Citation: Beth Ravit, Frank Gallagher, James Doolittle, Richard Shaw, Edwin Muñiz, Richard Alomar, Wolfram Hoefer, Joe Berg, Terry Doss. Urban wetlands: restoration or designed rehabilitation?[J]. AIMS Environmental Science, 2017, 4(3): 458-483. doi: 10.3934/environsci.2017.3.458

| [1] |
Chapin FS III, Zavaleta ES, Eviner VT, et al. (2000) Consequences of changing biodiversity. Nature 405: 234-242. doi: 10.1038/35012241

|
| [2] |
Anon (2016) Rise of the City. Science 352: 906-907. doi: 10.1126/science.352.6288.906
|
| [3] | WHO, World Health Organization, 2017. Available from: http://www.who.int/gho/urban_health/situation_trends/urban_population_growth/en/. |
| [4] | World Bank, 2017. Available from: http://data.worldbank.org/indicator/SP.URB.TOTL.IN.ZS. |
| [5] |
Lee SY, Dunn RJK, Young RA, et al. (2006) Impact of urbanization on coastal wetland structure and function. Austral Ecol 31: 149-163. doi: 10.1111/j.1442-9993.2006.01581.x
|
| [6] | Russi D, ten Brink P, Farmer A, et al. (2013) The Economics of Ecosystems and Biodiversity for Water and Wetlands. IEEP, London and Brussels, 2013. |
| [7] |
Hettiarachchi M, Morrison TH, McAlpine C (2015) Forty-three years of Ramsar and urban wetlands. Global Environ Chang 32: 57-66. doi: 10.1016/j.gloenvcha.2015.02.009
|
| [8] | USEPA (2016) National Wetland Condition Assessment 2011: A Collaborative Survey of the Nation's Wetlands. U.S. Environmental Protection Agency, Office of Wetlands, Oceans and Watersheds, Office of Research and Development, Washington, DC 20460. EPA-843-R-15-005. Available from: https://www.epa.gov/national-aquatic-resource-surveys/nwca. |
| [9] | Dahl TE (2011) Status and trends of wetlands in the coterminous United States 2004–2009. U.S. Department of the Interior; Fish and Wildlife Service. Washington, D.C. 108 pp. |
| [10] | Brady SJ, Flather CJ (1994) Changes in wetlands on nonfederal rural land of the conterminous United States from 1982 to 1987. Environ Manage 18: 693-705. |
| [11] | Kentula ME, Gwin SE, Pierson SM (2004) Tracking changes in wetlands with urbanization: sixteen years of experience in Portland, Oregon, USA. Wetlands 24: 734-743. |
| [12] | Gurtzwiller KJ, Flather CH (2011) Wetland features and landscape context predict the risk of wetland habitat loss. Ecol Appl 21: 968-982. |
| [13] | Sucik MT, Marks E (2015) The Status and Recent Trends of Wetlands in the United States. U.S. Department of Agriculture. 2015. Summary Report: 2012 National Resources Inventory, Natural Resources Conservation Service, Washington, DC, and Center for Survey Statistics and Methodology, Iowa State University, Ames, Iowa. Available from: http://www.nrcs.usda.gov/technical/nri/12summary. |
| [14] | Mitsch WJ, Gosselink JG (2015) Wetlands, 5th Edition. John Wiley & Sons. Hoboken, NJ. |
| [15] |
Bolund P, Hunhammar S (1999) Ecosystem services in urban areas. Ecol Econ 29: 293-301. doi: 10.1016/S0921-8009(99)00013-0
|
| [16] | Mitsch WJ, Gosselink JG (2000) The value of wetlands: importance of scale and landscape setting. Ecol Econ 35: 25-33. |
| [17] |
Baldwin AH (2004) Restoring complex vegetation in urban settings: The case of tidal freshwater marshes. Urban Ecosys 7: 125-137. doi: 10.1023/B:UECO.0000036265.86125.34
|
| [18] | Kusler J (2004) Multi-objective wetland restoration in watershed contexts. Association of State Wetland Managers, Inc. Berne, NY. |
| [19] |
Bengston DN, Fletcher JO, Nelson KC (2004) Public policies for managing urban growth and protecting open space: policy instruments and lessons learned in the United States. Landscape Urban Plan 69: 271-286. doi: 10.1016/j.landurbplan.2003.08.007
|
| [20] |
Gautam M, Achharya K, Shanahan SA (2014) Ongoing restoration and management of Las Vegas Wash: an evaluation of success criteria. Water Policy 16: 720-738. doi: 10.2166/wp.2014.035
|
| [21] | Boyer T, Polasky S (2004) Valuing urban wetlands: A review of non-market valuation studies. Wetlands 24: 744-755. |
| [22] |
McKenney BA, Kiesecker (2010) Policy development for biodiversity offsets: A review of offset frameworks. Environ Manage 45: 165-176. doi: 10.1007/s00267-009-9396-3
|
| [23] | Spieles DJ (2005) Vegetation development in created, restored, and enhanced mitigation wetland banks of the United States. Wetlands 25: 51-63. |
| [24] | Matthews JW, Endress AG (2008) Performance criteria, compliance success, and vegetation development in compensatory mitigation wetlands. Environ Manage 41: 130-141. |
| [25] |
Booth DB, Hartley D, Jackson R (2002) Forest cover, impervious-surface area, and the mitigation of stormwater impacts. J Am Water Resour As 38: 835-8453. doi: 10.1111/j.1752-1688.2002.tb01000.x
|
| [26] |
Moreno-Mateos D, Power ME, Comin FA, et al. (2012) Structural ad functional loss in restored wetland ecosystems. PLoS Biology 10: e1001247. doi: 10.1371/journal.pbio.1001247
|
| [27] |
BenDor T, Brozovic N, Pallathucheril VG (2008) The social impacts of wetland mitigation policies in the United States. J Plan Literature 22: 341-357. doi: 10.1177/0885412207314011
|
| [28] | USEPA, Principles for the Ecological Restoration of Aquatic Resources. EPA841-F-00-003. Office of Water (4501F), United States Environmental Protection Agency, Washington, DC. 4 pp. 2000. Available from: https://www.epa.gov/wetlands/principles-wetland-restoration. |
| [29] |
Ehrenfeld JG (2000) Evaluating wetlands within an urban context. Ecol Engi 15: 253-265. doi: 10.1016/S0925-8574(00)00080-X
|
| [30] |
Kentula ME (2000) Perspectives on setting success criteria for wetland restoration. Ecol Eng 15: 199-209. doi: 10.1016/S0925-8574(00)00076-8
|
| [31] | Faber-Langendoen D, Kudray G, Nordman C, et al. (2008) Ecological Performance Standards for Wetland Mitigation: An Approach Based on Ecological Integrity Assessments. NatureServe, Arlington, Virginia, 2008. |
| [32] |
Euliss NH, Smith LM, Wilcox DA, et al. (2008) Linking ecosystem processes with wetland management goals: Charting a course for a sustainable future. Wetlands 28: 553-562. doi: 10.1672/07-154.1
|
| [33] |
Brinson MM, Rheinhardt R (1996) The role of reference wetlands in functional assessment and mitigation. Ecol Appl 6: 69-76. doi: 10.2307/2269553
|
| [34] | USACE (2015) Nontidal Wetland Mitigation Banking in Maryland Performance Standards & Monitoring Protocol. Available from: http://www.nab.usace.army.mil/Portals/63/docs/Regulatory/Mitigation/MDNTWLPERMITTEEPERSTMON4115.pdf. |
| [35] | Kusler J (2006) Discussion Paper: Developing Performance Standards for the Mitigation and Restoration of Northern Forested Wetlands. Association of State Wetland Managers, Inc. Available from: https://www.aswm.org/pdf_lib/forested_wetlands_080106.pdf. |
| [36] |
Stefanik KC, Mitcsch WJ (2012) Structural and functional vegetation development in created and restored wetland mitigation banks of different ages. Ecol Eng 39: 104-112. doi: 10.1016/j.ecoleng.2011.11.016
|
| [37] | Zedler JB, Doherty JM, Miller NA (2012) Shifting restoration policy to address landscape change, novel ecosystems, and monitoring. Ecol Soc 17: 36. |
| [38] |
Grayson JE, Chapman MG, Underwood AJ (1999) The assessment of restoration of habitat in urban wetlands. Landscape Urban Plan 43: 227-236. doi: 10.1016/S0169-2046(98)00108-X
|
| [39] | Ravit B, Obropta C, Kallin P (2008) A baseline characterization approach to wetland enhancement in an urban watershed. Urban Habitats 5: 126-152. |
| [40] | Palmer MA, Ambrose RF, Noff NL (1997) Ecological Theory and Community Restoration Ecology. Restor Ecol 5: 291-300. |
| [41] |
Felson AJ, Pickett STA (2005) Designed experiments: new approaches to studying urban ecosystems. Front Ecol Environ 3: 549-556. doi: 10.1890/1540-9295(2005)003[0549:DENATS]2.0.CO;2
|
| [42] | Zedler JB (2007) Success: An unclear, subjective descriptor of restoration outcomes. Restor Ecol 25: 162-168. |
| [43] | NRC (2001) National Research Council. Compensating for Wetland Losses under the Clean Water Act. Washington, D.C. National Academies Press. |
| [44] |
Burns D, Vitvar T, McDonnell J, et al. (2005) Effects of suburban development on runoff generation in the Croton River basin, New York, USA. J Hydrol 311: 266-281. doi: 10.1016/j.jhydrol.2005.01.022
|
| [45] |
Sudduth EB, Meyer JL (2006) Effects of bioengineered streambank stabilization on bank habitat and macroinvertebrates in urban streams. Environ Manage 38: 218-226. doi: 10.1007/s00267-004-0381-6
|
| [46] |
Reinelt L, Horner R, Azous A (1998) Impacts of urbanization on palustrine (depressional freshwater) wetlands-research and management in the Puget Sound region. Urban Ecosys 2: 219-236. doi: 10.1023/A:1009532605918
|
| [47] | Hoefer W, Gallagher F, Hyslop R, et al. (2016) Unique landfill restoration designs increase opportunities to create urban open space. Environ Practice 18: 106-115. |
| [48] | Magee TK, Kentula ME (2005) Response of wetland plant species to hydrologic conditions. Wetl Ecol Manag 13: 163-181. |
| [49] | Hozapfel, Claus (2010) Restoration success assessment and plant community ecology research at the former 'Chromate Waste Site 15' in Liberty State Park. New Jersey Department of Environmental Protection, Monitoring Report. |
| [50] |
Larson MA, Heintzman RL, Titus JE, et al. (2016) Urban wetland characterization in south-central New York State. Wetlands 36: 821-829. doi: 10.1007/s13157-016-0789-9
|
| [51] |
Walsh CJ, Roy AH, Feminella JW, et al. (2005) The urban stream syndrome: current knowledge and the search for a cure. J N Am Benthol Soc 24: 706-723. doi: 10.1899/04-028.1
|
| [52] | Gift DM, Groffman PM, Kaushal SJ, et al. (2010) Denitrification potential, root biomass, and organic matter in degraded and restored urban riparian zones. Restor Ecol 18: 113-120. |
| [53] | Baart I, Gschöpf C, Blaschke AP, et al. (2010) Prediction of potential macrophyte development in response to restoration measures in an urban riverine wetland. Aquat Bot 93: 153-162. |
| [54] |
Ehrenfeld JG (2008) Exotic invasive species in urban wetlands: environmental correlates and implications for wetland management. J Appl Ecol 45: 1160-1169. doi: 10.1111/j.1365-2664.2008.01476.x
|
| [55] |
Ravit B, Ehrenfeld JG, Häggblom MM, et al. (2007) The effects of drainage and nitrogen enrichment on Phragmites australis, Spartina alternaflora, and their root-associated microbial communities. Wetlands 27: 915-927. doi: 10.1672/0277-5212(2007)27[915:TEODAN]2.0.CO;2
|
| [56] |
Lee BH, Scholz M (2007) What is the role of Phragmites australis in experimental Constructed wetland filters treating urban runoff? Ecol Eng 29: 87-95. doi: 10.1016/j.ecoleng.2006.08.001
|
| [57] | Bragato C, Brix H, Malagoli M (2006) Accumulation of nutrients and heavy metals in Phragmites australis (Cav.) Trin. Ex Steudel and Bolboschoenus maritimus (L.) Palla in a constructed wetland of the Venice lagoon watershed. Environ Pollut 144: 967-975. |
| [58] |
Weis JS, Weis P (2004) Metal uptake, transport and release by wetland plants: implications for phytoremediation and restoration. Environ Int 30: 685-700. doi: 10.1016/j.envint.2003.11.002
|
| [59] | Casagrande DG (1997) The human component of urban wetland restoration. In Restoration of an Urban Salt Marsh: An Interdisciplinary Approach (D.G. Casagrande, Ed.), 254-270. Bulletin Number 100, Yale School of Forestry and Environmental Studies, Yale University, New Haven, CT. |
| [60] |
Groffman PM, Crawford MK (2003) Denitrification potential in urban riparian zones. J Environ Qual 32: 1144-1149. doi: 10.2134/jeq2003.1144
|
| [61] |
Kohler EA, Poole VL, Reicher ZJ, et al. (2004) Nutrient, metal, and pesticide removal during storm and nonstorm events by a constructed wetland on an urban golf course. Ecol Eng 23: 285-298. doi: 10.1016/j.ecoleng.2004.11.002
|
| [62] | Mahon BL, Polasky S, Adams RM (2000) Valuing urban wetlands: a property price approach. Land Econ 76: 100-113. |
| [63] | Nassauer JI (2004) Monitoring the success of metropolitan wetland restorations: Cultural sustainability and ecological function. Wetlands 24: 756-765. |
| [64] | Swanson WR, Lamie P. Urban fill characterization and risk-based management decisions-A practical guide. Proceedings of the Annual Internation Conference on Soils, Sediments, Water and Energy. 2010, 12, 9. Available from: http://scholarworks.umass.edu/soilsproceedings/vol12/iss1/9 |
| [65] | Morio M, Schadler S, Finkel M (2013) Applying a multi-criteria genetic algorithm framework for brownfield reuse optimization: improving redevelopment options based on stakeholder preferences. J Environ Manage 130: 331-345. |
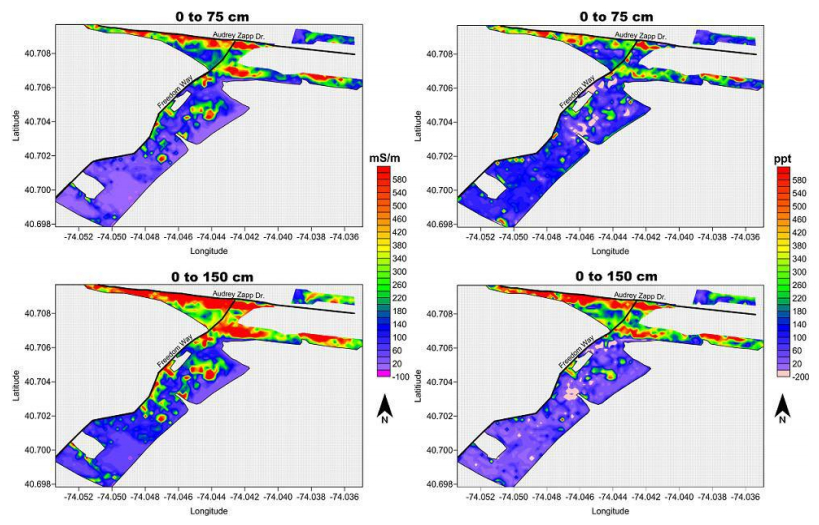
| [66] | Doolittle JA, Brevik EC (2014) The use of electromagnetic induction techniques in soils studies. Geoderma 223-225: 33-45. |
| [67] | Daniels JJ, Vendl M, Holt J, et al. (2003) Combining multiple geophysical data sets into a single 3D image. Sympposium on the Application of Geophysics to Engineering and Environmental Problems 2003: 299-306. |
| [68] | Allred BJ, Ehsani RM, Daniels JJ (2008) General considerations for geophysical methods applied to agriculture. Handbook of Agricultural Geophysics. CRC Press, Taylor and Francis Group, Boca Raton, Florida, 3-16. |
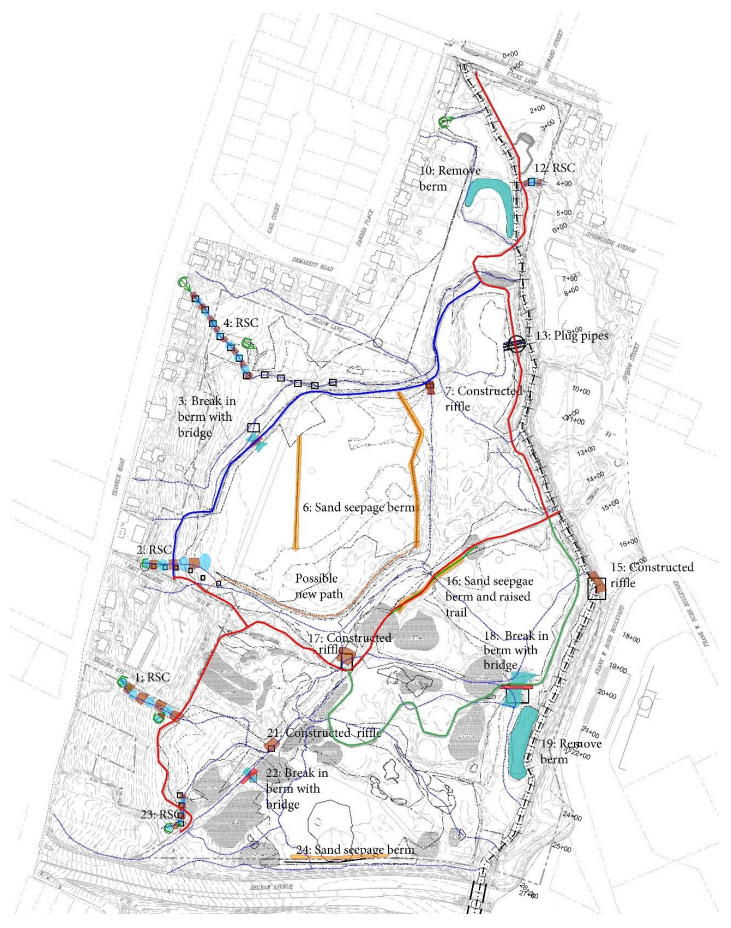
| [69] | Berg J, Underwood K, Regenerative stormwater conveyance (RSC) as an integrated approach to sustainable stormwater planning on linear projects. In Proceedings of the 2009 International Conference on Ecology and Transportation. Eds: Wagner, P.J., Nelson, D., Murray, E. Raleigh, NJ: Center for Transportation and the Environment, North Carolina State University. 2010. |
| [70] |
Palmer MA, Filoso S, Fanelli RM (2014) From ecosystems to ecosystem services: stream restoration as ecological engineering. Ecol Eng 65: 62-70. doi: 10.1016/j.ecoleng.2013.07.059
|
| [71] | Contaminated Soil-Cleanup Costs and Standards, 2017. Available from: http://science.jrank.org/pages/1737/Contaminated-Soil-Cleanup-costs-standards.html. |
| [72] | Final Engineering Evaluation/Cost Analysis. Index Shooting Range, Mt. Baker-Snoqualmie National Forest. Prepared by URS Consulting Engineers. Portland, Oregon USDA Forest Service, November 2011. |
| [73] | NJDEP=HPCTF Final Report-V. Costs and Economic Impacts, 2017. Available from: http://www.nj.gov/dep/special/hpctf/final/costs.htm. |
| [74] | In Situ Biological Treatment for Soil, Sediment, and Sludge. 2017. Available from: https:frtr.gov/matrix2/section3/sec3_int.html. |
| [75] | Obropta C, Kallin P, Mak M, et al. (2008) Modeling urban wetland hydrology for the restoration of a forested riparian wetland ecosystem. Urban Habitat 5: 183-198. |
| [76] | Gallagher FJ, Pechmann I, Bogden JD, et al. (2008) Soil metal concentrations and vegetative assemblage structure in an urban brownfield. Environ Pollut 153: 351-361. |
| [77] | Salisbury AB, Long term stability of trace element concentrations in a spontaneously vegetated urban brownfield with anthropogenic soils. Soil Science. In Press. |
| [78] | Wong THF, Somes NLG (1995) A Stochastic Approach to Designing Wetlands for Stormwater Pollution Control. Water Sci Technol 32: 145-151. |
| [79] | Wagner M (2004) The roles of seed dispersal ability and seedling salt tolerance in community assembly of a severely degraded site. In: Temperton, V.M., Hobbs, R.J., Nuttle, T., Jalle, S. (Eds.), Assembly Rules and Restoration Ecology: Bridging the Gap Between Theory and Practice. Island Press, Washington, DC, p. 266. |
| [80] | Belyea LR (2004) Beyond ecological filters: Feedback networks in the assembly and retroaction of community structure. In: Temperton, V.M., Hobbs, R.J., Nuttle, T.J., Halle, S. (Eds.), Assembly Rules and Restoration Ecology: Bridging the Gap Between Theory and Practice. Island Press, Washington, D.C., pp. 115e131. |
| [81] | Kusler J, Parenteau P, Thomas EA (2007) "Significant Nexus" and Clean Water Act Jurisdiction. Discussion paper. Association of State Wetland Managers, Inc. Available from: https://www.aswm.org/pdf_lib/significant_nexus_paper_030507.pdf. |
| [82] | Lockwood JL, Pimm SL (1999) When does restoration succeed? In: E Weiher and P.A. Keddy (eds) Ecological assembly rules: perspective, advances and retreats. Cambridge University Press. |
| [83] | Clements FE, 1916. Plant Succession. Publication 242. Carnegie Institution, Washington, D.C. |
| [84] | Gleason HA, 1926. The individualistic concept of plant association. Bulletin of the Torrey Botany Club 53, 7e26. |
| [85] | Van der Maarel E, Sykes MT (1993) Small-scale plant species turnover in limestone grasslands: the carousel model and some comments on the niche concept. J Vegetative Science 4: 179e188. |
| [86] | Hobbs JD, Norton DA, 2004. In: Templeton, V.M.R.J., Hobbs, T., Nuttle, T., Halle, S. (Eds.), Assembly Rules and Restoration Ecology. Island Press, p. 77. |
| [87] |
Bendor T (2009) A dynamic analysis of the wetland mitigation process and its effects on no net loss policy. Landscape Urban Plan 89: 17-27. doi: 10.1016/j.landurbplan.2008.09.003
|
| [88] |
Palmer MA, Bernhardt ES, Allan JD, et al. (2005) Standards for ecologically successful river restoration. J Appl Ecol 42: 208-217. doi: 10.1111/j.1365-2664.2005.01004.x
|
| [89] | Soil Clean Up Criteria, NJDEP, 1999. Available from: http://www.nj.gov/dep/srp/guidance/scc/. |
| [90] | Efroymson RA, Will ME, Suter II GW, et al. (1997) Toxicological Benchmarks for Screening Contaminants of Potential Concern for Effects on Terrestrial Plants: 1997 Revision. Oak Ridge National Laboratory, Oak Ridge, TN, 128 pp. |
| [91] | United States Environmental Protection Agency, 2003. Guidance for Developing Ecological Soil Screening Levels. OSWER-Directive 9285.7-55. Available from: http://www.epa.gov/ecotox/ecossl/. |



Figures(11) / Tables(2)

Beth Ravit, Frank Gallagher, James Doolittle, Richard Shaw, Edwin Muñiz, Richard Alomar, Wolfram Hoefer, Joe Berg, Terry Doss. Urban wetlands: restoration or designed rehabilitation?[J]. AIMS Environmental Science, 2017, 4(3): 458-483. doi: 10.3934/environsci.2017.3.458







 DownLoad:
DownLoad: