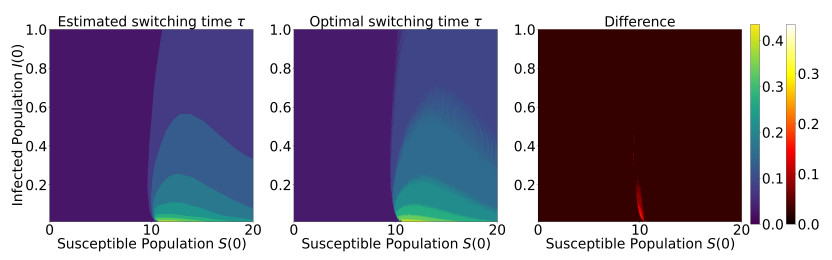
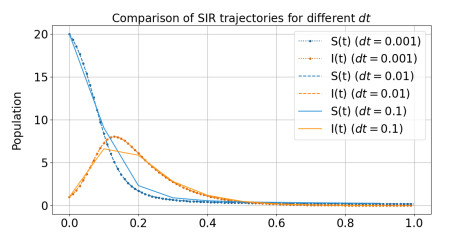
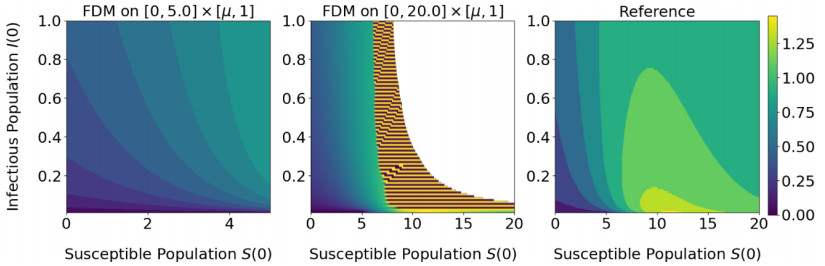
This work investigates the minimum eradication time in a controlled susceptible-infectious-recovered model with constant infection and recovery rates. The eradication time is defined as the earliest time the infectious population falls below a prescribed threshold and remains below it. Leveraging the fact that this problem reduces to solving a Hamilton-Jacobi-Bellman (HJB) equation, we propose a mesh-free framework based on a physics-informed neural network to approximate the solution. Moreover, leveraging the well-known structure of the optimal control of the problem, we efficiently obtain the optimal vaccination control from the minimum eradication time using the dynamic programming principle. To improve training stability and accuracy, we incorporate a variable scaling method and provide theoretical justification through a neural tangent kernel analysis. Numerical experiments show that this technique significantly enhances convergence, reducing the mean squared residual error by approximately 80% compared with standard physics-informed approaches. Furthermore, the method accurately identifies the optimal switching time. These results demonstrate the effectiveness of the proposed deep learning framework as a computational tool for solving optimal control problems in epidemic modeling as well as the corresponding HJB equations.
Citation: Minseok Kim, Yeongjong Kim, Yeoneung Kim. Physics-informed neural networks for optimal vaccination plan in SIR epidemic models[J]. Mathematical Biosciences and Engineering, 2025, 22(7): 1598-1633. doi: 10.3934/mbe.2025059
This work investigates the minimum eradication time in a controlled susceptible-infectious-recovered model with constant infection and recovery rates. The eradication time is defined as the earliest time the infectious population falls below a prescribed threshold and remains below it. Leveraging the fact that this problem reduces to solving a Hamilton-Jacobi-Bellman (HJB) equation, we propose a mesh-free framework based on a physics-informed neural network to approximate the solution. Moreover, leveraging the well-known structure of the optimal control of the problem, we efficiently obtain the optimal vaccination control from the minimum eradication time using the dynamic programming principle. To improve training stability and accuracy, we incorporate a variable scaling method and provide theoretical justification through a neural tangent kernel analysis. Numerical experiments show that this technique significantly enhances convergence, reducing the mean squared residual error by approximately 80% compared with standard physics-informed approaches. Furthermore, the method accurately identifies the optimal switching time. These results demonstrate the effectiveness of the proposed deep learning framework as a computational tool for solving optimal control problems in epidemic modeling as well as the corresponding HJB equations.

| [1] |
W. O. Kermack, A. G. McKendrick, A contribution to the mathematical theory of epidemics, Math. Phys. Eng. Sci., 115 (1927), 700–721. https://doi.org/10.1098/rspa.1927.0118 doi: 10.1098/rspa.1927.0118

|
| [2] |
M. Barro, A. Guiro, D. Quedraogo, Optimal control of a SIR epidemic model with general incidence function and a time delays, CUBO A Math. J., 20 (2018), 53–66. https://doi.org/10.4067/S0719-06462018000200053 doi: 10.4067/S0719-06462018000200053
|
| [3] |
P. A. Bliman, M. Duprez, Y. Privat, N. Vauchelet, Optimal immunity control and final size minimization by social distancing for the SIR epidemic model, J. Optim. Theory Appl., 189 (2021), 408–436. https://doi.org/10.1007/s10957-021-01830-1 doi: 10.1007/s10957-021-01830-1
|
| [4] |
L. Bolzoni, E. Bonacini, C. Soresina, M. Groppi, Time-optimal control strategies in SIR epidemic models, Math. Biosci., 292 (2017), 86–96. https://doi.org/10.1016/j.mbs.2017.07.011 doi: 10.1016/j.mbs.2017.07.011
|
| [5] |
E. V. Grigorieva, E. N. Khailov, A. Korobeinikov, Optimal control for a SIR epidemic model with nonlinear incidence rate, Math. Model. Nat. Phenom., 11 (2016), 89–104. https://doi.org/10.1051/mmnp/201611407 doi: 10.1051/mmnp/201611407
|
| [6] |
R. Hynd, D. Ikpe, T. Pendleton, An eradication time problem for the SIR model, J. Differ. Equations, 303 (2021), 214–252. https://doi.org/10.1016/j.jde.2021.09.001 doi: 10.1016/j.jde.2021.09.001
|
| [7] |
R. Hynd, D. Ikpe, T. Pendleton, Two critical times for the SIR model, J. Math. Anal. Appl., 505 (2022), 125507. https://doi.org/10.1016/j.jmaa.2021.125507 doi: 10.1016/j.jmaa.2021.125507
|
| [8] | L. S. Pontryagin, Mathematical Theory of Optimal Processes, Routledge, 2018. |
| [9] | J. Jang, Y. Kim, On a minimum eradication time for the SIR model with time-dependent coefficients, preprint, arXiv: 2311.14657. https://doi.org/10.48550/arXiv.2311.14657 |
| [10] | H. V. Tran, Hamilton-Jacobi equations: Theory and applications, Am. Math. Soc., 213 (2021), 322. |
| [11] |
S. Ko, S. Park, VS-PINN: A fast and efficient training of physics-informed neural networks using variable-scaling methods for solving PDEs with stiff behavior, J. Comput. Phys., 529 (2025), 113860. https://doi.org/10.1016/j.jcp.2025.113860 doi: 10.1016/j.jcp.2025.113860
|
| [12] | A. Jacot, F. Gabriel, C. Hongler, Neural tangent kernel: Convergence and generalization in neural networks, in STOC 2021: Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, (2021). https://doi.org/10.1145/3406325.3465355 |
| [13] |
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378 (2019), 686–707. https://doi.org/10.1016/j.jcp.2018.10.045 doi: 10.1016/j.jcp.2018.10.045
|
| [14] |
E. Kharazmi, M. Cai, X. Zheng, G. Lin, G. E. Karniadakis, Identifiability and predictability of integer-and fractional-order epidemiological models using physics-informed neural networks, Nat. Comput. Sci., 1 (2021), 744–753. https://doi.org/10.1038/s43588-021-00158-0 doi: 10.1038/s43588-021-00158-0
|
| [15] |
A. Yazdani, L. Lu, M. Raissi, G. E. Karniadakis, Systems biology informed deep learning for inferring parameters and hidden dynamics, PLoS Comput. Biol., 16 (2020), e1007575. https://doi.org/10.1371/journal.pcbi.1007575 doi: 10.1371/journal.pcbi.1007575
|
| [16] |
S. Cai, Z. Mao, Z. Wang, M. Yin, G. E. Karniadakis, Physics-informed neural networks (PINNs) for fluid mechanics: A review, Acta Mech. Sin., 37 (2021), 1727–1738. https://doi.org/10.1007/s10409-021-01148-1 doi: 10.1007/s10409-021-01148-1
|
| [17] |
M. Raissi, A. Yazdani, G. E. Karniadakis, Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations, Science, 367 (2020), 1026–1030. https://doi.org/10.1126/science.aaw4741 doi: 10.1126/science.aaw4741
|
| [18] |
X. Jin, S. Cai, H. Li, G. E. Karniadakis, NSFnets (Navier-Stokes flow nets): Physics-informed neural networks for the incompressible Navier-Stokes equations, J. Comput. Phys., 426 (2021), 109951. https://doi.org/10.1016/j.jcp.2020.109951 doi: 10.1016/j.jcp.2020.109951
|
| [19] |
X. Wang, J. Li, J. Li, A deep learning based numerical PDE method for option pricing, Comput. Econ., 62 (2023), 149–164. https://doi.org/10.1007/s10614-022-10279-x doi: 10.1007/s10614-022-10279-x
|
| [20] |
Y. Bai, T. Chaolu, S. Bilige, The application of improved physics-informed neural network (IPINN) method in finance, Nonlinear Dyn., 107 (2022), 3655–3667. https://doi.org/10.1007/s11071-021-07146-z doi: 10.1007/s11071-021-07146-z
|
| [21] |
G. Kissas, Y. Yang, E. Hwuang, W. R. Witschey, J. A. Detre, P. Perdikaris, Machine learning in cardiovascular flows modeling: Predicting arterial blood pressure from non-invasive 4d flow MRI data using physics-informed neural networks, Comput. Methods Appl. Mech. Eng., 358 (2020), 112623. https://doi.org/10.1016/j.cma.2019.112623 doi: 10.1016/j.cma.2019.112623
|
| [22] |
F. Sahli C., Y. Yang, P. Perdikaris, D. E. Hurtado, E. Kuhl, Physics-informed neural networks for cardiac activation mapping, Front. Phys., 8 (2020), 42. https://doi.org/10.3389/fphy.2020.00042 doi: 10.3389/fphy.2020.00042
|
| [23] |
S. Wang, Y. Teng, P. Perdikaris, Understanding and mitigating gradient flow pathologies in physics-informed neural networks, SIAM J. Sci. Comput., 43 (2021), A3055–A3081. https://doi.org/10.1137/20M1318043 doi: 10.1137/20M1318043
|
| [24] |
Y. Liu, L. Cai, Y. Chen, B. Wang, Physics-informed neural networks based on adaptive weighted loss functions for Hamilton–Jacobi equations, Math. Biosci. Eng., 19 (2022), 12866–12896. https://doi.org/10.3934/mbe.2022601 doi: 10.3934/mbe.2022601
|
| [25] |
S. Wang, X. Yu, P. Perdikaris, When and why PINNs fail to train: A neural tangent kernel perspective, J. Comput. Phys., 449 (2022), 110768. https://doi.org/10.1016/j.jcp.2021.110768 doi: 10.1016/j.jcp.2021.110768
|
| [26] |
W. Ji, W. Qiu, Z. Shi, S. Pan, S. Deng, Stiff-pinn: Physics-informed neural network for stiff chemical kinetics, J. Phys. Chem. A, 125 (2021), 8098–8106. https://doi.org/10.1021/acs.jpca.1c05102 doi: 10.1021/acs.jpca.1c05102
|
| [27] |
L. D. McClenny, U. M. Braga-Neto, Self-adaptive physics-informed neural networks, J. Comput. Phys., 474 (2023), 111722. https://doi.org/10.1016/j.jcp.2022.111722 doi: 10.1016/j.jcp.2022.111722
|
| [28] |
S. Mowlavi, S. Nabi, Optimal control of PDEs using physics-informed neural networks, J. Comput. Phys., 473 (2023), 111731. https://doi.org/10.1016/j.jcp.2022.111731 doi: 10.1016/j.jcp.2022.111731
|
| [29] | Y. Meng, R. Zhou, A. Mukherjee, M. Fitzsimmons, C. Song, J. Liu, Physics-informed neural network policy iteration: Algorithms, convergence, and verification, preprint, arXiv: 2402.10119. https://doi.org/10.48550/arXiv.2402.10119 |
| [30] | J. Y. Lee, Y. Kim, Hamilton-Jacobi based policy-iteration via deep operator learning, preprint, arXiv: 2406.10920. https://doi.org/10.48550/arXiv.2406.10920 |
| [31] |
W. Tang, H. Tran, Y. Zhang, Policy iteration for the deterministic control problems—A viscosity approach, SIAM J. Control Optim., 63 (2025), 375–401. https://doi.org/10.1137/24M1631602 doi: 10.1137/24M1631602
|
| [32] |
S. Yin, J. Wu, P. Song, Optimal control by deep learning techniques and its applications on epidemic models, J. Math. Biol., 86 (2023), 36. https://doi.org/10.1007/s00285-023-01873-0 doi: 10.1007/s00285-023-01873-0
|
| [33] |
Y. Ye, A. Pandey, C. Bawden, D. Sumsuzzman, R. Rajput, A. Shoukat, et al., Integrating artificial intelligence with mechanistic epidemiological modeling: A scoping review of opportunities and challenges, Nat. Commun., 16 (2025), 581. https://doi.org/10.1038/s41467-024-55461-x doi: 10.1038/s41467-024-55461-x
|
| [34] |
Z. Yang, Z. Zeng, K. Wang, S. Wong, W. Liang, M. Zanin, et al., Modified SEIR and AI prediction of the epidemics trend of COVID-19 in china under public health interventions, J. Thorac. Dis., 12 (2020), 165. https://doi.org/10.21037/jtd.2020.02.64 doi: 10.21037/jtd.2020.02.64
|
| [35] | L. Evans, Partial differential equations: 2nd edition, in Graduate Studies in Mathematics, Am. Math. Soc., 19 (2010), 749. |
| [36] | R. V. Hogg, J. W. McKean, A. T. Craig, Introduction to Mathematical Statistics, 8th edition, 2013. |
| [37] | D. Kingma, Adam: A method for stochastic optimization, preprint, arXiv: 1412.6980. |
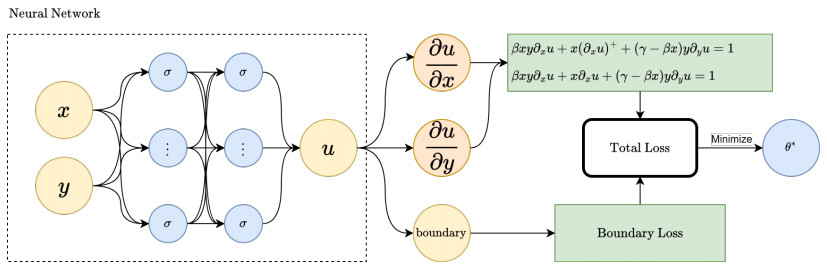
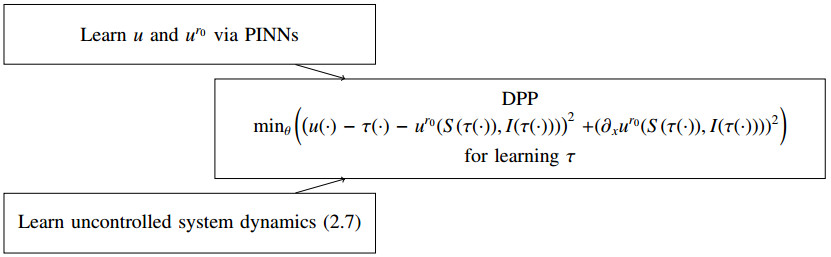
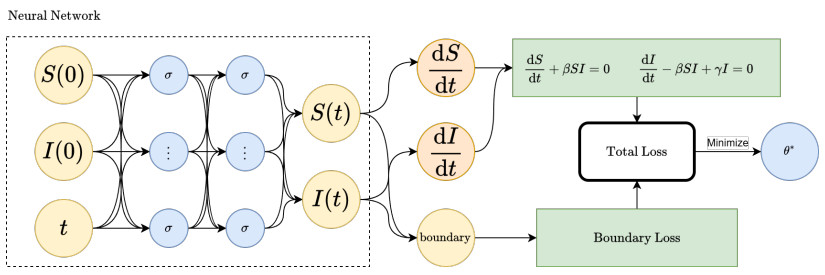
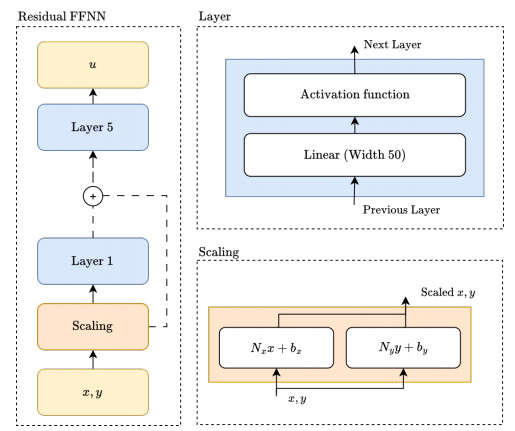
Figures(11) / Tables(3)

Minseok Kim, Yeongjong Kim, Yeoneung Kim. Physics-informed neural networks for optimal vaccination plan in SIR epidemic models[J]. Mathematical Biosciences and Engineering, 2025, 22(7): 1598-1633. doi: 10.3934/mbe.2025059







 DownLoad:
DownLoad: