-018-1318-8
|
| [18] | L. Qi, H. Xiang, W. Dou, C. Yang, Y. Qin, X. Zhang, Privacy-preserving distributed service recommendation based on locality-sensitive hashing, in 2017 IEEE International conference on web services (ICWS), (2017), 49-56. |
| [19] |
Z. Zheng, H. Ma, M. R. Lyu, I. King, Qos-aware web service recommendation by collaborative filtering, IEEE Trans. Serv. Comput., 4 (2010), 140-152. doi: 10.1109/TSC.2010.52. doi: 10.1109/TSC.2010.52
|
| [20] |
C. Zhang, Z. Li, T. Li, Y. Han, C. Wei, Y. Cheng, et al., P-CSREC: a new approach for personalized cloud service recommendation, IEEE Access, 6 (2018), 35946-35956. doi: 10.1109/ACCESS.2018.2847631. doi: 10.1109/ACCESS.2018.2847631
|
| [21] |
Z. Y. Chai, Y. L. Li, Y. M. Han, S. F. Zhu, Recommendation system based on singular value decomposition and multi-objective immune optimization, IEEE Access, 7 (2018), 6060-6071. doi: 10.1109/ACCESS.2018.2842257. doi: 10.1109/ACCESS.2018.2842257
|
| [22] |
L. Guo, D. Mu, X. Cai, G. Tian, F. Hao, Personalized QoS prediction for service recommendation with a service-oriented tensor model, IEEE Access, 7 (2019), 55721-55731. doi: 10.1109/ACCESS.2019.2912505. doi: 10.1109/ACCESS.2019.2912505
|
| [23] | A. S. B. Priya, R. S. Bhuvaneswaran, Cloud service recommendation system based on clustering trust measures in multi-cloud environment, J. Ambient Intell. Humaniz. Comput., 2020 (2020), 1-10. |
| [24] |
K. Indira, M. K. K. Devi, Multi cloud based service recommendation system using DBSCAN algorithm, Wirel. Pers. Commun., 115 (2020), 1019-1034. doi: 10.1007/s11277-020-07609-3. doi: 10.1007/s11277-020-07609-3
|
| [25] | R. Hentschel, S. Strahringer, A broker-based framework for the recommendation of cloud services: a research proposal, in Conference on e-Business, e-Services and e-Society, (2020), 409-415. doi: 10.1007/978-3-030-44999-5_34. |
| [26] |
Z. Zheng, Y. Zhang, M. R. Lyu, Investigating QoS of real-world web services, IEEE Trans. Serv. Comput., 7 (2014), 32-39. doi: 10.1109/TSC.2012.34. doi: 10.1109/TSC.2012.34
|
| [27] |
S. Ding, Y. Li, D. Wu, Y. Zhang, S. Yang, Time-aware cloud service recommendation using similarity-enhanced collaborative filtering and ARIMA model, Decis. Support Syst., 107 (2018), 103-115. doi: 10.1016/j.dss.2017.12.012. doi: 10.1016/j.dss.2017.12.012
|
Figures(13) / Tables(8)

Hossein Habibi, Abbas Rasoolzadegan, Amir Mashmool, Shahab S. Band, Anthony Theodore Chronopoulos, Amir Mosavi. SaaSRec+: a new context-aware recommendation method for SaaS services[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1471-1495. doi: 10.3934/mbe.2022068







 DownLoad:
DownLoad: