Citation: Amy Mizen, Richard Fry, Daniel Grinnell, Sarah E. Rodgers. Quantifying the Error Associated with Alternative GIS-based Techniques to Measure Access to Health Care Services[J]. AIMS Public Health, 2015, 2(4): 746-761. doi: 10.3934/publichealth.2015.4.746

| [1] | Meyer SB, Luong TCN, Mamerow L, Ward PR. (2013) Inequities in access to healthcare: analysis of national survey data across six Asia-Pacific countries. BMC Health Serv. Res 13: p238. |
| [2] | Ruiz-Casares M, Rousseau C, Derluyn I, Watters C, Crépeau F. (2010) Right and access to healthcare for undocumented children: addressing the gap between international conventions and disparate implementations in North America and Europe. Soc. Sci. Med.70: p329-36. |
| [3] | Stronks K, Ravelli a C, Reijneveld S a. (2001) Immigrants in the Netherlands: equal access for equal needs? J. Epidemiol. Community Health 55: p701-7. |
| [4] | Norredam M, Nielsen SS, Krasnik A. (2010) Migrants' utilization of somatic healthcare services in Europe--a systematic review. Eur. J. Public Health20: p555-63. |
| [5] | Meng Q, Xu L, Zhang Y et al. (2012) Trends in access to health services and financial protection in China between 2003 and 2011: a cross-sectional study. Lancet 379: p805-14. |
| [6] | Gulliford M, Figueroa-Munoz J, Morgan M et al. (2002) What does ‘access to health care’ mean? J. Health Serv. Res. Policy7: p186-8. |
| [7] | Hu R, Dong S, Zhao Y, Hu H, Li Z. (2013) Assessing potential spatial accessibility of health services in rural China: a case study of Donghai County. Int. J. Equity Health 12: p35. |
| [8] | Priorities for research on equity and health: Implications for global and national priority setting and the role of WHO to take the health equity research agenda forward. World Health Organisation, 2010. Available from: http://www.who.int/social_determinants/implementation/Thefinalreportnovember2010.pdf |
| [9] | Apparicio P, Abdelmajid M, Riva M, Shearmur R. (2008) Comparing alternative approaches to measuring the geographical accessibility of urban health services: Distance types and aggregation-error issues. Int. J. Health Geogr.7: p7. |
| [10] | Luo W. (2004) Using a GIS-based floating catchment method to assess areas with shortage of physicians. Health & Place10: p1-11. |
| [11] | Lovett A, Haynes R, Sünnenberg G, Gale S. (2002) Car travel time and accessibility by bus to general practitioner services: a study using patient registers and GIS. Soc. Sci. Med. 55: p97-111. |
| [12] | Jordan H, Roderick P, Martin D, Barnett S. (2004) Distance, rurality and the need for care: access to health services in South West England. Int. J. Health Geogr.3: p21. |
| [13] | Gatrell AC, Wood DJ. (2012) Variation in geographic access to specialist inpatient hospices in England and Wales. Health & Place18: p832-40. |
| [14] | Pearce J, Witten K, Bartie P. (2006) Neighbourhoods and health: a GIS approach to measuring community resource accessibility. J. Epidemiol. Community Health60: p389-95. |
| [15] | Gu W, Wang X, McGregor SE. (2010) Optimization of preventive health care facility locations. Int. J. Health Geogr.9: p17. |
| [16] | Wang L, Roisman D. (2011) Modeling Spatial Accessibility of Immigrants to Culturally Diverse Family Physicians. Prof. Geogr.63: p73-91. |
| [17] | Higgs G. (2009) The role of GIS for health utilization studies: literature review. Heal. Serv. Outcomes Res. Methodol.9: p84-99. |
| [18] | Higgs G, Gould M. (2001) Is there a role for GIS in the ‘new NHS’? Health & Place7: p247-59. |
| [19] | Luo W, Qi Y. (2009) An enhanced two-step floating catchment area (E2SFCA) method for measuring spatial accessibility to primary care physicians. Health & Place15: p1100-7. |
| [20] | Langford M, Higgs G. (2006) Measuring potential access to primary healthcare services: The influence of alternative spatial representations of population. Prof. Geogr.58: p294-306. |
| [21] | Using Geographic Information Systems for Health Research. Application of Geogrpahic Information Systems, 2012. Available from:http://www.intechopen.com/books/application-of-geographic-information-systems/using-geographic-information-systems-for-health-research |
| [22] | Delamater PL, Messina JP, Shortridge AM, Grady SC. (2012) Measuring geographic access to health care: raster and network-based methods. 11: p15-33. |
| [23] | Boscoe FP, Henry K a, Zdeb MS. (2012) A Nationwide Comparison of Driving Distance Versus Straight-Line Distance to Hospitals. Prof. Geogr.64: p37-41. |
| [24] | Goovaerts P. (2009) Combining area-based and individual-level data in the geostatistical mapping of late-stage cancer incidence. 1: p61-71. |
| [25] | Rodgers SE, Demmler JC, Dsilva R, Lyons RA. (2012) Protecting health data privacy while using residence-based environment and demographic data. Health & Place 18: p209-17. |
| [26] | Omer I. (2006) Evaluating accessibility using house-level data: A spatial equity perspective. Comput. Environ. Urban Syst.30: p254-74. |
| [27] | Ford D V, Jones KH, Verplancke J-P et al. (2009) The SAIL Databank: building a national architecture for e-health research and evaluation. BMC Health Serv. Res.9: p157. |
| [28] | Luo L, McLafferty S, Wang F. (2010) Analyzing spatial aggregation error in statistical models of late-stage cancer risk: a Monte Carlo simulation approach. Int. J. Health Geogr. 9: p51. |
| [29] | Portnov B a, Dubnov J, Barchana M. (2007) On ecological fallacy, assessment errors stemming from misguided variable selection, and the effect of aggregation on the outcome of epidemiological study. J. Expo. Sci. Environ. Epidemiol.17: p106-21. |
| [30] | Boone JE, Gordon-Larsen P, Stewart JD, Popkin BM. (2008) Validation of a GIS facilities database: quantification and implications of error. Ann. Epidemiol.18: p371-7. |
| [31] | Population. Swansea Council, 2013 Available from: http://www.swansea.gov.uk/population. |
| [32] | Population Density. Swansea - UK Census Data, 2011 Available from: http://www.ukcensusdata.com/swansea-w06000011/population-density-qs102ew#sthash.bRvQyPNs.YEwrd2zc.dpbs. |
| [33] | NHS Wales Informatics Service - an Official NHS Wales website. NHS Wales Informatics Service, 2015. Available from: http://www.wales.nhs.uk/sitesplus/956/home |
| [34] | Points of Interest. Ordnance Survey, 2014 Available from: http://www.ordnancesurvey.co.uk/business-and-government/products/points-of-interest.html. |
| [35] | AddressBase Premium. Ordnance Survey, 2014 Available from: http://www.ordnancesurvey.co.uk/business-and-government/products/addressbase-premium.html. |
| [36] | Code-Point with polygons - locates every postcode unit in the UK with precision. Ordnance Survey, 2014 Available from: http://www.ordnancesurvey.co.uk/business-and-government/products/code-point-with-polygons.html |
| [37] | Rural and Urban Area Classification. ONS, 2004 Available from:http://www.ons.gov.uk/ons/guide-method/geography/products/area-classifications/rural-urban-definition-and-la/rural-urban-definition--england-and-wales-/index.html. |
| [38] | OS MasterMap ITN Layer. Ordnance Survey, 2014 Available from:http://www.ordnancesurvey.co.uk/business-and-government/products/itn-layer.html. |
| [39] | 2011 Census geography products for England and Wales. ONS, 2014http://www.ons.gov.uk/ons/guide-method/geography/products/census/index.html. |
| [40] | Goovaerts P. (2013) Geostatistical Analysis of Health Data with Different Levels of Spatial Aggregation. Spat Spat. Epidemiol.3: p83-92. |
| [41] | Hewko J, Smoyer-Tomic KE, Hodgson MJ. (2002) Measuring neighbourhood spatial accessibility to urban amenities: does aggregation error matter? Environ. Plan. A 34: p1185-206. |
| [42] | McLafferty SL. (2003) GIS and health care. Annu. Rev. Public Health24: p25-42. |
| [43] | Watt IS, Franks AJ, Sheldon T a. (1994) Health and health care of rural populations in the UK: is it better or worse? J. Epidemiol. Community Health 48: p16-21. |
| [44] | Campbell NC, Elliott a M, Sharp L et al. (2000) Rural factors and survival from cancer: analysis of Scottish cancer registrations. Br. J. Cancer 82: p1863-6. |
| [45] | Whitehouse C. (1985) Effect of distance from surgery on consultation rates. 290: p359-62. |
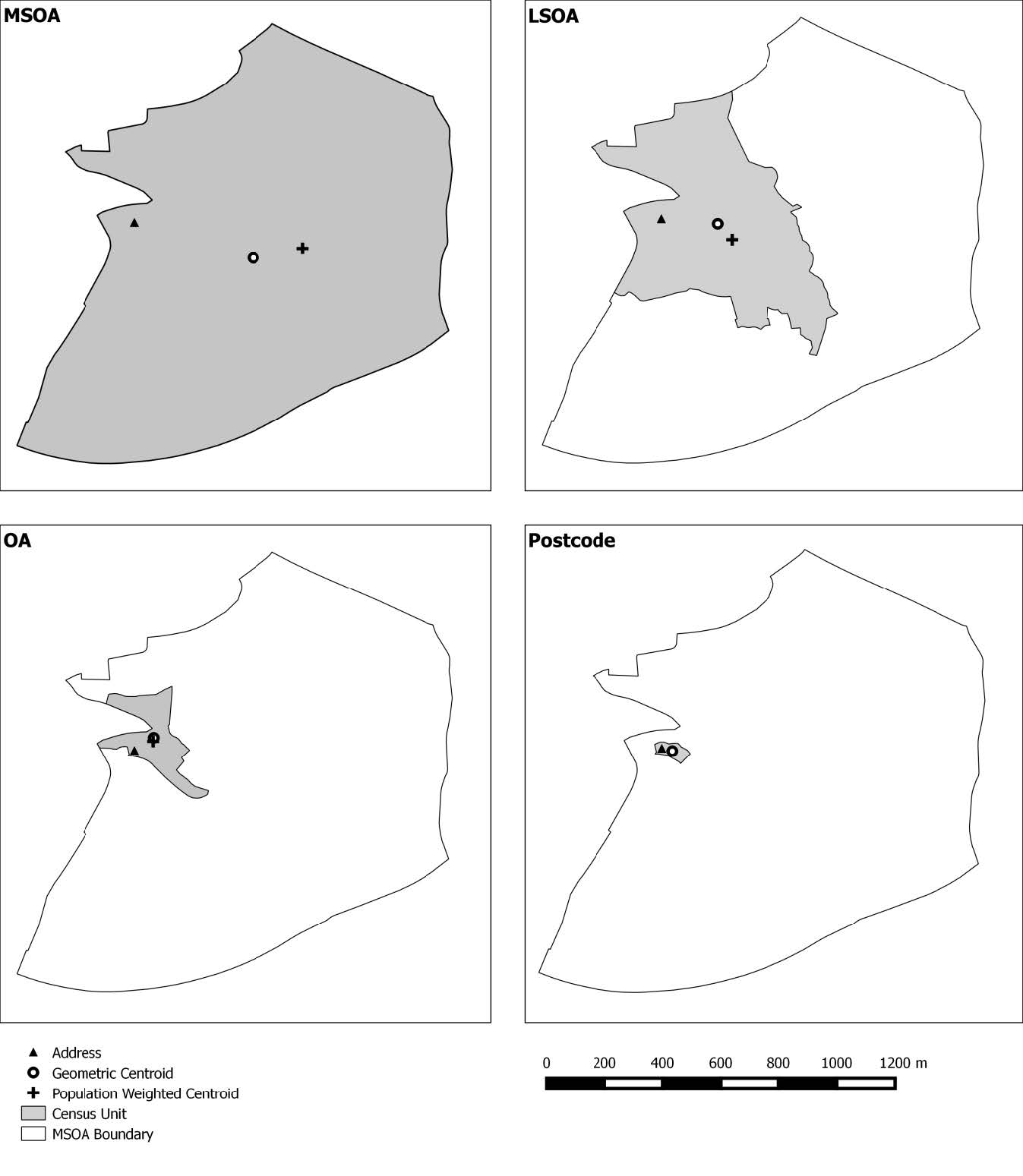
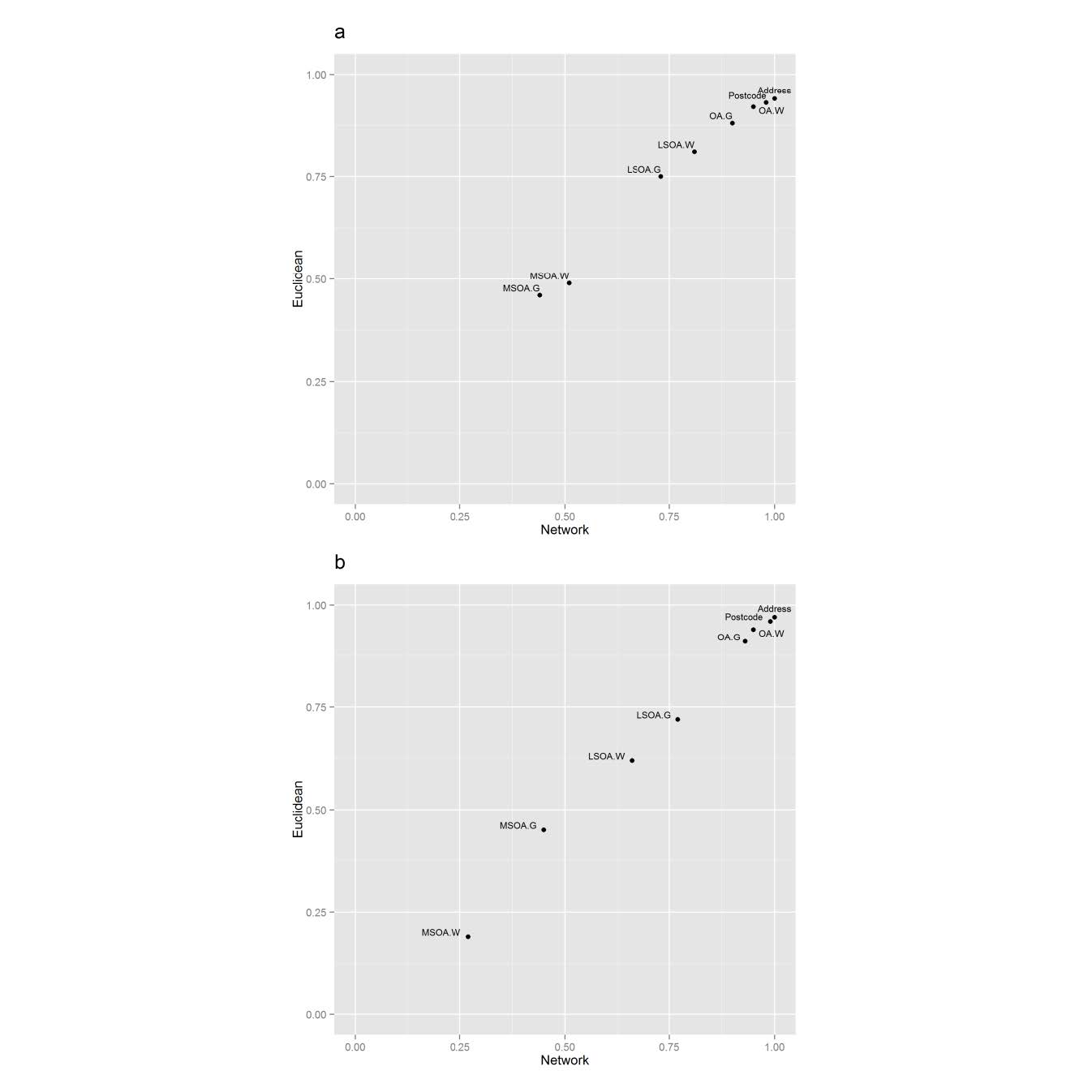
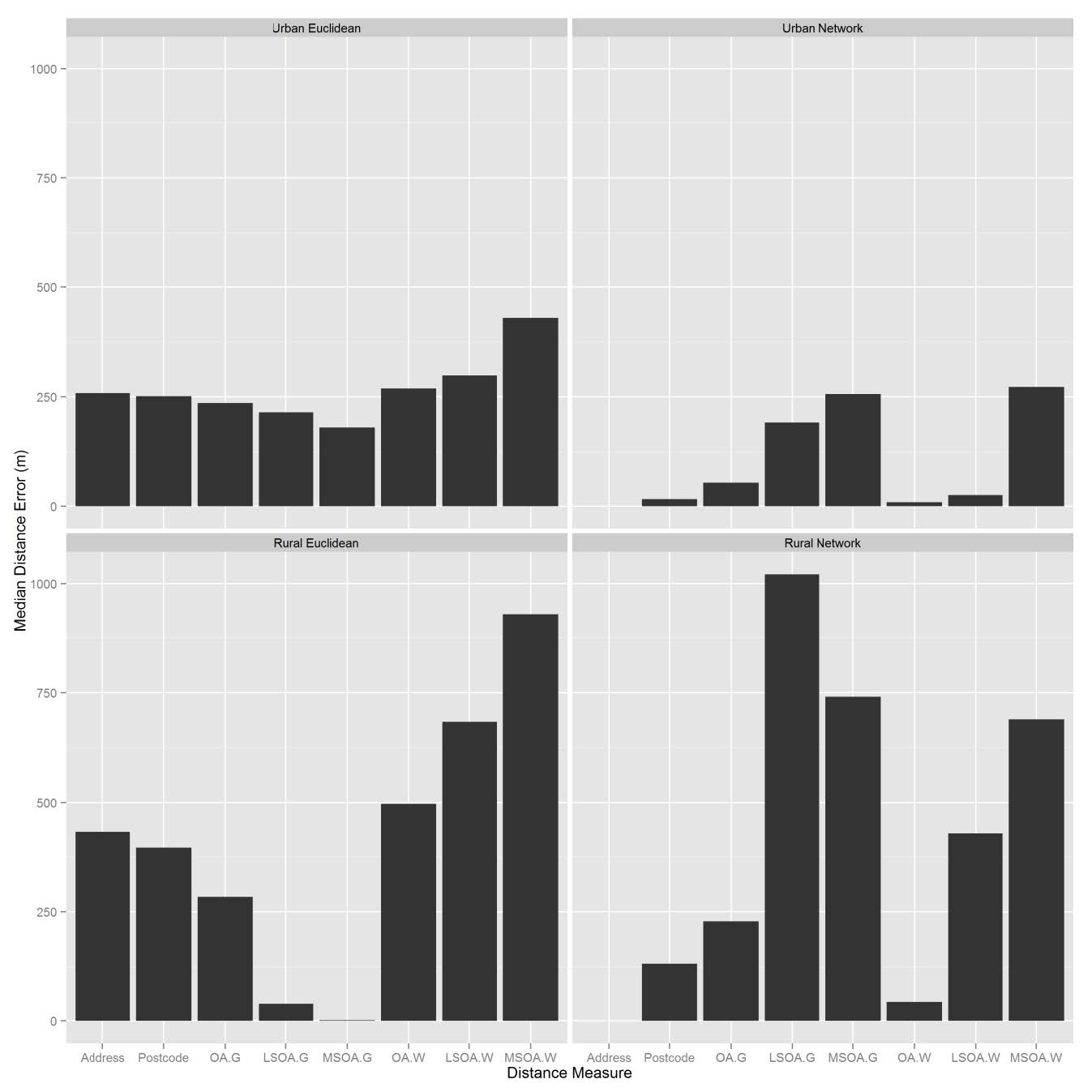
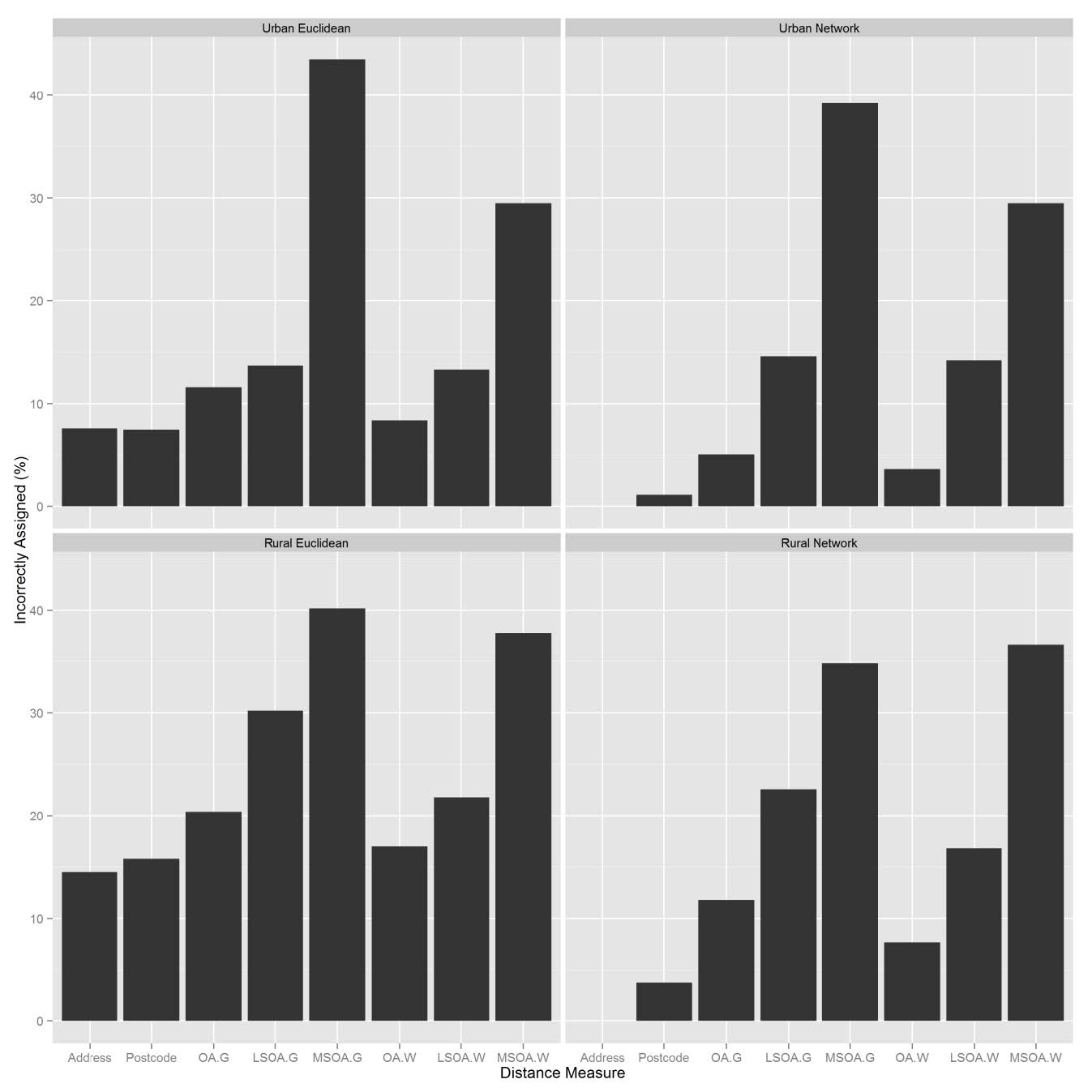
Figures(4) / Tables(3)

Amy Mizen, Richard Fry, Daniel Grinnell, Sarah E. Rodgers. Quantifying the Error Associated with Alternative GIS-based Techniques to Measure Access to Health Care Services[J]. AIMS Public Health, 2015, 2(4): 746-761. doi: 10.3934/publichealth.2015.4.746







 DownLoad:
DownLoad: