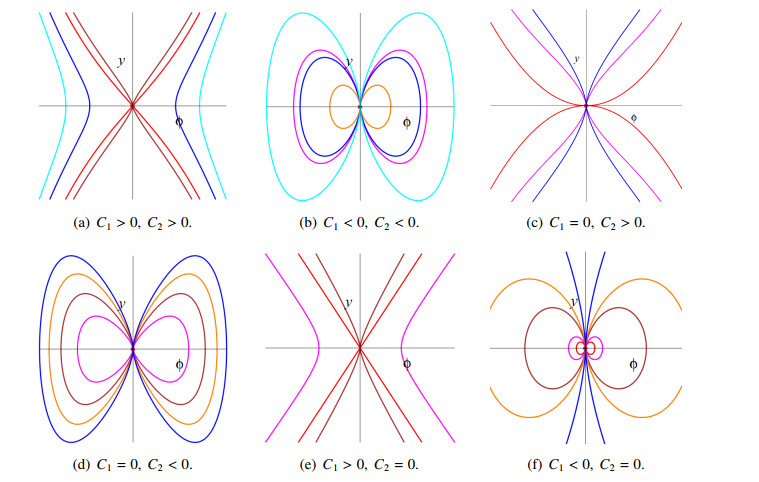
This study systematically investigates the dynamics of the perturbed Schrödinger-Hirota equation with cubic-quintic-septic nonlinearity under spatiotemporal dispersion, providing insights into soliton propagation in dispersive media. We begin by examining the system's phase portrait and chaotic behavior, followed by the derivation of exact traveling wave solutions, including optical solitons and periodic solutions, using an enhanced algebraic method. The findings are vividly illustrated through three-dimensional and two-dimensional graphical simulations, which analyze the impact of key parameters on the solutions. This study not only presents a variety of optical soliton solutions, but also clarifies the underlying dynamics, offering theoretical guidance for fiber optic communication systems and holding significant applied value for achieving more efficient and reliable optical communications.
Citation: Tianyong Han, Ying Liang, Wenjie Fan. Dynamics and soliton solutions of the perturbed Schrödinger-Hirota equation with cubic-quintic-septic nonlinearity in dispersive media[J]. AIMS Mathematics, 2025, 10(1): 754-776. doi: 10.3934/math.2025035
This study systematically investigates the dynamics of the perturbed Schrödinger-Hirota equation with cubic-quintic-septic nonlinearity under spatiotemporal dispersion, providing insights into soliton propagation in dispersive media. We begin by examining the system's phase portrait and chaotic behavior, followed by the derivation of exact traveling wave solutions, including optical solitons and periodic solutions, using an enhanced algebraic method. The findings are vividly illustrated through three-dimensional and two-dimensional graphical simulations, which analyze the impact of key parameters on the solutions. This study not only presents a variety of optical soliton solutions, but also clarifies the underlying dynamics, offering theoretical guidance for fiber optic communication systems and holding significant applied value for achieving more efficient and reliable optical communications.

| [1] |
A. Hasegawa, F. Tappert, Transmission of stationary nonlinear optical pulses in dispersive dielectric fibers. I. Anomalous dispersion, Appl. Phys. Lett., 23 (1973), 171. https://doi.org/10.1063/1.1654847 doi: 10.1063/1.1654847

|
| [2] |
T. Han, Z. Li, X. Zhang, Bifurcation and new exact traveling wave solutions to time-space coupled fractional nonlinear Schrödinger equation, Phys. Lett. A, 395 (2021), 127217. https://doi.org/10.1016/j.physleta.2021.127217 doi: 10.1016/j.physleta.2021.127217
|
| [3] |
L. Tang, Bifurcations and dispersive optical solitons for the nonlinear Schrödinger-Hirota equation in DWDM networks, Optik, 262 (2022), 169276. https://doi.org/10.1016/j.ijleo.2022.169276 doi: 10.1016/j.ijleo.2022.169276
|
| [4] |
K. Zhang, X. He, Z. Li, Bifurcation analysis and classification of all single traveling wave solution in fiber Bragg gratings with Radhakrishnan-Kundu-Lakshmanan equation, AIMS Math., 7 (2022), 16733–16740. https://doi.org/10.3934/math.2022918 doi: 10.3934/math.2022918
|
| [5] |
Z. Li, Qualitative analysis and explicit solutions of perturbed Chen-Lee-Liu equation with refractive index, Results Phys., 60 (2024), 107626. https://doi.org/10.1016/j.rinp.2024.107626 doi: 10.1016/j.rinp.2024.107626
|
| [6] |
C. A. Sarmasik, M. Ekici, Multi wave, kink, breather, Peregrine-like rational and interaction solutions for the concatenation model, Opt. Quant. Electron., 56 (2024), 256. https://doi.org/10.1007/s11082-023-05799-1 doi: 10.1007/s11082-023-05799-1
|
| [7] |
Z. Li, J. Liu, X. Xie, New single traveling wave solution in birefringent fibers or crossing sea waves on the high seas for the coupled Fokas-Lenells system, J. Ocean Eng. Sci., 8 (2023), 590–594. https://doi.org/10.1016/j.joes.2022.05.017 doi: 10.1016/j.joes.2022.05.017
|
| [8] |
L. Tang, Bifurcation analysis and multiple solitons in birefringent fibers with coupled Schrödinger-Hirota equation, Chaos Soliton. Fract., 161 (2022), 112383. https://doi.org/10.1016/j.chaos.2022.112383 doi: 10.1016/j.chaos.2022.112383
|
| [9] |
T. Han, H. Rezazadeh, U. R. Mati, High-order solitary waves, fission, hybrid waves and interaction solutions in the nonlinear dissipative (2+1)-dimensional Zabolotskaya-Khokhlov model, Phys. Scripta, 99 (2024), 115212. https://doi.org/10.1088/1402-4896/ad7f04 doi: 10.1088/1402-4896/ad7f04
|
| [10] |
Z. Li, E. Hussain, Qualitative analysis and optical solitons for the (1+1)-dimensional Biswas-Milovic equation with parabolic law and nonlocal nonlinearity, Results Phys., 56 (2024), 107304. https://doi.org/10.1016/j.rinp.2023.107304 doi: 10.1016/j.rinp.2023.107304
|
| [11] |
L. An, Y. Chen, L. Ling, Inverse scattering transforms for the nonlocal Hirota-Maxwell-Bloch system, J. Phys. A-Math. Theor., 56 (2023), 115201. https://doi.org/10.1088/1751-8121/acbb45 doi: 10.1088/1751-8121/acbb45
|
| [12] |
T. Han, Z. Li, K. Shi, G. C. Wu, Bifurcation and traveling wave solutions of stochastic Manakov model with multiplicative white noise in birefringent fibers, Chaos Soliton. Fract., 163 (2022), 112548. https://doi.org/10.1016/j.chaos.2022.112548 doi: 10.1016/j.chaos.2022.112548
|
| [13] |
M. Sadaf, S. Arshed, G. Akram, H. Shadab, A. S. M. Alzaidi, Traveling wave dynamics of the generalized Sasa-Satsuma equation by two integrating schemes, Opt. Quant. Electron., 56 (2024), 209. https://doi.org/10.1007/s11082-024-06900-y doi: 10.1007/s11082-024-06900-y
|
| [14] |
C. Peng, Z. Li, New traveling wave solutions and dynamic behavior analysis of the nonlinear Rangwala-Rao model, Results Phys., 54 (2023), 107096. https://doi.org/10.1016/j.rinp.2023.107096 doi: 10.1016/j.rinp.2023.107096
|
| [15] |
C. Liu, Z. Li, The dynamical behavior analysis of the fractional perturbed Gerdjikov-Ivanov equation, Results Phys., 59 (2024), 107537. https://doi.org/10.1016/j.rinp.2024.107537 doi: 10.1016/j.rinp.2024.107537
|
| [16] |
T. Han, L. Zhao, Bifurcation, sensitivity analysis and exact traveling wave solutions for the stochastic fractional Hirota-Maccari system, Results Phys., 47 (2023), 106349. https://doi.org/10.1016/j.rinp.2023.106349 doi: 10.1016/j.rinp.2023.106349
|
| [17] |
A. H. Arnous, A. Biswas, A. H. Kara, Y. Yildirim, L. Moraru, S. Moldovanu, Dispersive optical solitons and conservation laws of Radhakrishnan-Kundu-Lakshmanan equation with dual-power law nonlinearity, Heliyon, 9 (2023), e14036. https://doi.org/10.1016/j.heliyon.2023.e14036 doi: 10.1016/j.heliyon.2023.e14036
|
| [18] | Y. Yildirim, A. Biswas, S. Khan, M. Belic, Embedded solitons with $\chi^{(2)}$ and $\chi^{(3)}$ nonlinear susceptibilities, Semicond. Phys. Quant., 24 (2021), 160–165. |
| [19] |
J. Wang, Z. Li, A dynamical analysis and new traveling wave solution of the fractional coupled Konopelchenko-Dubrovsky model, Fractal Fract., 8 (2024), 341. https://doi.org/10.3390/fractalfract8060341 doi: 10.3390/fractalfract8060341
|
| [20] |
T. Han, K. Zhang, Y. Jiang, H. Rezazadeh, Chaotic pattern and solitary solutions for the (2+1)-dimensional Beta-fractional double-chain DNA system, Fractal Fract., 8 (2024), 415. https://doi.org/10.3390/fractalfract8070415 doi: 10.3390/fractalfract8070415
|
| [21] |
M. Ekici, A. Sonmezoglu, Optical solitons with Biswas-Arshed equation by extended trial function method, Optik, 177 (2019), 13–20. https://doi.org/10.1016/j.ijleo.2018.09.134 doi: 10.1016/j.ijleo.2018.09.134
|
| [22] |
S. Irshad, M. Shakeel, A. Bibi, M. Sajjad, K. S. Nisar, A comparative study of nonlinear fractional Schrödinger equation in optics, Mod. Phys. Lett. B, 37 (2023), 2250219. https://doi.org/10.1142/S0217984922502190 doi: 10.1142/S0217984922502190
|
| [23] |
T. Han, Y. Jiang, Bifurcation, chaotic pattern and traveling wave solutions for the fractional Bogoyavlenskii equation with multiplicative noise, Phys. Scripta, 99 (2024), 035207. https://doi.org/10.1088/1402-4896/ad21ca doi: 10.1088/1402-4896/ad21ca
|
| [24] | E. H. M. Abdullah, H. M. Ahmed, A. A. S. Zaghrout, A. I. A. Bahnasy, W. B. Rabie, Unveiling optical solitons in twin-core couplers with Kerr law of nonlinear refractive index using improved modified extended tanh function method, J. Optics, 2024. https://doi.org/10.1007/s12596-024-01971-2 |
| [25] |
W. B. Rabie, H. M. Ahmed, Diverse exact and solitary wave solutions to new extended KdV6 equation using IM extended tanh-function technique, Pramana-J. Phys., 98 (2024), 1–8. https://doi.org/10.1007/s12043-024-02767-6 doi: 10.1007/s12043-024-02767-6
|
| [26] |
M. S. Ghayad, N. M. Badra, H. M. Ahmed, W. B. Rabie, M. Mirzazadeh, M. S. Hashemi, Highly dispersive optical solitons in fiber Bragg gratings with cubic quadratic nonlinearity using improved modified extended tanh-function method, Opt. Quant. Electron., 56 (2024), 1184. https://doi.org/10.1007/s11082-024-07064-5 doi: 10.1007/s11082-024-07064-5
|
| [27] |
M. S. Ahmed, A. A. S. Zaghrout, H. M. Ahmed, I. Samir, Optical solitons for the stochastic perturbed Schrödinger-Hirota equation using two different methods, J. Opt., 53 (2024), 2631–2641. https://doi.org/10.1007/s12596-023-01403-7 doi: 10.1007/s12596-023-01403-7
|
| [28] |
O. El-Shamy, R. El-barkoki, H. M. Ahmed, W. Abbas, I. Samir, Extraction of solitons in multimode fiber for CHNLSEs using improved modified extended tanh function method, Alex. Eng. J., 106 (2024), 403–410. https://doi.org/10.1016/j.aej.2024.07.014 doi: 10.1016/j.aej.2024.07.014
|
| [29] |
A. Biswas, Stochastic perturbation of optical solitons in Schrödinger-Hirota equation, Opt. Commun., 239 (2004), 461–466. https://doi.org/10.1016/j.optcom.2004.06.047 doi: 10.1016/j.optcom.2004.06.047
|
| [30] |
Y. S. Ozkan, E. Yasar, A. R. Seadawy, On the multi-waves, interaction and Peregrine-like rational solutions of perturbed Radhakrishnan-Kundu-Lakshmanan equation, Phys. Scripta, 95 (2020), 085205. https://doi.org/10.1088/1402-4896/ab9af4 doi: 10.1088/1402-4896/ab9af4
|
| [31] |
X. Geng, Y. Lv, Darboux transformation for an integrable generalization of the nonlinear Schrödinger equation, Nonlinear Dyn., 69 (2012), 1621–1630. https://doi.org/10.1007/s11071-012-0373-7 doi: 10.1007/s11071-012-0373-7
|
| [32] |
S. Kumar, K. Singh, R. Gupta, Coupled Higgs field equation and Hamiltonian amplitude equation: Lie classical approach and ($G'$/$G$)-expansion method, Pramana, 79 (2012), 41–60. https://doi.org/10.1007/s12043-012-0284-7 doi: 10.1007/s12043-012-0284-7
|
| [33] |
W. J. Liu, L. H. Pang, P. Wong, M. Lei, Z. Y. Wei, Dynamic solitons for the perturbed derivative nonlinear Schrödinger equation in nonlinear optics, Laser Phys., 25 (2015), 065401. https://doi.org/10.1088/1054-660X/25/6/065401 doi: 10.1088/1054-660X/25/6/065401
|
| [34] |
M. Ekici, M. Mirzazadeh, A. Sonmezoglu, M. Z. Ullah, M. Asma, Q. Zhou, et al., Dispersive optical solitons with Schrödinger-Hirota equation by extended trial equation method, Optik, 136 (2017), 451–461. https://doi.org/10.1016/j.ijleo.2017.02.042 doi: 10.1016/j.ijleo.2017.02.042
|
| [35] | A. J. M. Jawad, S. Kumar, A. Biswas, Solition solutions of a few nonlinear wave equations in engineering sciences, Sci. Iran., 21 (2014), 861–869. |
| [36] | A. J. M. Jawad, A. Biswas, Y. Yildirim, A. A. Alghamdi, Dispersive optical solitons with Schrödinger-Hirota equation by a couple of integration schemes, J. Optoelectron. Adv. M., 25 (2023), 203–209. |
| [37] |
N. Ozdemir, A. Secer, M. Ozisik, M. Bayram, Perturbation of dispersive optical solitons with Schrödinger-Hirota equation with Kerr law and spatio-temporal dispersion, Optik, 265 (2022), 169545. https://doi.org/10.1016/j.ijleo.2022.169545 doi: 10.1016/j.ijleo.2022.169545
|
| [38] |
M. Inc, A. I. Aliyu, A. Yusuf, D. Baleanu, Dispersive optical solitons and modulation instability analysis of Schrödinger-Hirota equation with spatio-temporal dispersion and Kerr law nonlinearity, Superlattice, Superlattice. Microst., 113 (2018), 319–327. https://doi.org/10.1016/j.spmi.2017.11.010 doi: 10.1016/j.spmi.2017.11.010
|
| [39] |
C. Peng, L. Tang, Z. Li, D. Chen, Qualitative analysis of stochastic Schrödinger-Hirota equation in birefringent fibers with spatiotemporal dispersion and parabolic law nonlinearity, Results Phys., 51 (2023), 106729. https://doi.org/10.1016/j.rinp.2023.106729 doi: 10.1016/j.rinp.2023.106729
|
| [40] |
E. M. E. Zayed, R. M. A. Shohib, M. E. M. Alngar, Dispersive optical solitons in magneto-optic waveguides with stochastic generalized Schrödinger-Hirota equation having multiplicative white noise, Optik, 271 (2022), 170069. https://doi.org/10.1016/j.ijleo.2022.170069 doi: 10.1016/j.ijleo.2022.170069
|
| [41] |
N. Ozdemir, S. Altun, A. Secer, M. Ozisik, M. Bayram, Optical solitons for the dispersive Schrödinger-Hirota equation in the presence of spatio-temporal dispersion with parabolic law, Eur. Phys. J. Plus, 139 (2023), 551. https://doi.org/10.1140/epjp/s13360-023-04196-7 doi: 10.1140/epjp/s13360-023-04196-7
|
| [42] |
S. A. Durmus, N. Ozdemir, A. Secer, M. Ozisik, M. Bayram, Examination of optical soliton solutions for the perturbed Schrödinger-Hirota equation with anti-cubic law in the presence of spatiotemporal dispersion, Eur. Phys. J. Plus, 139 (2024), 464. https://doi.org/10.1140/epjp/s13360-024-05272-2 doi: 10.1140/epjp/s13360-024-05272-2
|
| [43] |
S. T. R. Rizvi, A. R. R. Seadawy, N. Farah, S. Ahmed, Transformation and interactions among solitons in metamaterials with quadratic-cubic nonlinearity and inter-model dispersion, Int. J. Mod. Phys. B, 37 (2023), 2350087. https://doi.org/10.1142/S021797922350087X doi: 10.1142/S021797922350087X
|
| [44] |
A. Yokus, H. M. Baskonus, Dynamics of traveling wave solutions arising in fiber optic communication of some nonlinear models, Soft Comput., 26 (2022), 13605–13614. https://doi.org/10.1007/s00500-022-07320-4 doi: 10.1007/s00500-022-07320-4
|
| [45] |
M. Inc, A. I. Aliyu, A. Yusuf, D. Baleanu, Optical and singular solitary waves to the PNLSE with third order dispersion in Kerr media via two integration approaches, Optik, 163 (2018), 142–151. https://doi.org/10.1016/j.ijleo.2018.02.084 doi: 10.1016/j.ijleo.2018.02.084
|
| [46] |
A. Houwe, S. Abbagari, G. Betchewe, M. Inc, S. Y. Doka, K. T. Crepin, et al., Exact optical solitons of the perturbed nonlinear Schrödinger-Hirota equation with Kerr law nonlinearity in nonlinear fiber optics, Open Phys., 18 (2020), 526–534. https://doi.org/10.1515/phys-2020-0177 doi: 10.1515/phys-2020-0177
|
| [47] |
Y. Akbar, H. Alotaibi, A novel approach to explore optical solitary wave solution of the improved perturbed nonlinear Schrödinger equation, Opt. Quant. Electron., 54 (2022), 534. https://doi.org/10.1007/s11082-022-03922-2 doi: 10.1007/s11082-022-03922-2
|
| [48] |
T. Han, Z. Li, C. Li, Bifurcation analysis, stationary optical solitons and exact solutions for generalized nonlinear Schrödinger equation with nonlinear chromatic dispersion and quintuple power-law of refractive index in optical fibers, Physica A, 615 (2023), 128599. https://doi.org/10.1016/j.physa.2023.128599 doi: 10.1016/j.physa.2023.128599
|
| [49] |
L. Tang, Optical solitons perturbation and traveling wave solutions in magneto-optic waveguides with the generalized stochastic Schrödinger-Hirota equation, Opt. Quant. Electron., 56 (2024), 773. https://doi.org/10.1007/s11082-024-06669-0 doi: 10.1007/s11082-024-06669-0
|
| [50] |
Y. Yildirim, Optical solitons to Schrödinger-Hirota equation in DWDM system with modified simple equation integration architecture, Optik, 182 (2019), 694–701. https://doi.org/10.1016/j.ijleo.2019.01.019 doi: 10.1016/j.ijleo.2019.01.019
|
| [51] |
S. Altun, A. Secer, M. Ozisik, M. Bayram, Optical soliton solutions of the perturbed fourth-order nonlinear Schrödinger- Hirota equation with parabolic law nonlinearity of self-phase modulation, Phys. Scripta, 99 (2024), 065244. https://doi.org/10.1088/1402-4896/ad4529 doi: 10.1088/1402-4896/ad4529
|
| [52] |
C. Liu, D. Shi, Z. Li, The traveling wave solution and dynamics analysis of the parabolic law nonlinear stochastic dispersive Schröinger-Hirota equation with multiplicative white noise, Results Phys., 54 (2023), 107025. https://doi.org/10.1016/j.rinp.2023.107025 doi: 10.1016/j.rinp.2023.107025
|
| [53] |
N. Ozdemir, S. Altun, A. Secer, M. Ozisik, M. Bayram, Bright soliton of the perturbed Schrödinger-Hirota equation with cubic-quintic-septic law of self-phase modulation in the presence of spatiotemporal dispersion, Eur. Phys. J. Plus, 139 (2024), 37. https://doi.org/10.1140/epjp/s13360-023-04837-x doi: 10.1140/epjp/s13360-023-04837-x
|









Figures(10)

Tianyong Han, Ying Liang, Wenjie Fan. Dynamics and soliton solutions of the perturbed Schrödinger-Hirota equation with cubic-quintic-septic nonlinearity in dispersive media[J]. AIMS Mathematics, 2025, 10(1): 754-776. doi: 10.3934/math.2025035







 DownLoad:
DownLoad: