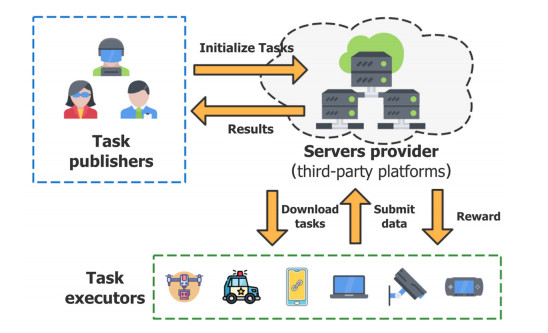
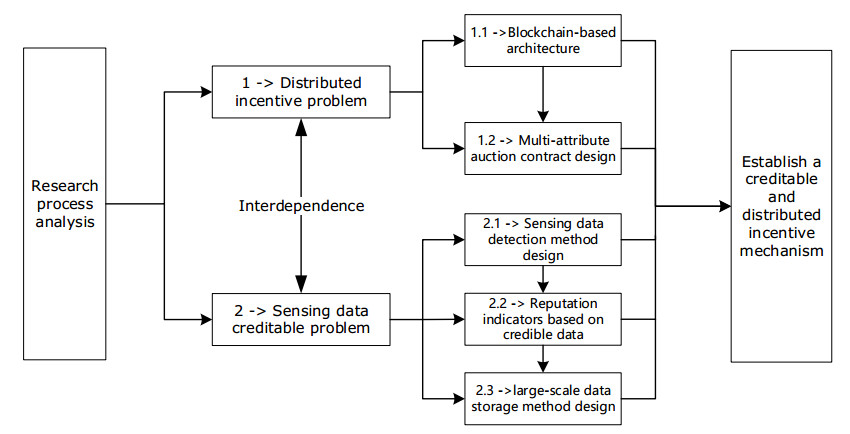
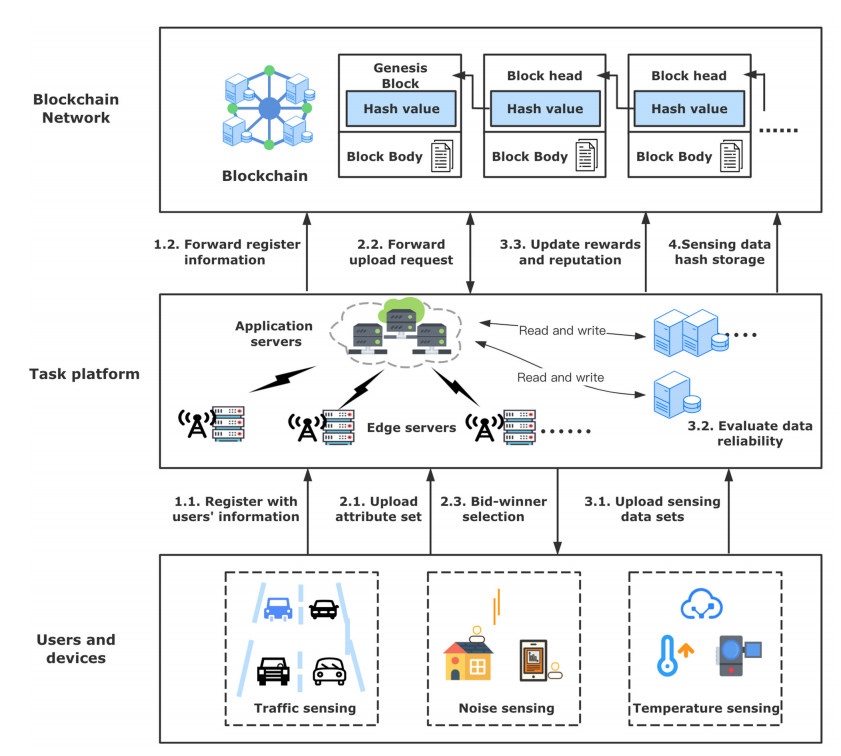
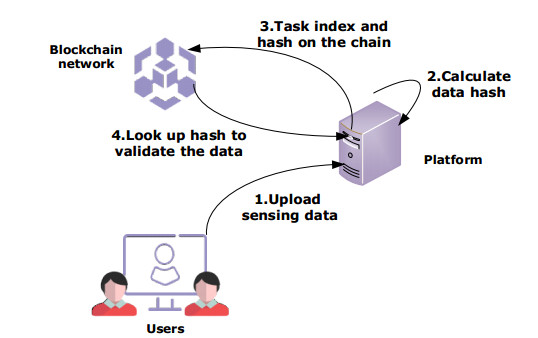
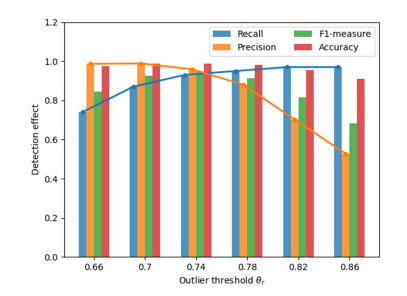
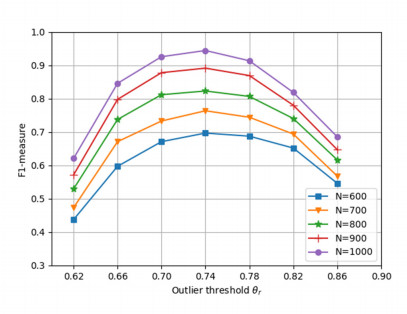
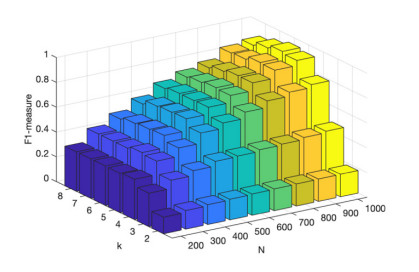
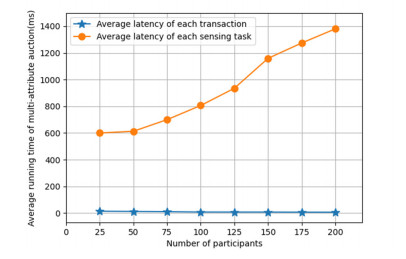
With the popularization of portable smart devices, the advance in ubiquitous connectivity and the Internet of Things (IoT), mobile crowdsensing is becoming one of the promising applications to acquire information in the physical world of edge computing and is widely used in Smart Cities. However, most of the existing mobile crowdsensing models are based on centralized platforms, which have some problems in reality. Data storage is overly dependent on third-party platforms leading to single-point failures. Besides, trust issues seriously affect users' willingness to participate and the credibility of data. To solve these two problems, a creditable and distributed incentive mechanism based on Hyperledger Fabric (HF-CDIM) is proposed in this paper. Specifically, the HF-CDIM combines auction, reputation and data detection methods. First, we develop a multi-attribute auction algorithm with a reputation on blockchain by designing a smart contract, which achieves a distributed incentive mechanism for participants. Second, we propose a K-nearest neighbor outlier detection algorithm based on geographic location and similarity to quantify the credibility of the data. It is also used to update the user's reputation index. This guarantees the credibility of sensing data. Finally, the simulation results using real-world data set verify the effectiveness and feasibility of above mechanism.
Citation: Shiyou Chen, Baohui Li, Lanlan Rui, Jiaxing Wang, Xingyu Chen. A blockchain-based creditable and distributed incentive mechanism for participant mobile crowdsensing in edge computing[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 3285-3312. doi: 10.3934/mbe.2022152
With the popularization of portable smart devices, the advance in ubiquitous connectivity and the Internet of Things (IoT), mobile crowdsensing is becoming one of the promising applications to acquire information in the physical world of edge computing and is widely used in Smart Cities. However, most of the existing mobile crowdsensing models are based on centralized platforms, which have some problems in reality. Data storage is overly dependent on third-party platforms leading to single-point failures. Besides, trust issues seriously affect users' willingness to participate and the credibility of data. To solve these two problems, a creditable and distributed incentive mechanism based on Hyperledger Fabric (HF-CDIM) is proposed in this paper. Specifically, the HF-CDIM combines auction, reputation and data detection methods. First, we develop a multi-attribute auction algorithm with a reputation on blockchain by designing a smart contract, which achieves a distributed incentive mechanism for participants. Second, we propose a K-nearest neighbor outlier detection algorithm based on geographic location and similarity to quantify the credibility of the data. It is also used to update the user's reputation index. This guarantees the credibility of sensing data. Finally, the simulation results using real-world data set verify the effectiveness and feasibility of above mechanism.

| [1] | H. Vestberg, CEO to Shareholders: 50 Billion Connections 2020, Ericsson Inc., Stockholm, Sweden, 2010. Available from: https://www.ericsson.com/en/press-releases/2010/4/ceo-to-shareholders-50-billion-connections-2020 |
| [2] |
R. K. Ganti, F. Ye, H. Lei, Mobile crowdsensing: current state and future challenges, IEEE Commun. Mag., 49 (2011), 32–39. https://doi.org/10.1109/MCOM.2011.6069707 doi: 10.1109/MCOM.2011.6069707

|
| [3] |
R. Sánchez-Corcuera, A. Nuñez-Marcos, J. Sesma-Solance, A. Bilbao-Jayo, R. Mulero, Smart cities survey: Technologies, application domains and challenges for the cities of the future, Int. J. Distib. Sens. N., 15 (2019). https://doi.org/10.1177/1550147719853984 doi: 10.1177/1550147719853984
|
| [4] |
L. Kong, Z. Wu, G. Chen, M. Qiu, J. Rodrigues, Crowdsensing based cross-operator switch in rail transit systems, IEEE T. Commun., 68 (2020), 1–1. https://doi.org/10.1109/TCOMM.2020.3019527 doi: 10.1109/TCOMM.2020.3019527
|
| [5] |
T. Taleb, S. Dutta, A. Ksentini, M. Iqbal, H. Flinck, Mobile edge computing potential in making cities smarter, IEEE Commun. Mag., 55 (2017), 38–43. https://doi.org/10.1109/MCOM.2017.1600249CM doi: 10.1109/MCOM.2017.1600249CM
|
| [6] |
P. Bellavista, S. Chessa, L. Foschini, L. Gioia, M. Girolami, Human-enabled edge computing: Exploiting the crowd as a dynamic extension of mobile edge computing, IEEE Commun. Mag., 56 (2018), 145–155. https://doi.org/10.1109/MCOM.2017.1700385 doi: 10.1109/MCOM.2017.1700385
|
| [7] |
V. S. Dasari, B. Kantarci, M. Pouryazdan, L. Foschini, M. Girolami, Game theory in mobile crowdsensing: A comprehensive survey, Sensors, 20 (2020), 2055. https://doi.org/10.3390/s20072055 doi: 10.3390/s20072055
|
| [8] |
N. C. Luong, D. T. Hoang, P. Wang, D. Niyato, D. I. Kim, Z. Han, Data collection and wireless communication in Internet of Things (IoT) using economic analysis and pricing models: A survey, IEEE Commun. Surv. Tut., 18 (2016), 2546–2590. https://doi.org/10.1109/COMST.2016.2582841 doi: 10.1109/COMST.2016.2582841
|
| [9] |
L. Ma, X. Wang, X. Wang, L. Wang, Y. Shi, M. Huang, TCDA: Truthful combinatorial double auctions for mobile edge computing in industrial internet of things, IEEE T. Mob. Comput., 99 (2021). https://doi.org/10.1109/TMC.2021.3064314 doi: 10.1109/TMC.2021.3064314
|
| [10] |
R. Iqbal, T. A. Butt, M. Afzaal, K. Salah, Trust management in social internet of vehicles: factors, challenges, blockchain, and fog solutions, Int. J. Distrib. Sens. Netw., 15 (2018). https://doi.org/10.1177/1550147719825820 doi: 10.1177/1550147719825820
|
| [11] |
B. Guo, H. Chen, Z. Yu, W. Nan, X. Xie, D. Zhang, et al., TaskMe: Toward a dynamic and quality-enhanced incentive mechanism for mobile crowd sensing, Int. J. Hum.-Comput. Stud., 102 (2017), 14–26. https://doi.org/10.1016/j.ijhcs.2016.09.002 doi: 10.1016/j.ijhcs.2016.09.002
|
| [12] | D. Lin, Q. Wang, P. Yang, Z. Zhang, A multidimensional reputation evaluation model for mobile crowd sensing, in 2019 15th International Wireless Communications and Mobile Computing Conference, IEEE, (2019), 2070–2073. https://doi.org/10.1109/IWCMC.2019.8766533 |
| [13] |
J. Kang, Z. Xiong, S. Xie, J. Zhang, Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory, IEEE Int. Things J., 6 (2019), 10700–10714. https://doi.org/10.1109/JIOT.2019.2940820 doi: 10.1109/JIOT.2019.2940820
|
| [14] |
Q. Li, H. Cao, S. Wang, X. Zhao, A reputation-based multi-user task selection incentive mechanism for crowdsensing, IEEE Access, 8 (2020), 74887–74900. https://doi.org/10.1109/ACCESS.2020.2989406 doi: 10.1109/ACCESS.2020.2989406
|
| [15] |
J. Xu, Z. Rao, L. Xu, D. Yang, T. Li, Incentive mechanism for multiple cooperative tasks with compatible users in mobile crowd sensing via online communities, IEEE T. Mob. Comput., 19 (2019), 1618–1633. https://doi.org/10.1109/TMC.2019.2911512 doi: 10.1109/TMC.2019.2911512
|
| [16] |
Z. Luo, J. Xu, P. Zhao, D. Yang, L. Xu, J. Luo, Towards high quality mobile crowdsensing: Incentive mechanism design based on fine-grained ability reputation, Comput. Commun., 180 (2021), 197–209. https://doi.org/10.1016/j.comcom.2021.09.026 doi: 10.1016/j.comcom.2021.09.026
|
| [17] |
H. Gao, C. H. Liu, J. Tang, D. Yang, P. Hui, W. Wang, Online quality-aware incentive mechanism for mobile crowd sensing with extra bonus, IEEE T. Mob. Comput., 18 (2018), 2589–2603. https://doi.org/10.1109/TMC.2018.2877459 doi: 10.1109/TMC.2018.2877459
|
| [18] | C. Xiang, P. Yang, X. Fan, L. Gong. Quantifying sensing quality of crowd sensing networks with confidence interval, in 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, IEEE, (2017), 1–6. https://doi.org/10.1109/UIC-ATC.2017.8397538 |
| [19] |
I. Krontiris, A. Albers, Monetary incentives in participatory sensing using multi-attributive auctions, Int. J. Parallel, Emerg. Distrib. Syst., 27 (2012), 317–336. https://doi.org/10.1080/17445760.2012.686170 doi: 10.1080/17445760.2012.686170
|
| [20] |
Y. Liu, X. Xu, J. Pan, J. Zhang, G. Zhao, A truthful auction mechanism for mobile crowd sensing with budget constraint, IEEE Access, 7 (2019), 43933–43947. https://doi.org/10.1109/ACCESS.2019.2902882 doi: 10.1109/ACCESS.2019.2902882
|
| [21] |
T. Luo, J. Huang, S. S. Kanhere, J. Zhang, S. K. Das, Improving IoT data quality in mobile crowd sensing: A cross validation approach, IEEE Int. Things J., 6 (2019), 5651–5664. https://doi.org/10.1109/JIOT.2019.2904704 doi: 10.1109/JIOT.2019.2904704
|
| [22] |
Z. Zhou, X. Chen, Y. Zhang, S. Mumtaz, Blockchain-empowered secure spectrum sharing for 5G heterogeneous networks, IEEE Network, 34 (2020), 24–31. https://doi.org/10.1109/MNET.001.1900188 doi: 10.1109/MNET.001.1900188
|
| [23] | A. Gervais, G. O. Karame, K. Wüst, V. Glykantzis, H. Ritzdorf, S. Capkun, On the security and performance of proof of work blockchains, in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, (2016), 3–16. https://doi.org/10.1145/2976749.2978341 |
| [24] | I. Bentov, R. Kumaresan, How to use bitcoin to design fair protocols, in International Cryptology Conference Springer Berlin Heidelberg, (2014), 421–439. https://doi.org/10.1007/978-3-662-44381-1_24 |
| [25] | N. More, D. Motwani, A blockchain-based decentralized framework for crowdsourcing, in International Conference on Image Processing and Capsule Networks, (2020), 448–460. https://doi.org/10.1007/978-3-030-51859-2_41 |
| [26] |
B. Jia, T. Zhou, W. Li, Z. Liu, J. Zhang, A blockchain-based location privacy protection incentive mechanism in crowd sensing networks, Sensors, 18 (2018), 3894. https://doi.org/10.3390/s18113894 doi: 10.3390/s18113894
|
| [27] |
J. Wang, M. Li, Y. He, H. Li, K. Xiao, C. Wang, A blockchain based privacy-preserving incentive mechanism in crowdsensing applications, IEEE Access, 6 (2018), 17545–17556. https://doi.org/10.1109/ACCESS.2018.2805837 doi: 10.1109/ACCESS.2018.2805837
|
| [28] |
X. Lin, J. Wu, S. Mumtaz, S. Garg, J. Li, M. Guizani, Blockchain-based on-demand computing resource trading in IoV-assisted smart city, IEEE Trans.Emerg. Topics Comput., 9(2020), 1373–1385. https://doi.org/10.1109/TETC.2020.2971831 doi: 10.1109/TETC.2020.2971831
|
| [29] |
E. David, R. Azoulay-Schwartz, S. Kraus, Bidding in sealed-bid and English multi-attribute auctions, Decis. Support Syst., 42 (2007), 527–556. https://doi.org/10.1016/j.dss.2005.02.007 doi: 10.1016/j.dss.2005.02.007
|
| [30] | P. Wei, D. Wang, Y. Zhao, S. K. S. Tyagi, N. Kumar, Blockchain data-based cloud data integrity protection mechanism, Future Generat. Comput. Syst., 102 (2020), 902–911. https://doi.org/0.1016/j.future.2019.09.028 |
| [31] | Crawdad Citation CRAWDAD Dataset, 2015. Available from: http://crawdad.org/ |
| [32] | S. Lu, X. Wei, Y. Li, L. Wang, Detecting anomaly in big data system logs using convolutional neural network, in 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress, (2018), 151–158. https://doi.org/10.1109/DASC/PiCom/DataCom/CyberSciTec.2018.00037 |
Figures(13) / Tables(4)

Shiyou Chen, Baohui Li, Lanlan Rui, Jiaxing Wang, Xingyu Chen. A blockchain-based creditable and distributed incentive mechanism for participant mobile crowdsensing in edge computing[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 3285-3312. doi: 10.3934/mbe.2022152







 DownLoad:
DownLoad: