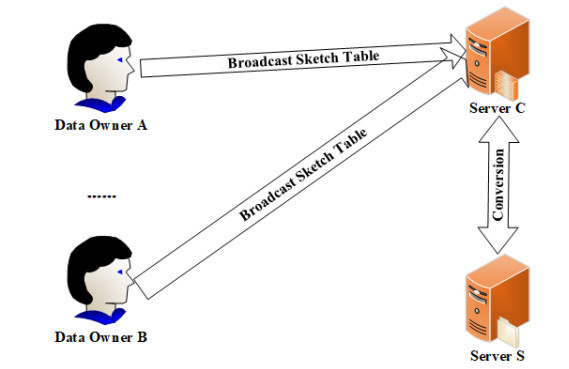
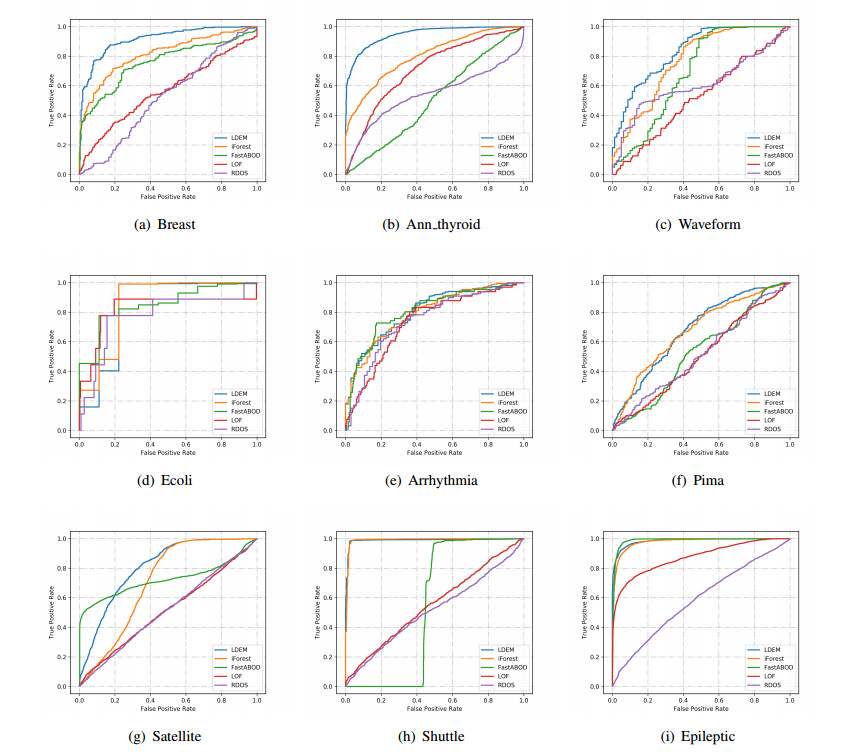
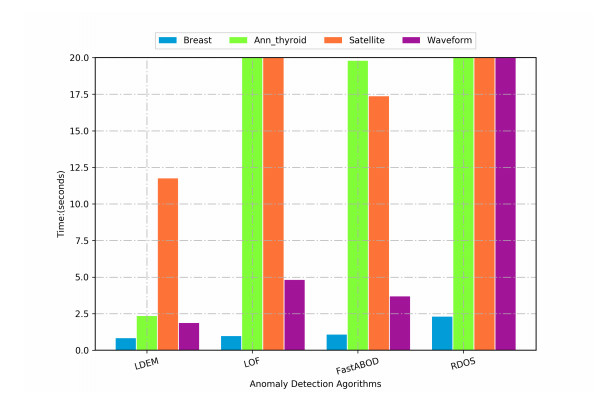
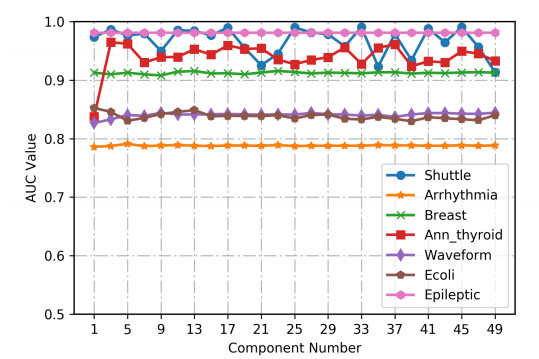
Anomaly detection has been widely researched in financial, biomedical and other areas. However, most existing algorithms have high time complexity. Another important problem is how to efficiently detect anomalies while protecting data privacy. In this paper, we propose a fast anomaly detection algorithm based on local density estimation (LDEM). The key insight of LDEM is a fast local density estimator, which estimates the local density of instances by the average density of all features. The local density of each feature can be estimated by the defined mapping function. Furthermore, we propose an efficient scheme named PPLDEM based on the proposed scheme and homomorphic encryption to detect anomaly instances in the case of multi-party participation. Compared with existing schemes with privacy preserving, our scheme needs less communication cost and less calculation cost. From security analysis, our scheme will not leak privacy information of participants. And experiments results show that our proposed scheme PPLDEM can detect anomaly instances effectively and efficiently, for example, the recognition of activities in clinical environments for healthy older people aged 66 to 86 years old using the wearable sensors.
Citation: Chunkai Zhang, Ao Yin, Wei Zuo, Yingyang Chen. Privacy preserving anomaly detection based on local density estimation[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3478-3497. doi: 10.3934/mbe.2020196
Anomaly detection has been widely researched in financial, biomedical and other areas. However, most existing algorithms have high time complexity. Another important problem is how to efficiently detect anomalies while protecting data privacy. In this paper, we propose a fast anomaly detection algorithm based on local density estimation (LDEM). The key insight of LDEM is a fast local density estimator, which estimates the local density of instances by the average density of all features. The local density of each feature can be estimated by the defined mapping function. Furthermore, we propose an efficient scheme named PPLDEM based on the proposed scheme and homomorphic encryption to detect anomaly instances in the case of multi-party participation. Compared with existing schemes with privacy preserving, our scheme needs less communication cost and less calculation cost. From security analysis, our scheme will not leak privacy information of participants. And experiments results show that our proposed scheme PPLDEM can detect anomaly instances effectively and efficiently, for example, the recognition of activities in clinical environments for healthy older people aged 66 to 86 years old using the wearable sensors.

| [1] | D. M. Hawkins, Identification of Outliers, Springer, (1980). |
| [2] | E. M. Knox, R. T. Ng, Algorithms for mining distancebased outliers in large datasets, Proceedings of the international conference on very large data bases, Citeseer, 1998,392-403. Available from: https://dl.acm.org/doi/10.5555/645924.671334. |
| [3] | X. Wang, X. L. Wang, M. Wilkes, A fast distance-based outlier detection technique, Industrial Conference on Data Mining-Poster and Workshop, 2008, 25-44. Available from: https://www.researchgate.net/publication/26621806 A Fast DistanceBased Algorithm to Detect Outliers. |
| [4] | M. Sugiyama, K. Borgwardt, Rapid distance-based outlier detection via sampling, Advances in Neural Information Processing Systems, 2013,467-475. Available from: http://papers.nips.cc/paper/5127-rapid-distance-based-outlier-detection-via-sampling. |
| [5] |
Z. He, X. Xu, S. Deng, Discovering cluster-based local outliers, Pattern Recognit. Lett., 24 (2003), 1641-1650. doi: 10.1016/S0167-8655(03)00003-5

|
| [6] | Z. Chen, A. W. C. Fu, J. Tang, On complementarity of cluster and outlier detection schemes, International Conference on Data Warehousing and Knowledge Discovery, Springer, 2003,234-243. Available from: https://link.springer.com/chapter/10.1007/978-3-540-45228-7_24. |
| [7] | C. Zhang, H. Liu, A. Yin, Research of detection algorithm for time series abnormal subsequence, International Conference of Pioneering Computer Scientists, Engineers and Educators, Springer, 2017, 12-26. Available from: https://link.springer.com/chapter/10.1007/978-981-10-6385-52. |
| [8] | C. Zhang, A. Yin, Y. Wu, Y. Chen, X. Wang, Fast time series discords detection with privacy preserving, 2018 17th IEEE International Conference On Trust, Security And Privacy In Computing And Communications (TrustCom), IEEE, 2018, 1129-1139. Available from: https://ieeexplore.ieee.org/abstract/document/8456026. |
| [9] | H. P. Kriegel, M. Schubert, A. Zimek, Angle-based outlier detection in highdimensional data, Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, 2008,444-452. Available from: https://dl.acm.org/doi/abs/10.1145/1401890.1401946. |
| [10] | N. Pham, R. Pagh, A near-linear time approximation algorithm for angle-based outlier detection in high-dimensional data, Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 2012,877-885. Available from: https://dl.acm.org/doi/abs/10.1145/2339530.2339669. |
| [11] | M. M. Breunig, H. P. Kriegel, R. T. Ng, J. Sander, Lof: identifying densitybased local outliers, ACM sigmod record, 2000, 93-104. Available from: https://dl.acm.org/doi/abs/10.1145/342009.335388. |
| [12] | J. Gao, W. Hu, Z. M. Zhang, X. Zhang, O. Wu, Rkof: Robust kernel-based local outlier detection, Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2011,270-283. Available from: https://link.springer.com/chapter/10.1007/978-3-642-20847-823. |
| [13] |
L. Duan, L. Xu, G. Feng, J. Lee, B. Yan, A local-density based spatial clustering algorithm with noise, Inf. Syst., 32 (2007), 978-986. doi: 10.1016/j.is.2006.10.006
|
| [14] |
B. Tang, H. He, A local density-based approach for outlier detection, Neurocomputing, 241 (2017), 171-180. doi: 10.1016/j.neucom.2017.02.039
|
| [15] | C. Zhang, A. Yin, Y. Deng, P. Tian, X. Wang, L. Dong, A novel anomaly detection algorithm based on trident tree, International Conference on Cloud Computing, 2018,295-306. Available from: https://link.springer.com/chapter/10.1007/978-3-319-94295-720. |
| [16] | M. Kantarcıoglu, C. Clifton, Privately computing a distributed k-nn classifier, PKDD2004: 8th European Conference on Principles and Practice of Knowledge Discovery in Databases, Pisa, Italy, 2004,279-290. Available from: https://link.springer.com/chapter/10.1007/978-3-540-30116-5_27. |
| [17] |
X. Lin, C. Clifton, M. Zhu, Privacy-preserving clustering with distributed em mixture modeling, Knowl. Inf. Syst., 8 (2005), 68-81. doi: 10.1007/s10115-004-0148-7
|
| [18] |
L. Li, L. Huang, W. Yang, X. Yao, A. Liu, Privacy-preserving lof outlier detection, Knowl. Inf. Syst., 42 (2015), 579-597. doi: 10.1007/s10115-013-0692-0
|
| [19] |
C. Zhang, Y. Zhou, J. Guo, G. Wang, X. Wang, Research on classification method of highdimensional class-imbalanced data sets based on svm, Int. J. Mach. Learn. Cybern., 10 (2019), 1765-1778. doi: 10.1007/s13042-018-0853-2
|
| [20] | L. T. Dung, H. T. Bao, A distributed solution for privacy preserving outlier detection, 2011 Third International Conference on Knowledge and Systems Engineering, 2011, 26-31. Available from: https://ieeexplore.ieee.org/abstract/document/6063441. |
| [21] |
T. Li, Z. Huang, P. Li, Z. Liu, C. Jia, Outsourced privacy-preserving classification service over encrypted data, J. Network Comput. Appl., 106 (2018), 100-110. doi: 10.1016/j.jnca.2017.12.021
|
| [22] |
Z. Yu, C. Gao, Z. Jing, B. B. Gupta, Q. Cai, A practical public key encryption scheme based on learning parity with noise, IEEE Access, 6 (2018), 31918-31923. doi: 10.1109/ACCESS.2018.2840119
|
| [23] | T. Li, W. Chen, Y. Tang, H. Yan, A homomorphic network coding signature scheme for multiple sources and its application in iot, Secur. Commun. Networks, 2018 (2018), 9641273. |
| [24] |
R. H. Jhaveri, N. M. Patel, Y. Zhong, A. K. Sangaiah, Sensitivity analysis of an attack-pattern discovery based trusted routing scheme for mobile ad-hoc networks in industrial Iot, IEEE Access, 6 (2018), 20085-20103. doi: 10.1109/ACCESS.2018.2822945
|
| [25] |
C. Gao, S. Lv, Y. Wei, Z. Wang, Z. Liu, X. Cheng, M-sse: An effective searchable symmetric encryption with enhanced security for mobile devices, IEEE Access, 6 (2018), 38860-38869. doi: 10.1109/ACCESS.2018.2852329
|
| [26] | M. Xi, J. Wu, J. Li, G. Li, Sema-icn: Toward semantic informationcentric networking supporting smart anomalous access detection, 2018 IEEE Global Communications Conference (GLOBECOM), 2018, 1-6. Available from: https://ieeexplore.ieee.org/abstract/document/8647325. |
| [27] | V. Sharma, R.KUMAR, W. Cheng, M. Atiquzzaman, K. Srinivasan, A. Y. Zomaya, Nhad: Neurofuzzy based horizontal anomaly detection in online social networks, IEEE Trans. Knowl. Data Eng., 30 (2018), 2171-2184. |
| [28] |
T. ElGamal, A public key cryptosystem and a signature scheme based on discrete logarithms, IEEE Trans. Inf. Theory, 31 (1985), 469-472. doi: 10.1109/TIT.1985.1057074
|
| [29] | R. Bendlin, I. Damgård, C. Orlandi, S. Zakarias, Semi-homomorphic encryption and multiparty computation, Annual International Conference on the Theory and Applications of Cryptographic Techniques Springer, 2011,169-188. Available from: https://link.springer.com/chapter/10.1007/978-3-642-20465-411. |
| [30] | I. Damgård, V. Pastro, N. Smart, S. Zakarias, Multiparty computation from somewhat homomorphic encryption, Advances in Cryptology-CRYPTO 2012, Springer, 2012,643-662. Available from: https://link.springer.com/chapter/10.1007/978-3-642-32009-538. |
| [31] |
A. Peter, E. Tews, S. Katzenbeisser, Efficiently outsourcing multiparty computation under multiple keys, IEEE Trans. Inf. Forensics Secur., 8 (2013), 2046-2058. doi: 10.1109/TIFS.2013.2288131
|
| [32] |
X. Liu, R. H. Deng, K. K. R. Choo, J. Weng, An efficient privacy-preserving outsourced calculation toolkit with multiple keys, IEEE Trans. Inf. Forensics Secur., 11 (2016), 2401-2414. doi: 10.1109/TIFS.2016.2573770
|
| [33] | E. Bresson, D. Catalano, D. Pointcheval, A simple public-key cryptosystem with a double trapdoor decryption mechanism and its applications, International Conference on the Theory and Application of Cryptology and Information Security, Advances in Cryptology-ASIACRYPT 2003, 37-54. Available from: https://link.springer.com/chapter/10.1007/978-3-540-40061-53. |
| [34] | S. Sathe, C. C. Aggarwal, Subspace outlier detection in linear time with randomized hashing, Data Mining (ICDM), 2016 IEEE 16th International Conference on, IEEE, 2016,459-468. Available from: https://ieeexplore.ieee.org/abstract/document/7837870. |
| [35] |
W. Harper, Statistics: Theory and methods, Technometrics, 33 (1991), 369-370. doi: 10.1080/00401706.1991.10484855
|
| [36] |
C. C. Aggarwal, S. Sathe, Theoretical foundations and algorithms for outlier ensembles, ACM SIGKDD Explor. Newsl., 17 (2015), 24-47. doi: 10.1145/2830544.2830549
|
| [37] | Y. Chen, E. Keogh, B. Hu, N. Begum, A. Bagnall, A. Mueen, et al., The ucr time series classification archive, 2015, Available from: www.cs.ucr.edu/eamonn/timeseries data/. |
| [38] | F. T. Liu, K. M. Ting, Z. H. Zhou, Isolation forest, Eighth IEEE International Conference on Data Mining, IEEE, 2008,413-422. Available from: https://ieeexplore.ieee.org/abstract/document/4781136. |
| [39] | F. T. Liu, K. M. Ting, Z. H. Zhou, Isolation-based anomaly detection, ACM Trans. Knowl. Discovery Data, 6 (2012), 3. |
| [40] |
R. L. S. Torres, R. Visvanathan, S. Hoskins, A. V. D. Hengel, D. C. Ranasinghe, Effectiveness of a batteryless and wireless wearable sensor system for identifying bed and chair exits in healthy older people, Sensors, 16 (2016), 546. doi: 10.3390/s16040546
|
| [41] | S. Goldwasser, S. Micali, Probabilistic encryption, J. Comput. Syst. Sci., 28 (1984), 270-299. |
Figures(4) / Tables(9)

Chunkai Zhang, Ao Yin, Wei Zuo, Yingyang Chen. Privacy preserving anomaly detection based on local density estimation[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3478-3497. doi: 10.3934/mbe.2020196







 DownLoad:
DownLoad: