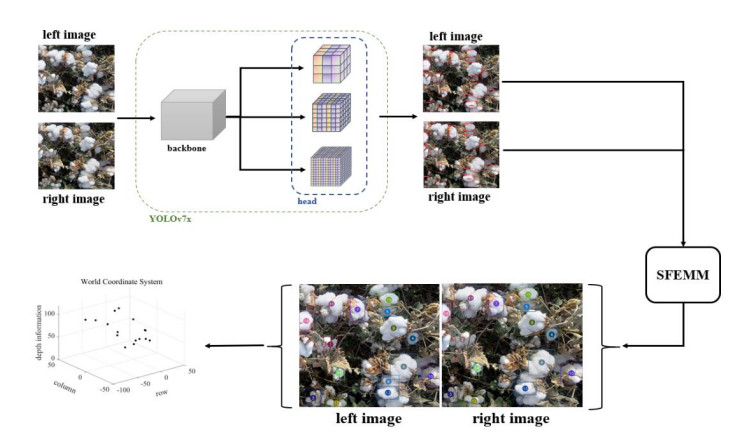
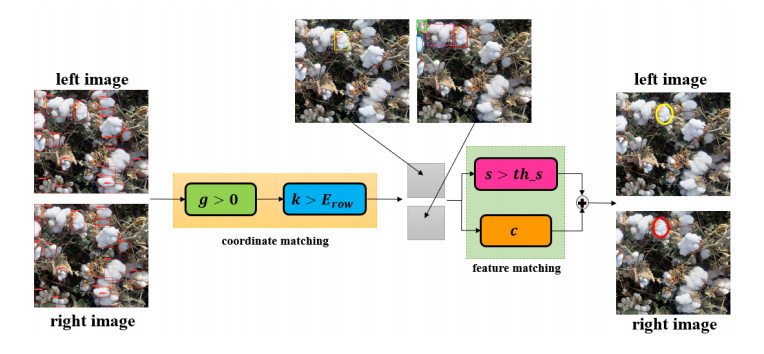
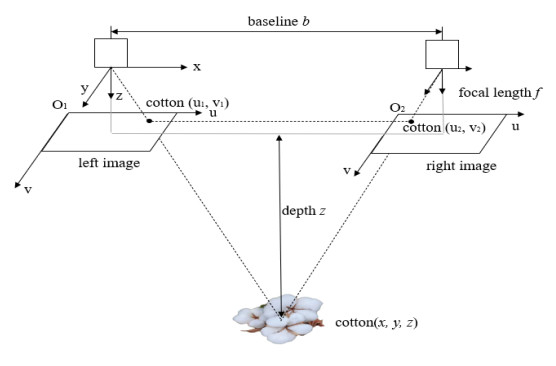
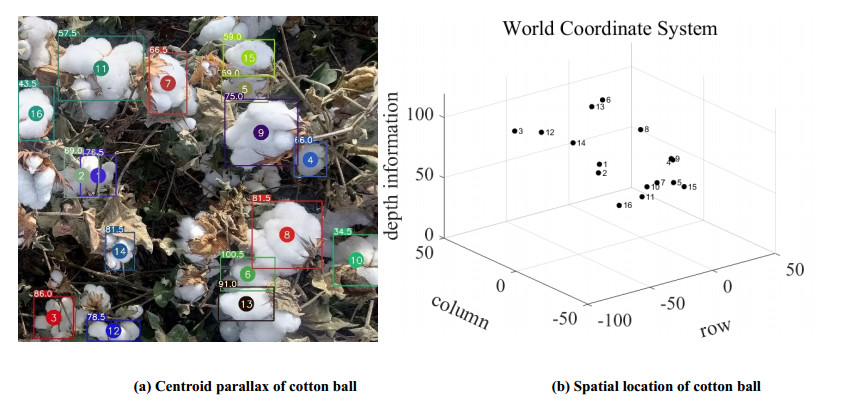
The cotton-picking robot needs to locate the target object in space in the process of picking in the field and other outdoor strong light complex environments. The difficulty of this process was binocular matching. Therefore, this paper proposes an accurate and fast binocular matching method. This method used the deep learning model to obtain the position and shape of the target object, and then used the matching equation proposed in this paper to match the target object. Matching precision of this method for cotton matching was much higher than that of similar algorithms. It was 54.11, 45.37, 6.15, and 12.21% higher than block matching (BM), semi global block matching (SGBM), pyramid stereo matching network (PSMNet), and geometry and context for deep stereo regression (GC-net) respectively, and its speed was also the fastest. Using this new matching method, the cotton was matched and located in space. Experimental results show the effectiveness and feasibility of the algorithm.
Citation: Guohui Zhang, Gulbahar Tohti, Ping Chen, Mamtimin Geni, Yixuan Fan. SFEMM: A cotton binocular matching method based on YOLOv7x[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3618-3630. doi: 10.3934/mbe.2024159
The cotton-picking robot needs to locate the target object in space in the process of picking in the field and other outdoor strong light complex environments. The difficulty of this process was binocular matching. Therefore, this paper proposes an accurate and fast binocular matching method. This method used the deep learning model to obtain the position and shape of the target object, and then used the matching equation proposed in this paper to match the target object. Matching precision of this method for cotton matching was much higher than that of similar algorithms. It was 54.11, 45.37, 6.15, and 12.21% higher than block matching (BM), semi global block matching (SGBM), pyramid stereo matching network (PSMNet), and geometry and context for deep stereo regression (GC-net) respectively, and its speed was also the fastest. Using this new matching method, the cotton was matched and located in space. Experimental results show the effectiveness and feasibility of the algorithm.

| [1] | Announcement of The National Bureau of Statistics on Cotton Production In 2022, 2022. Available from: http://www.stats.gov.cn/sj/zxfb/202302/t20230203_1901689.html |
| [2] | J. Tian, Change of Fiber Quality in Machine-harvested Cotton in the Xinjiang and Further Survey of Promising Approaches for Improving, MS thesis, Shihezi University, 2018. |
| [3] | L. Wang, S. Liu, W. Lu, B. Gu, R. Zhu, H. Zhu, Laser detection method for cotton orientation in robotic cotton picking, Trans. Chinese Soc. Agric. Eng., 30 (2014), 42–48. |
| [4] | J. Liu, D. Zhou, Y. Li, D. Li, Y. Li, R. Rubel, Monocular distance measurement algorithm for pomelo fruit based on target pixels change, Trans. Chinese Soc. Agric. Eng., 37 (2021), 183–191. |
| [5] | R. Girshick, Fast R-CNN, in 2015 IEEE International Conference on Computer Vision (ICCV), (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [6] |
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, IEEE Trans. Pattern Anal. Mach. Intell., 9 (2017), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 doi: 10.1109/TPAMI.2016.2577031

|
| [7] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [8] | J. Redmon, A. Farhadi, YOLO9000: Better, faster, stronger, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 6517–6525. https://doi.org/10.1109/CVPR.2017.690 |
| [9] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, preprint, arXiv: 1804.02767. |
| [10] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, YOLOv4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. http://arXiv.org/abs/2004.10934 |
| [11] |
D. T. Fasiolo, L. Scalera, E. Maset, A. Gasparetto, Towards autonomous mapping in agriculture: A review of supportive technologies for ground robotics, Rob. Auton. Syst., 169 (2023), 104514. https://doi.org/10.1016/j.robot.2023.104514 doi: 10.1016/j.robot.2023.104514
|
| [12] |
H. Gharakhani, J. A. Thomasson, Y. Lu, Integration and preliminary evaluation of a robotic cotton harvester prototype, Comput. Electron. Agr., 211 (2023), 107943. https://doi.org/10.1016/j.compag.2023.107943. doi: 10.1016/j.compag.2023.107943
|
| [13] |
S Liu, M Liu, Y Chai, S Li, H Miao, Recognition and location of pepper picking based on improved YOLOv5s and depth camera, Appl. Eng. Agr., 39 (2023), 179–185. https://doi.org/10.13031/aea.15347 doi: 10.13031/aea.15347
|
| [14] | G. P. Stein, O. Mano, A. Shashua, Vision-based ACC with a single camera: Bounds on range and range rate accuracy, in IEEE IV2003 Intelligent Vehicles Symposium, (2003), 120–125. https://doi.org/10.1109/IVS.2003.1212895 |
| [15] |
H. Hirschmuller, Stereo processing by semiglobal matching and mutual information, IEEE Trans. Pattern Anal. Mach. Intell., 30 (2008), 328–341. https://doi.org/10.1109/TPAMI.2007.1166 doi: 10.1109/TPAMI.2007.1166
|
| [16] | Y. Liu, G. Mamtimin, T. Gulbahar, M. Julaiti, An improved SM spectral clustering algorithm for accurate cotton segmentation in cotton fields, J. Agr. Mech., 44 (2022). |
| [17] | A. Kendall, H. Martirosyan, S. Dasgupta, P. Henry, R. Kennedy, A. Bachrach, et al., End-to-end learning of geometry and context for deep stereo regression, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 66–75. https://doi.org/10.1109/ICCV.2017.17 |
| [18] | J. R. Chang, Y. S. Chen, Pyramid stereo matching network, preprint, arXiv: 1803.08669. http://arXiv.org/abs/1803.08669 |
| [19] | E. Goldman, R. Herzig, A. Eisenschtat, J. Goldberger, T. Hassner, Precise detection in densely packed scenes, preprint, arXiv: 1904.00853. http://arXiv.org/abs/1904.00853 |
| [20] | T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, preprint, arXiv: 1612.03144. http://arXiv.org/abs/1612.03144 |
| [21] | C. Wang, A. Bochkovskiy, H. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2023), 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721 |
| [22] |
C. Huang, X. Pan, J. Cheng, J. Song, Deep image registration with depth-aware homography estimation, IEEE Signal Process. Lett., 30 (2023), 6–10. https://doi.org/10.1109/LSP.2023.3238274 doi: 10.1109/LSP.2023.3238274
|
| [23] | X. Peng, J. Zhou, Y. Xu, G. Xi, Cotton top bud recognition method based on YOLOv5-CPP in complex environment, Trans. Chinese Soc. Agr. Eng., 39 (2023), 191–197. |



Figures(7) / Tables(3)

Guohui Zhang, Gulbahar Tohti, Ping Chen, Mamtimin Geni, Yixuan Fan. SFEMM: A cotton binocular matching method based on YOLOv7x[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3618-3630. doi: 10.3934/mbe.2024159







 DownLoad:
DownLoad: