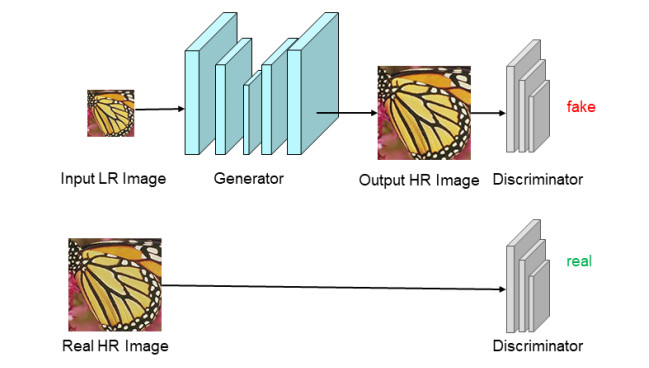
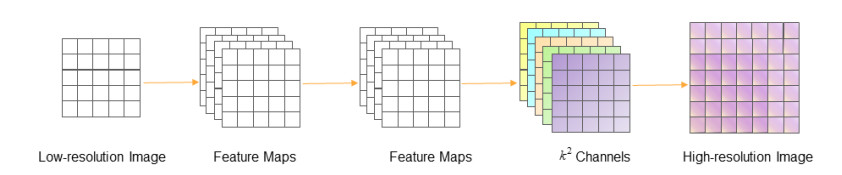
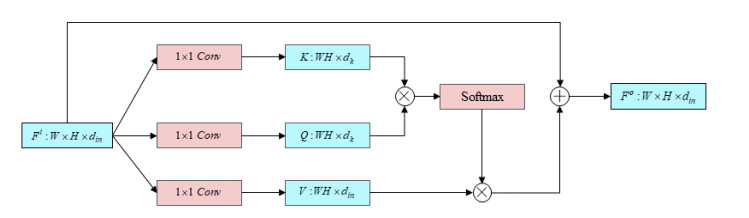
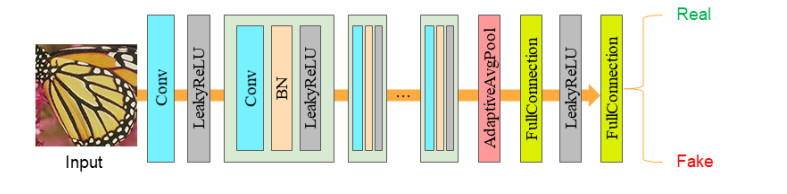
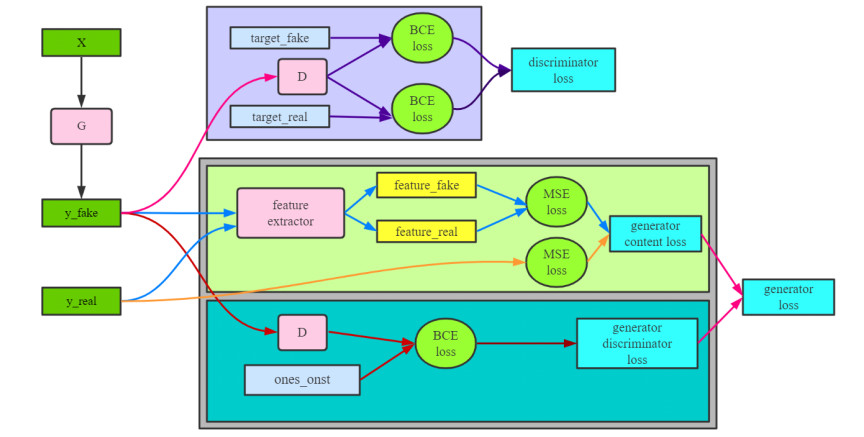
The image super-resolution reconstruction method can improve the image quality in the Internet of Things (IoT). It improves the data transmission efficiency, and is of great significance to data transmission encryption. Aiming at the problem of low image quality in image super-resolution using neural networks, a self-attention-based image reconstruction method is proposed for secure data transmission in IoT environment. The network model is improved, and the residual network structure and sub-pixel convolution are used to extract the feature of the image. The self-attention module is used extract detailed information in the image. Using generative confrontation method and image feature perception method to improve the image reconstruction effect. The experimental results on the public data set show that the improved network model improves the quality of the reconstructed image and can effectively restore the details of the image.
Citation: Hongan Li, Qiaoxue Zheng, Wenjing Yan, Ruolin Tao, Xin Qi, Zheng Wen. Image super-resolution reconstruction for secure data transmission in Internet of Things environment[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 6652-6671. doi: 10.3934/mbe.2021330
The image super-resolution reconstruction method can improve the image quality in the Internet of Things (IoT). It improves the data transmission efficiency, and is of great significance to data transmission encryption. Aiming at the problem of low image quality in image super-resolution using neural networks, a self-attention-based image reconstruction method is proposed for secure data transmission in IoT environment. The network model is improved, and the residual network structure and sub-pixel convolution are used to extract the feature of the image. The self-attention module is used extract detailed information in the image. Using generative confrontation method and image feature perception method to improve the image reconstruction effect. The experimental results on the public data set show that the improved network model improves the quality of the reconstructed image and can effectively restore the details of the image.

| [1] |
J. Zhang, K. Yu, Z. Wen, X. Qi, A. K. Paul, 3D Reconstruction for Motion Blurred Images Using Deep Learning-Based Intelligent Systems, CMC Comput. Mater. Continua, 66 (2021), 2087-2104. doi: 10.32604/cmc.2020.014220

|
| [2] | W. Wang, H. Xu, M. Alazab, T. R. Gadekallu, Z. Han, C. Su, Blockchain-Based Reliable and Efficient Certificateless Signature for IIoT Devices, IEEE Trans. Ind. Inf., 2021. Available from: https://ieeexplore.ieee.org/document/9444140. |
| [3] |
L. Tan, H. Xiao, K. Yu, M. Aloqaily, Y. Jararweh, A blockchain-empowered crowdsourcing system for 5g-enabled smart cities, Comput. Stand. Interfaces, 76 (2021), 103517. doi: 10.1016/j.csi.2021.103517
|
| [4] |
L. Zhen, Y. Zhang, K. Yu, N. Kumar, A. Barnawi, Y. Xie, Early Collision Detection for Massive Random Access in Satellite-Based Internet of Things, IEEE Trans. Veh. Technol., 70 (2021), 5184-5189. doi: 10.1109/TVT.2021.3076015
|
| [5] |
B. C. Chifor, I. Bica, V. V. Patriciu, F. Pop, A security authorization scheme for smart home Internet of Things devices, Future Gener. Comput. Syst., 86 (2018), 740-749. doi: 10.1016/j.future.2017.05.048
|
| [6] | L. Zhang, Z. Zhang, W. Wang, Z. Jin, Y. Su, H. Chen, Research on a covert communication model realized by using smart contracts in blockchain environment, IEEE Syst. J., 2021 (2021), 1-12. |
| [7] |
B. B. Zarpelão, R. S. Miani, S. Rodrigo, C. T. Kawakani, Miani, S. C. de Alvarenga, A survey of intrusion detection in Internet of Things, J. Network Comput. Appl., 84 (2017), 25-37. doi: 10.1016/j.jnca.2017.02.009
|
| [8] | L. Zhen, A. K. Bashir, K. Yu, Y. D. Al-Otaibi, C. H. Foh, P. Xiao, Energy-efficient random access for LEO satellite-assisted 6G Internet of remote things, IEEE Internet Things J., 8 (2020), 5114-5128. |
| [9] |
C. Feng, K. Yu, A. K. Bashir, Y. D. Al-Otaibi, Y. Lu, S. Chen, D. Zhang, Efficient and secure data sharing for 5G flying drones: a blockchain-enabled approach, IEEE Network, 35 (2021), 130-137. doi: 10.1109/MNET.011.2000223
|
| [10] | C. Feng, K. Yu, M. Aloqaily, M. Alazab, Z. Lv, S. Mumtaz, Attribute-based encryption with parallel outsourced decryption for edge intelligent IoV, IEEE Trans. Veh. Technol., 69 (2020), 213784-13795. |
| [11] | H. Li, K. Yu, B. Liu, C. Feng, Z. Qin and G. Srivastava, An Efficient ciphertext-policy weighted attribute-based encryption for the internet of health things, IEEE J. Biomed. Health Inf., 2021. Available from: https://ieeexplore.ieee.org/document/9416735. |
| [12] | D. Qiu, L. Zheng, S. Zhang, Y. Liu, An Image Super-resolution Reconstruction Method by Using of Deep Learning, in 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), (2019), 213-217. |
| [13] | Y. Yang, H. Cai, Z. Wei, H. Lu, K. K. R. Choo, Towards lightweight anonymous entity authentication for IoT applications, in Australasian conference on information security and privacy, Springer, Cham, (2016), 265-280. |
| [14] |
C. Sun, J. Lv, J. Li, R. Qiu, A rapid and accurate infrared image super-resolution method based on zoom mechanism, Infrared Phys. Technol., 88 (2018), 228-238. doi: 10.1016/j.infrared.2017.11.033
|
| [15] |
X. Feng, J. Li, Z. Hua, Guided filter-based multi-scale super-resolution reconstruction, CAAI Trans. Intell. Technol., 5 (2020), 128-140. doi: 10.1049/trit.2019.0065
|
| [16] |
Z. Huang, C. Jing, Super-resolution reconstruction method of remote sensing image based on multi-feature fusion, IEEE Access, 8 (2020), 18764-18771. doi: 10.1109/ACCESS.2020.2967804
|
| [17] | N. Shi, L. Tan, W. Li, X. Qi, K. Yu, A Blockchain-Empowered AAA Scheme in the Large-Scale HetNet, Digital Commun. Networks, 2021. Available from: https://doi.org/10.1016/j.dcan.2020.10.002. |
| [18] | Z. Guo, A. K. Bashir, K. Yu, J. C. Lin, Y. Shen, Graph Embedding-based Intelligent Industrial Decision for Complex Sewage Treatment Processes, Int. J. Intell. Syst., 2020. Available from: https://doi.org/10.1002/int.22540. |
| [19] |
G. T. Reddy, M. P. K. Reddy, K. Lakshmanna, R. Kaluri, D. S. Rajput, G. Srivastava, T. Baker, SAnalysis of dimensionality reduction techniques on big data, IEEE Access, 8 (2020), 54776-54788. doi: 10.1109/ACCESS.2020.2980942
|
| [20] |
L. Zhang, Y. Zou, W. Wang, Z. Jin, Y. Su, H. Chen, Resource allocation and trust computing for blockchain-enabled edge computing system, Comput. Secur., 105 (2021), 102249. doi: 10.1016/j.cose.2021.102249
|
| [21] |
X. Yao, Q. Wu, P. Zhang, F. X. Bao, Adaptive rational fractal interpolation function for image super-resolution via local fractal analysis, Image Vision Comput., 82 (2019), 39-49. doi: 10.1016/j.imavis.2019.02.002
|
| [22] | J. Song, Q. Zhong, W. Wang, C. Su, Z. Tan, Y. Liu, FPDP: Flexible privacy-preserving data publishing scheme for smart agriculture, IEEE Sens. J., 2020. Available from: https://ieeexplore.ieee.org/document/9170612. |
| [23] | W. Wang, H. Huang, L. Zhang, C. Su, Secure and efficient mutual authentication protocol for smart grid under blockchain, Peer Peer Networking Appl., 2020 (2020), 1-13. |
| [24] | L. Wang, S. Yang, J. Jia, A super-resolution reconstruction algorithm based on feature fusion, 2020 39th Chinese Control Conference (CCC), (2020), 3060-30605. |
| [25] |
R. R. Schultz, R. L. Stevenson, A Bayesian approach to image expansion for improved definition, IEEE Trans. Image Process., 3 (1994), 233-242. doi: 10.1109/83.287017
|
| [26] | M. Yu, H. Wang, M. Liu, P. Li, Overview of Research on Image Super-Resolution Reconstruction, 2021 IEEE International Conference on Information Communication and Software Engineering (ICICSE), (2011), 131-135. |
| [27] | K. T. Gribbon, D. G. Bailey, A novel approach to real-time bilinear interpolation, in Proceedings. DELTA 2004. Second IEEE International Workshop on Electronic Design, Test and Applications, (2004), 126-131. |
| [28] |
R. Keys, Cubic convolution interpolation for digital image processing, IEEE Trans. Acoust. Speech Signal Process., 29 (1981), 1153-1160. doi: 10.1109/TASSP.1981.1163711
|
| [29] | R. Tsai, Multiframe image restoration and registration, Adv. Comput. Visual Image Process., 1 (1984), 317-339. |
| [30] |
Y. Abe, Y. J. Iiguni, Image restoration from a downsampled image by using the DCT, Signal Process., 87 (2007), 2370-2380. doi: 10.1016/j.sigpro.2007.03.010
|
| [31] | P. Liu, H. Zhang, K. Zhang, L. Lin, W. Zuo, Multi-level wavelet-CNN for image restoration, Proceedings of the IEEE conference on computer vision and pattern recognition workshops, (2018), 773-782. |
| [32] |
S. W. Jung, T. H. Kim, S. J. Ko, A novel multiple image deblurring technique using fuzzy projection onto convex sets, IEEE Signal Process. Lett., 16 (2009), 192-195. doi: 10.1109/LSP.2008.2012227
|
| [33] | C. Dong, C. C. G. Loy, K. M. He, X. O. Tang, Learning a deep convolutional network for image super-resolution, European conference on computer vision, (2014), 184-199. |
| [34] |
D. Sun, Q. Gao, Y. Lu, Z. Huang, T. Li, A novel image denoising algorithm using linear Bayesian MAP estimation based on sparse representation, Signal Process., 100 (2014), 132-145. doi: 10.1016/j.sigpro.2014.01.022
|
| [35] | H. Li, Q. Zheng, J. Zhang, Z. Du, Z. Li, B. Kang, Pix2Pix-Based Grayscale Image Coloring Method, J. Comput.-Aided Comput. Graphics, 33 (2021), 929-938. |
| [36] | J. Kim, J. K. Lee, K. M. Lee, Accurate image super-resolution using very deep convolutional networks, Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 1646-1654. |
| [37] | K. Yu, L. Lin, M. Alazab, L. Tan, B. Gu, Deep learning-based traffic safety solution for a mixture of autonomous and manual vehicles in a 5G-enabled intelligent transportation system, IEEE Trans. Intell. Transp. Syst., 22 (2020), 4337-4347. |
| [38] |
K. Yu, L. Tan, M. Aloqaily, H. Yang, Y. Jararweh, Blockchain-enhanced data sharing with traceable and direct revocation in IIoT, IEEE Trans. Ind. Inf., 17 (2021), 7669-7678. doi: 10.1109/TII.2021.3049141
|
| [39] | C. Y. Ma, J. W. Zhu, Y. J. Li, J. R. Li, Y. Jiang, X. Li, Single image super resolution via wavelet transform fusion and SRFeat network, J. Ambient Intell. Hum. Comput., (2020), 1-9. |
| [40] |
K. Yu, M. Arifuzzaman, Z. Wen, D. Zhang, T. Sato, A Key Management Scheme for Secure Communications of Information Centric Advanced Metering Infrastructure in Smart Grid, IEEE Trans. Instrum. Meas., 64 (2015), 2072-2085. doi: 10.1109/TIM.2015.2444238
|
| [41] | L. Tan, K. Yu, A. K. Bashir, X. Cheng, F. Ming, L. Zhao, et al., Towards Real-time and Efficient Cardiovascular Monitoring for COVID-19 Patients by 5G-Enabled Wearable Medical Devices: A Deep Learning Approach, Neural Compu. Appl., 2021. Available from: https://doi.org/10.1007/s00521-021-06219-9. |
| [42] | M. A. Talab, S. Awang, S. A. M. Najim, Super-low resolution face recognition using integrated efficient sub-pixel convolutional neural network (ESPCN) and convolutional neural network (CNN), 2019 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), (2019), 331-335. |
| [43] | C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, et al., Photo-realistic single image super-resolution using a generative adversarial network, Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 4681-4690. |
| [44] |
A. Wang, Z. Fang, Y. Gao, X. Jiang, S. Ma, Depth estimation of video sequences with perceptual losses, IEEE Access, 6 (2018), 30536-30546. doi: 10.1109/ACCESS.2018.2846546
|
| [45] | B. Lim, S. Son, H. Kim, S. Nah, K. Mu Lee, Enhanced deep residual networks for single image super-resolution, Proceedings of the IEEE conference on computer vision and pattern recognition workshops, (2017), 136-144. |
| [46] | L. Tan, N. Shi, K. Yu, M. Aloqaily, Y. Jararweh, A Blockchain-Empowered Access Control Framework for Smart Devices in Green Internet of Things, ACM Trans. Internet Technol., 21 (2021), 1-20. |
| [47] | Z. Guo, K. Yu, A. Jolfaei, A. K. Bashir, A. O. Almagrabi, N. Kumar, A Fuzzy Detection System for Rumors through Explainable Adaptive Learning, IEEE Trans. Fuzzy Syst., 2021. Available from: https://doi.org/10.1109/TFUZZ.2021.3052109. |
| [48] |
L. Guo, M. Woźniak, An image super-resolution reconstruction method with single frame character based on wavelet neural network in internet of things, Mobile Networks Appl., 26 (2021), 390-403. doi: 10.1007/s11036-020-01681-6
|
| [49] | W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, et al., Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network, Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 1874-1883. |
| [50] |
A. Creswell, T. White, V. Dumoulin, K. Arulkumaran, V. Sengupta, A. A. Bharath, Generative adversarial networks: An overview, IEEE Signal Process. Mag., 35 (2018), 53-65. doi: 10.1109/MSP.2017.2765202
|
| [51] | M. Yu, H. Wang, M. Liu, P. Li, Overview of Research on Image Super-Resolution Reconstruction, 2021 IEEE International Conference on Information Communication and Software Engineering (ICICSE), (2021), 131-135. |
| [52] | S. Lei, X. Liao, Z. Tao, Content-aware Upsampling for Single Image Super-resolution, 2020 Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), (2020), 213-217. |
| [53] | S. E. El-Khamy, M. M. Hadboud, M. I. Dessouky, B. M. Salam, F. E. A. El-Samie, A new super-resolution image reconstruction algorithm based on wavelet fusion, Proceedings of the Twenty-Second National Radio Science Conference, 2005. NRSC 2005., (2005), 195-204. |
| [54] |
D. Mualfah, Y. Fatma, R. Ramadhan, Anti-forensics: The image asymmetry key and single layer perceptron for digital data security, Journal of Physics: Conference Series, 1517 (2020), 012106. doi: 10.1088/1742-6596/1517/1/012106
|
| [55] | J. Johnson, A. Alahi, L. Fei-Fei, Perceptual losses for real-time style transfer and super-resolution, European conference on computer vision, (2016), 694-711. |
| [56] |
K. Fu, J Peng, H. Zhang, X. Wang, J. Frank, Image super-resolution based on generative adversarial networks: a brief review, Comput. Mater. Continua, 64 (2020), 1977-1997. doi: 10.32604/cmc.2020.09882
|
| [57] | M. Heon, J. H. Kim, J. H. Choi, J. S. Lee, Generative adversarial network-based image super-resolution using perceptual content losses, Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018. |
| [58] |
Z. Guo, L. Tang, T. Guo, K. Yu, M. Alazab, A. Shalaginov, Deep graph neural network-based spammer detection under the perspective of heterogeneous cyberspace, Future Gener. Comput. Syst., 117 (2021), 205-218. doi: 10.1016/j.future.2020.11.028
|
| [59] | K. Yu, L. Tan, X. Shang, J. Huang, G. Srivastav, P. Chatterjee, Efficient and Privacy-Preserving Medical Research Support Platform Against COVID-19: A Blockchain-Based Approach, IEEE Consum. Electron. Mag., 10 (2021), 111-120. |
| [60] |
D. Lee, S. Lee, H. Lee, K. Lee, H. J. Lee, Resolution-preserving generative adversarial networks for image enhancement, IEEE Access, 7 (2019), 110344-110357. doi: 10.1109/ACCESS.2019.2934320
|
| [61] | C. F. Song, Y. Huang, W. L. Ouyang, L. Wang, Mask-guided contrastive attention model for person re-identification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 1179-1188. |
| [62] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Advances in neural information processing systems, (2017), 5998-6008. |
| [63] | A. N. Moldovan, I. Ghergulescu, C. H. Muntean, A novel methodology for mapping objective video quality metrics to the subjective MOS scale, 2014 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, (2014), 1-7. |
| [64] |
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality assessment: from error visibility to structural similarity, IEEE Trans. Image Process., 13 (2004), 600-612. doi: 10.1109/TIP.2003.819861
|
| [65] |
K. Yu, L. Tan, L. Lin, X. Cheng, Z. Yi, T. Sato, Deep Learning Empowered Breast Cancer Auxiliary Diagnosis for 5GB Remote E-Health, IEEE Wireless Commun., 28 (2021), 54-61. doi: 10.1109/MWC.001.2000374
|
| [66] | L. Tan, K. Yu, F. Ming, X. Cheng, G. Srivastava, Secure and Resilient Artificial Intelligence of Things: a HoneyNet Approach for Threat Detection and Situational Awareness, IEEE Consum. Electron. Mag., 2021. Available from: https://doi.org/10.1109/MCE.2021.3081874. |
| [67] | Z. Guo, K. Yu, Y. Li, G. Srivastava, J. C. W. Lin, Deep Learning-Embedded Social Internet of Things for Ambiguity-Aware Social Recommendations, IEEE Trans. Network Sci. Eng., 2021. Available from: https://doi.org/10.1109/TNSE.2021.3049262. |
| [68] | K. Yu, Z. Guo, Y. Shen, W. Wang, J. C. Lin, T. Sato, Secure Artificial Intelligence of Things for Implicit Group Recommendations, IEEE Internet Things J., 2021. Available from: http://dx.doi.org/10.1109/JIOT.2021.3079574. |



Figures(8) / Tables(5)

Hongan Li, Qiaoxue Zheng, Wenjing Yan, Ruolin Tao, Xin Qi, Zheng Wen. Image super-resolution reconstruction for secure data transmission in Internet of Things environment[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 6652-6671. doi: 10.3934/mbe.2021330







 DownLoad:
DownLoad: