Citation: Jane Law. Exploring the Specifications of Spatial Adjacencies and Weights in Bayesian Spatial Modeling with Intrinsic Conditional Autoregressive Priors in a Small-area Study of Fall Injuries[J]. AIMS Public Health, 2016, 3(1): 65-82. doi: 10.3934/publichealth.2016.1.65

| [1] |
Besag J, York J, Mollie A (1991) Bayesian image restoration with two applications in spatial statistics. Annals Institute Stat Mathe 43: 1-59. doi: 10.1007/BF00116466

|
| [2] | Congdon P (2003) Applied Bayesian Modelling. Chichester: John Wiley, 276-281. |
| [3] |
Graham P (2008) Intelligent smoothing using hierarchical Bayesian models. Epidemiology 19: 493-495. doi: 10.1097/EDE.0b013e31816b7859
|
| [4] |
Ryan L (2009) Spatial epidemiology: some pitfalls and opportunities. Epidemiology 20: 242-244. doi: 10.1097/EDE.0b013e318198a5fb
|
| [5] | Waller LA, Gotway CA (2004) Applied spatial statistics for public health data. Hoboken, N.J.: John Wiley & Sons, 259-260. |
| [6] | Conlon EM, Waller LA (1998) Flexible neighborhood structures in hierarchical models for disease mapping. University of Minnesota Biostatistics Research Report, No rr98-018: Division of Biostatistics, University of Minnesota. |
| [7] |
Lee D, Mitchell R (2012) Boundary detection in disease mapping studies. Biostatistics 13: 415-426. doi: 10.1093/biostatistics/kxr036
|
| [8] | Lu H, Reilly CS, Banerjee S, et al. (2007) Bayesian areal wombling via adjacency modeling. EnvirEcolog Stat 14: 433-452. |
| [9] |
Ma H, Carlin BP (2007) Bayesian multivariate areal wombling for multiple disease boundary analysis. Bayesian analysis 2: 281-302. doi: 10.1214/07-BA211
|
| [10] |
Lee D, Rushworth A, Sahu SK (2014) A Bayesian localized conditional autoregressive model for estimating the health effects of air pollution. Biometrics 70: 419-429. doi: 10.1111/biom.12156
|
| [11] |
Chan WC, Law J, Seliske P (2012) Bayesian spatial methods for small-area injury analysis: a study of geographical variation of falls in older people in the Wellington-Dufferin-Guelph health region of Ontario, Canada. Injury Preve 18: 303-308. doi: 10.1136/injuryprev-2011-040068
|
| [12] | Ministry of Health and Long-term Care. Fall-Related Hospitalizations Among Seniors, 2011. Available from http://www.health.gov.on.ca/english/public/pub/pubhealth/init_report/fhas.html. |
| [13] | Congdon P (2006) Bayesian Statistical Modelling, Second Edition. Chichester: John Wiley, 303-310. |
| [14] |
Law J, Haining RP (2004) A Bayesian Approach to Modelling Binary Data: the Case of High-intensity Crime Areas. Geog Analysis 36: 197-216. doi: 10.1111/j.1538-4632.2004.tb01132.x
|
| [15] | Kelsall JE, Wakefield JC (1999) Discussion of 'Bayesian models for spatially correlated disease and exposure data' by Best et al. In: Bernardo JM, Berger JO, David AP et al., editors. Bayesian Statistics 6: Oxford University Press. pp. 151. |
| [16] | U.S. Geological Survey Adjacency for WinBUGS tool, 2015. Available from http://www.umesc.usgs.gov/management/dss/adjacency_tool.html. |
| [17] |
Law J, Quick M (2013) Exploring links between juvenile offenders and social disorganization at a large map scale: a Bayesian spatial modeling approach. J Geog Sys 15: 89-113. doi: 10.1007/s10109-012-0164-1
|
| [18] | Spiegelhalter DJ, Best N, Carlin BP, et al. (2001) Bayesian measures of model complexity and fit. Medical Research Council Biostatistics Unit, Cambridge, UK. |
| [19] | Best N, Arnold R, Thomas A, et al. (1999) Bayesian models for spatially correlated disease and exposure data. In: Bernardo JM, Berger JO, David AP et al., editors. Bayesian Statistics 6. Oxford: Oxford University Press. pp. 131-156. |
| [20] |
Assuncao R, Krainski E (2009) Neighborhood dependence in Bayesian spatial models. Biometrical J 51: 851-869. doi: 10.1002/bimj.200900056
|
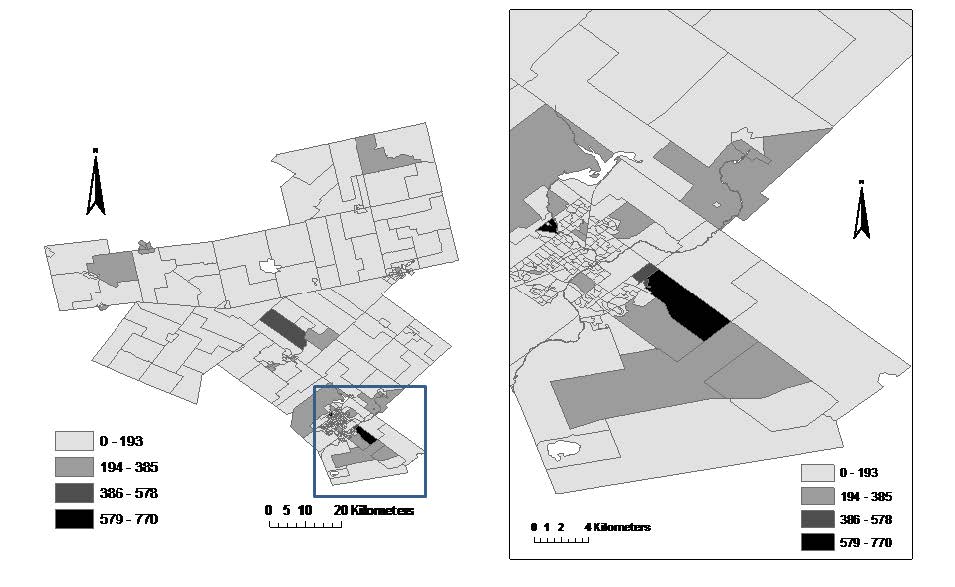
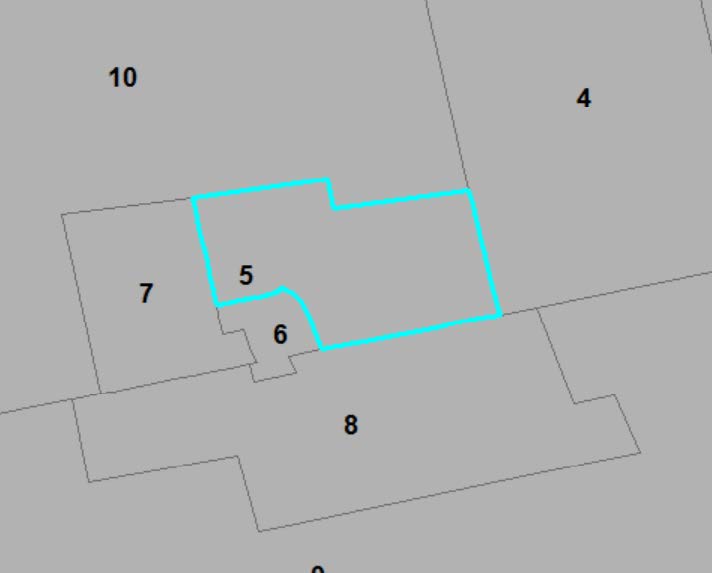



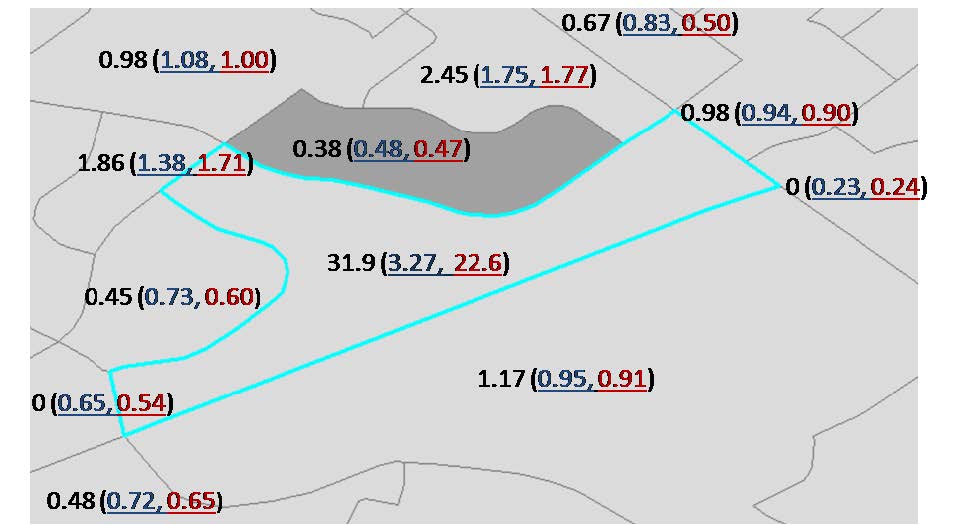
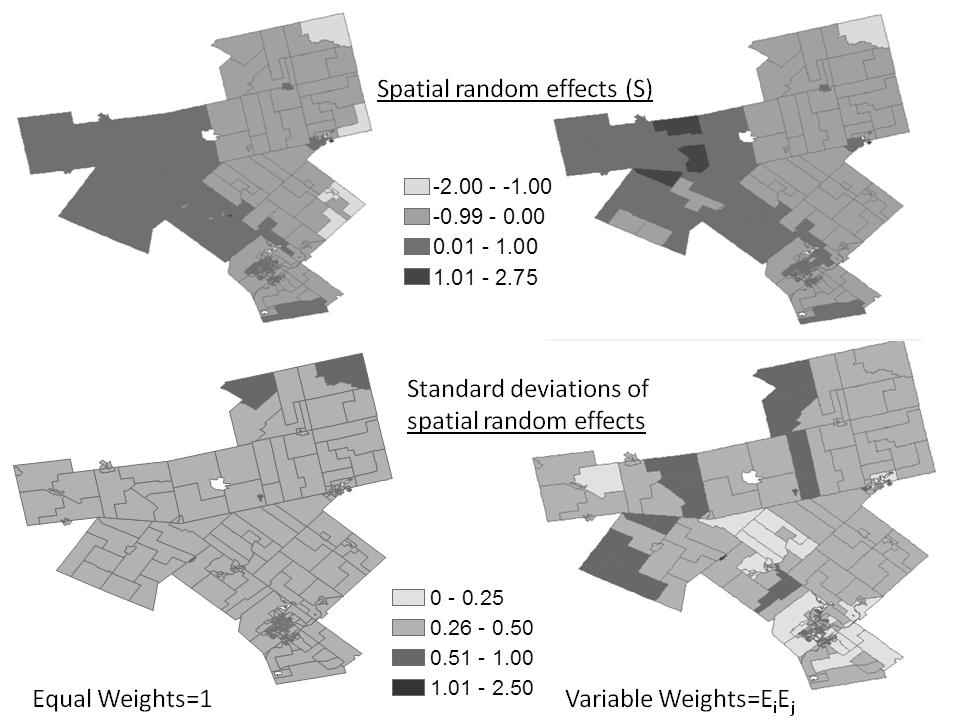
Figures(8) / Tables(3)

Jane Law. Exploring the Specifications of Spatial Adjacencies and Weights in Bayesian Spatial Modeling with Intrinsic Conditional Autoregressive Priors in a Small-area Study of Fall Injuries[J]. AIMS Public Health, 2016, 3(1): 65-82. doi: 10.3934/publichealth.2016.1.65







 DownLoad:
DownLoad: