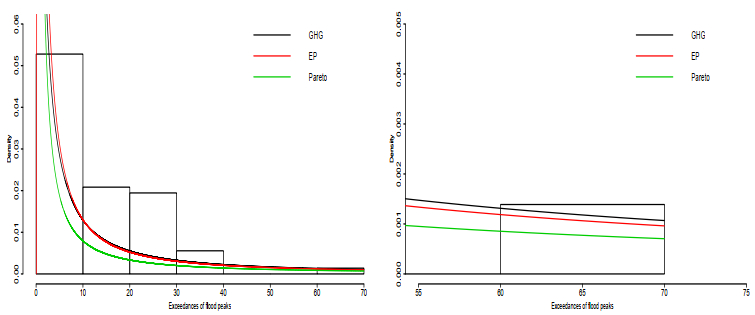
We introduced the Gauss hypergeometric Gleser (GHG) distribution, a novel extension of the Gleser (G) distribution that unifies families of Gleser distributions. We studied their representations and some basic properties and showed that the GHG distribution is heavy-tailed. The maximum likelihood method is used for parameter estimation, and the Fisher information matrix derived. We assessed the performance of the maximum likelihood estimators via Monte Carlo simulations. Moreover, we present applications to two data sets in which the GHG distribution shows a better fit than other known distributions.
Citation: Neveka M. Olmos, Emilio Gómez-Déniz, Osvaldo Venegas. The Gauss hypergeometric Gleser distribution with applications to flood peaks exceedance and income data[J]. AIMS Mathematics, 2025, 10(6): 13575-13593. doi: 10.3934/math.2025611
We introduced the Gauss hypergeometric Gleser (GHG) distribution, a novel extension of the Gleser (G) distribution that unifies families of Gleser distributions. We studied their representations and some basic properties and showed that the GHG distribution is heavy-tailed. The maximum likelihood method is used for parameter estimation, and the Fisher information matrix derived. We assessed the performance of the maximum likelihood estimators via Monte Carlo simulations. Moreover, we present applications to two data sets in which the GHG distribution shows a better fit than other known distributions.

| [1] | R. Ibragimov, A. Prokhorov, Heavy tails and copulas: topics in dependence modelling in economics and finance, Singapore: World Scientific, 2017. https://doi.org/10.1142/9644 |
| [2] |
I. B. Aban, M. M. Meerschaert, A. K. Panorska, Parameter estimation for the truncated Pareto distribution, J. Am. Stat. Assoc., 101 (2006), 270–277. https://doi.org/10.1198/016214505000000411 doi: 10.1198/016214505000000411

|
| [3] | B. C. Arnold, Pareto distributions, 2 Eds., Boca Raton: Chapman & Hall, 2015. https://doi.org/10.1201/b18141 |
| [4] | N. L. Johnson, S. Kotz, N. Balakrishnan, Continuous univariate distributions, 2 Eds., Vol. 1, New York: Wiley, 1995. |
| [5] |
J. Pickands, Statistical inference using extreme order statistics, Ann. Statist., 3 (1975), 119–131. https://doi.org/10.1214/aos/1176343003 doi: 10.1214/aos/1176343003
|
| [6] | V. Choulakian, M. A. Stephens, Goodness-of-fit for the generalized Pareto distribution, Technometrics, 43 (2001), 478–484. |
| [7] | A. C. Davison, R. L. Smith, Models for exceedances over high thresholds, J. R. Stat. Soc., Ser. B, 52 (1990), 393–442. |
| [8] |
R. C. Gupta, P. L. Gupta, R. D. Gupta, Modeling failure time data by Lehman alternatives, Commun. Stat. Theory Methods, 27 (1998), 887–904. https://doi.org/10.1080/03610929808832134 doi: 10.1080/03610929808832134
|
| [9] | G. Stoppa, Proprieta campionarie di un nuovo modello Pareto generalizzato, Proceedings of the Atti XXXV Riunione Scientifica della Societa Italiana di Statistica, Cedam: Padova, Italy, 1990,137–144. |
| [10] | C. Kleiber, S. Kotz, Statistical size distributions in economics and actuarial sciences, Haboken: John Wiley & Sons, 2003. https://doi.org/10.1002/0471457175 |
| [11] | A. Akinsete, F. Famoye, C. Lee, The Beta-Pareto distribution, Statistics, 42 (2008), 547–563. |
| [12] |
B. Boumaraf, N. Seddik-Ameur, V. S. Barbu, Estimation of Beta-Pareto distribution based on several optimization methods, Mathematics, 8 (2020), 1055. https://doi.org/10.3390/math8071055 doi: 10.3390/math8071055
|
| [13] |
D. F. Andrews, C. L. Mallows, Scale mixtures of normal distributions, J. Roy. Stat Soc.: Ser. B, 36 (1974), 99–102. https://doi.org/10.1111/j.2517-6161.1974.tb00989.x doi: 10.1111/j.2517-6161.1974.tb00989.x
|
| [14] |
W. H. Rogers, J. W. Tukey, Understanding some long-tailed symmetrical distributions, Stat. Neerl., 26 (1972), 211–226. https://doi.org/10.1111/j.1467-9574.1972.tb00191.x doi: 10.1111/j.1467-9574.1972.tb00191.x
|
| [15] | F. Mosteller, J. W. Tukey, Data analysis and regression, Reading: Addison-Wesley, 1977. |
| [16] |
K. Kafadar, A biweight approach to the one-sample problem, J. Am. Stat. Assoc., 77 (1982), 416–424. https://doi.org/10.1080/01621459.1982.10477827 doi: 10.1080/01621459.1982.10477827
|
| [17] |
H. W. Gómez, F. A. Quintana, F. J. Torres, A new family of slash-distributions with elliptical contours, Statist. Probab. Lett., 77 (2007), 717–725. https://doi.org/10.1016/j.spl.2006.11.006 doi: 10.1016/j.spl.2006.11.006
|
| [18] |
H. W. Gómez, O. Venegas, Erratum to: A new family of slash-distributions with elliptical contours [Statist. Probab. Lett. 77 (2007) 717–725], Statist. Probab. Lett., 78 (2008), 2273–2274. https://doi.org/10.1016/j.spl.2008.02.015 doi: 10.1016/j.spl.2008.02.015
|
| [19] |
H. W. Gómez, J. F. Olivares-Pacheco, H. Bolfarine, An extension of the generalized Birnbaum-Saunders distribution, Statist. Probab. Lett., 79 (2009), 331–338. https://doi.org/10.1016/j.spl.2008.08.014 doi: 10.1016/j.spl.2008.08.014
|
| [20] |
N. M. Olmos, H. Varela, H. Bolfarine, H. W. Gómez, An extension of the generalized half-normal distribution, Stat. Papers, 55 (2014), 967–981. https://doi.org/10.1007/s00362-013-0546-6 doi: 10.1007/s00362-013-0546-6
|
| [21] | M. Abramowitz, I. A. Stegun, Handbook of mathematical functions with formulas, graphs, and mathematical tables, 9 Eds., Dover Publications, 1965. |
| [22] |
L. J. Gleser, The Gamma distribution as a mixture of exponential distributions, Am. Stat., 43 (1989), 115–117. https://doi.org/10.2307/2684515 doi: 10.2307/2684515
|
| [23] |
N. M. Olmos, E. Gómez-Déniz, O. Venegas, The heavy-tailed Gleser model: properties, estimation, and applications, Mathematics, 10 (2022), 4577. https://doi.org/10.3390/math10234577 doi: 10.3390/math10234577
|
| [24] |
N. M. Olmos, E. Gómez-Déniz, O. Venegas, Scale mixture of Gleser distribution with an application to insurance data, Mathematics, 12 (2024), 1397. https://doi.org/10.3390/math12091397 doi: 10.3390/math12091397
|
| [25] | E. L. Lehman, Elements of large-sample theory, New York: Springer, 1999. https://doi.org/10.1007/b98855 |
| [26] | M. A. Tanner, Tools for statistical inference, 3 Eds., New York: Springer, 1996. https://doi.org/10.1007/978-1-4612-4024-2 |
| [27] |
R. E. Glaser, Bathtub and related failure rate characterizations, J. Am. Stat. Assoc., 75 (1980), 667–672. https://doi.org/10.1080/01621459.1980.10477530 doi: 10.1080/01621459.1980.10477530
|
| [28] | T. Rolski, H. Schmidli, V. Schmidt, J. Teugel, Stochastic processes for insurance and finance, Hoboken: John Wiley & Sons, 1999. https://doi.org/10.1002/9780470317044 |
| [29] | W. Feller, An introduction to probability theory and its applications, 2 Eds., Vol. 2, New York: John Wiley & Sons, 1968. |
| [30] | N. H. Bingham, C. M. Goldie, J. L. Teugels Regular variation, Cambridge: Cambridge University Press, 1987. https://doi.org/10.1017/CBO9780511721434 |
| [31] |
J. Beirlant, G. Matthys, G. Dierckx, Heavy-tailed distributions and rating, ASTIN Bull., 31 (2001), 37–58. https://doi.org/10.2143/AST.31.1.993 doi: 10.2143/AST.31.1.993
|
| [32] | D. G. Konstantinides, Risk theory: a heavy tail approach, World Scientific Publishing, 2017. |
| [33] | R Core Team, Gradient estimates for solutions of nonlinear elliptic and parabolic equations, R Foundation for Statistical Computing: Vienna, Austria, 2021. Available from: https://www.R-project.org/. |
| [34] |
H. Akaike, A new look at the statistical model identification, IEEE Trans. Automatic Control, 19 (1974), 716–723. https://doi.org/10.1109/TAC.1974.1100705 doi: 10.1109/TAC.1974.1100705
|
| [35] | G. Schwarz, Estimating the dimension of a model, Ann. Stat., 6 (1978), 461–464. |
| [36] |
H. Bozdogan, Model selection and Akaike's information criterion (AIC): the general theory and its analytical extensions, Psychometrika, 52 (1987), 345–370. https://doi.org/10.1007/BF02294361 doi: 10.1007/BF02294361
|
| [37] | E. J. Hannan, B. G. Quinn, The determination of the order of an autoregression., J. R. Stat. Soc.: Ser. B, 41 (1979), 190–195. |
| [38] |
E. Mahmoudi, The beta generalized Pareto distribution with application to lifetime data, Math. Comput. Simulat., 81 (2011), 2414–2430. https://doi.org/10.1016/j.matcom.2011.03.006 doi: 10.1016/j.matcom.2011.03.006
|

Figures(7) / Tables(8)

Neveka M. Olmos, Emilio Gómez-Déniz, Osvaldo Venegas. The Gauss hypergeometric Gleser distribution with applications to flood peaks exceedance and income data[J]. AIMS Mathematics, 2025, 10(6): 13575-13593. doi: 10.3934/math.2025611







 DownLoad:
DownLoad: