Citation: Jessie-Lee D McIsaac, Sherry Jarvis, Dana Lee Olstad, PJ Naylor, Laurene Rehman, Sara FL Kirk. Voluntary nutrition guidelines to support healthy eating in recreation and sports settings are ineffective: findings from a prospective study[J]. AIMS Public Health, 2018, 5(4): 411-420. doi: 10.3934/publichealth.2018.4.411

| [1] |
Penney TL, Almiron-Roig E, Shearer C, et al. (2014) Modifying the food environment for childhood obesity prevention: challenges and opportunities. Proc Nutr Soc 73: 226–236. doi: 10.1017/S0029665113003819

|
| [2] |
Story M, Kaphingst KM, Robinson-O'Brien R, et al. (2008) Creating healthy food and eating environments: policy and environmental approaches. Ann Rev Public Health 29: 253–272. doi: 10.1146/annurev.publhealth.29.020907.090926
|
| [3] |
Swinburn BA, Sacks G, Hall KD, et al. (2011) The global obesity pandemic: shaped by global drivers and local environments. Lancet 378: 804–814. doi: 10.1016/S0140-6736(11)60813-1
|
| [4] |
Dobbinson SJ, Hayman JA, Livingston PM (2006) Prevalence of health promotion policies in sports clubs in Victoria, Australia. Health Promot Int 21: 121–129. doi: 10.1093/heapro/dak001
|
| [5] | Priest N, Armstrong R, Doyle J, et al. (2008) Policy interventions implemented through sporting organisations for promoting healthy behaviour change. Cochrane Database Syst Rev 16: CD004809. |
| [6] |
Thomas HM, Irwin JD (2010) Food choices in recreation facilities: operators' and patrons' perspectives. Can J Diet Pract Res 71: 180–185. doi: 10.3148/71.4.2010.180
|
| [7] |
Vander Wekken S, Sørensen S, Meldrum J, et al. (2012) Exploring industry perspectives on implementation of a provincial policy for food and beverage sales in publicly funded recreation facilities. Health Policy Amst Neth 104: 279–287. doi: 10.1016/j.healthpol.2011.11.014
|
| [8] | Drygas W, Ruszkowska J, Philpott M, et al. (2011) Good practices and health policy analysis in European sports stadia: results from the "Healthy Stadia" project. Health Promot Int 28: 157–165. |
| [9] |
Naylor PJ, Bridgewater L, Purcell M, et al. (2010) Publicly Funded Recreation Facilities: Obesogenic Environments for Children and Families? Int J Environ Res Public Health 7: 2208–2221. doi: 10.3390/ijerph7052208
|
| [10] | Naylor PJ, Vander Wekken S, Trill D, et al. (2010) Facilitating Healthier Food Environments in Public Recreation Facilities: Results of a Pilot Project in British Columbia, Canada. J Park Recreat Adm 28: 37–58. |
| [11] | Olstad DL, Lieffers JRL, Raine KD, et al. (2011) Implementing the Alberta nutrition guidelines for children and youth in a recreational facility. Can J Diet Pract Res 72: 177. |
| [12] |
Olstad DL, Raine KD, McCargar LJ (2012) Adopting and implementing nutrition guidelines in recreational facilities: Public and private sector roles. A multiple case study. BMC Public Health 12: 376. doi: 10.1186/1471-2458-12-376
|
| [13] |
Kelly B, Chapman K, King L, et al. (2008) Double standards for community sports: promoting active lifestyles but unhealthy diets. J Aust Assoc Health Promot Prof 19: 226–228. doi: 10.1071/HE08226
|
| [14] |
Olstad DL, Downs SM, Raine KD, et al. (2011) Improving children's nutrition environments: a survey of adoption and implementation of nutrition guidelines in recreational facilities. BMC Public Health 11: 423. doi: 10.1186/1471-2458-11-423
|
| [15] |
Chircop A, Shearer C, Pitter R, et al. (2015) Privileging physical activity over healthy eating: "Time" to Choose? Health Promot Int 30: 418–426. doi: 10.1093/heapro/dat056
|
| [16] | Province of Nova Scotia, Healthy eating in recreation and sport settings guidelines, 2015. Available from: https://thrive.novascotia.ca/node/83 |
| [17] | Province of Nova Scotia, Food and Nutrition in Nova Scotia Schools, 2008. Available from: http://www.ednet.ns.ca/healthy_eating/ |
| [18] | Government of Canada, Canadian Nutrient File, 2018. Available from https://food-nutrition.canada.ca/cnf-fce/index-eng.jsp |
| [19] | Province of Nova Scotia, Thrive! A plan for a healthier Nova Scotia, 2012. Available from: www.thrive.novascotia.ca |
| [20] |
Meyers D, Durlak J, Wandersman A (2012) The quality implementation framework: A synthesis of critical steps in the implementation process. Am J Community Psychol 50: 462–480. doi: 10.1007/s10464-012-9522-x
|
| [21] |
Seeman N (2008) The prevention moment: A post-partisan approach to obesity policy. Healthc Pap 9: 22–33. doi: 10.12927/hcpap.2008.20178
|
| [22] |
McIssac JL, Jarvis S, Spencer R, et al. (2018) "A tough sell": Findings from a qualitative analysis in the provision of healthy foods in recreation and sport settings. Health Prom Chronic Dis Prev in Canada 38: 18–22. doi: 10.24095/hpcdp.38.1.04
|
| [23] |
Thomas HM, Irwin JD (2010) Food choices in recreation facilities: operators' and patrons' perspectives. Can J Diet Pract Res 71: 180–185. doi: 10.3148/71.4.2010.180
|
| [24] |
Van Hulst A, Barnett TA, Déry V, et al. (2013) Health-promoting vending machines: evaluation of a pediatric hospital intervention. Can J Diet Pract Res 74: 28–34. doi: 10.3148/74.1.2013.28
|
| [25] |
Elliott C (2011) "It's junk food and chicken nuggets": Children's perspectives on "kids" food' and the question of food classification. J Consum Behav 10: 133–140. doi: 10.1002/cb.360
|
| [26] | Ludvigsen A, Scott S (2009) Real Kids Don't Eat Quiche: What Food Means to Children. Food Cult Soc Int J Multidiscip Res 12: 417–436. |
| [27] |
Sallis JF, Glanz K (2009) Physical activity and food environments: solutions to the obesity epidemic. Milbank Q 87: 123–154. doi: 10.1111/j.1468-0009.2009.00550.x
|
| [28] | Kelly B, Baur LA, Bauman AE, et al. (2010) Examining opportunities for promotion of healthy eating at children's sports clubs. Aus New Zeal J Pub Health 4: 583–588. |
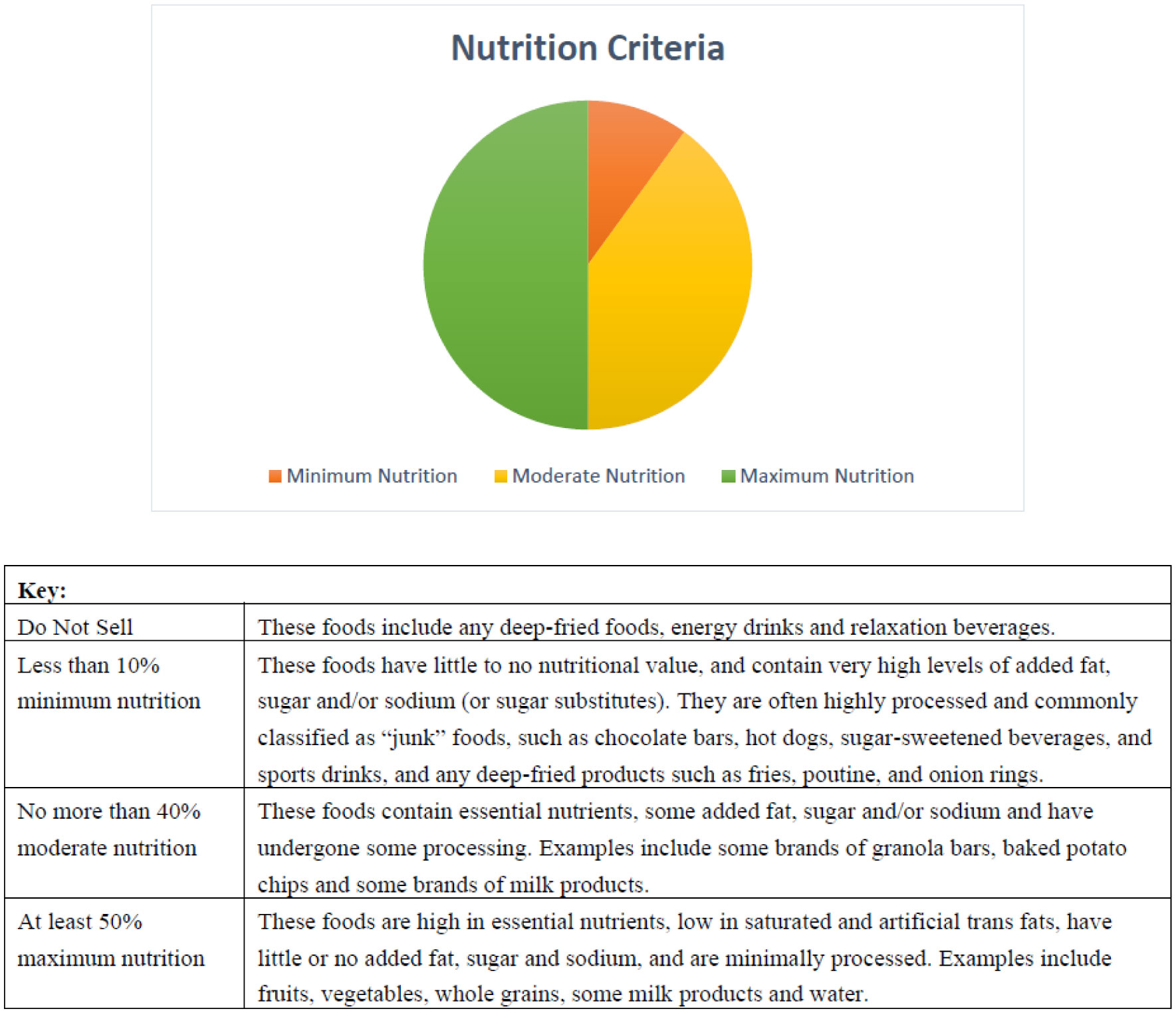
Figures(1) / Tables(1)

Jessie-Lee D McIsaac, Sherry Jarvis, Dana Lee Olstad, PJ Naylor, Laurene Rehman, Sara FL Kirk. Voluntary nutrition guidelines to support healthy eating in recreation and sports settings are ineffective: findings from a prospective study[J]. AIMS Public Health, 2018, 5(4): 411-420. doi: 10.3934/publichealth.2018.4.411







 DownLoad:
DownLoad: