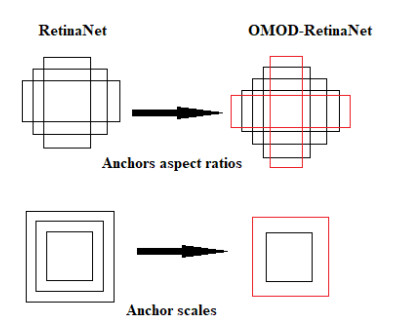
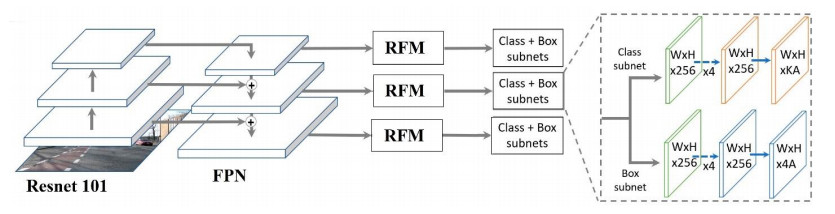
One essential component of the futuristic way of living in "smart cities" is the installation of surveillance cameras. There are a wide variety of applications for surveillance cameras, including but not limited to: investigating and preventing crimes, identifying sick individuals (coronavirus), locating missing persons, and many more. In this research, we provided a system for smart city outdoor item recognition using visual data collected by security cameras. The object identification model used by the proposed outdoor system was an enhanced version of RetinaNet. A state of the art object identification model, RetinaNet boasts lightning-fast processing and pinpoint accuracy. Its primary purpose was to rectify the focal loss-based training dataset's inherent class imbalance. To make the RetinaNet better at identifying tiny objects, we increased its receptive field with custom-made convolution blocks. In addition, we adjusted the number of anchors by decreasing their scale and increasing their ratio. Using a mix of open-source datasets including BDD100K, MS COCO, and Pascal Vocab, the suggested outdoor object identification system was trained and tested. While maintaining real-time operation, the suggested system's performance has been markedly enhanced in terms of accuracy.
Citation: Yahia Said, Amjad A. Alsuwaylimi. AI-based outdoor moving object detection for smart city surveillance[J]. AIMS Mathematics, 2024, 9(6): 16015-16030. doi: 10.3934/math.2024776
One essential component of the futuristic way of living in "smart cities" is the installation of surveillance cameras. There are a wide variety of applications for surveillance cameras, including but not limited to: investigating and preventing crimes, identifying sick individuals (coronavirus), locating missing persons, and many more. In this research, we provided a system for smart city outdoor item recognition using visual data collected by security cameras. The object identification model used by the proposed outdoor system was an enhanced version of RetinaNet. A state of the art object identification model, RetinaNet boasts lightning-fast processing and pinpoint accuracy. Its primary purpose was to rectify the focal loss-based training dataset's inherent class imbalance. To make the RetinaNet better at identifying tiny objects, we increased its receptive field with custom-made convolution blocks. In addition, we adjusted the number of anchors by decreasing their scale and increasing their ratio. Using a mix of open-source datasets including BDD100K, MS COCO, and Pascal Vocab, the suggested outdoor object identification system was trained and tested. While maintaining real-time operation, the suggested system's performance has been markedly enhanced in terms of accuracy.

| [1] |
X. Chen, X. Li, S. Yu, Y. Lei, N. Li, B. Yang, Dynamic vision enabled contactless cross-domain machine fault diagnosis with neuromorphic computing, IEEE/CAA J. Automat. Sinica, 11 (2024): 788–790. https://doi.org/10.1109/JAS.2023.124107 doi: 10.1109/JAS.2023.124107

|
| [2] |
X. Li, S. Yu, Y. Lei, N. Li, B. Yang, Intelligent machinery fault diagnosis with event-based camera, IEEE Trans. Ind. Inform., 20 (2023), 380–389. https://doi.org/10.1109/TII.2023.3262854 doi: 10.1109/TII.2023.3262854
|
| [3] |
R. Girshick, D. Jeff, D. Trevor, M. Jitendra, Region-based convolutional networks for accurate object detection and segmentation, IEEE Trans. Pattern Anal. Mach. Intell., 38 (2015), 142–158. https://doi.org/10.1109/TPAMI.2015.2437384 doi: 10.1109/TPAMI.2015.2437384
|
| [4] | R. Girshick, Fast R-CNN, In: 2015 IEEE International conference on computer vision (ICCV), IEEE, 2015, 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [5] |
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, IEEE Trans. Pattern Anal. Mach. Intell., 39 (2017), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 doi: 10.1109/TPAMI.2016.2577031
|
| [6] | J. Dai, Y. Li, K. He, J. Sun, R-FCN: Object detection via region-based fully convolutional networks, In: Proceedings of the 30th international conference on neural information processing systems, 2016,379–387. |
| [7] | K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask R-CNN, In: 2017 IEEE International conference on computer vision (ICCV), 2017, 2961–2969. https://doi.org/10.1109/ICCV.2017.322 |
| [8] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, arXiv: 1506.02640, 2015. https://doi.org/10.48550/arXiv.1506.02640 |
| [9] | J. Redmon, A. Farhadi, YOLO9000: better, faster, stronger, In: 2017 IEEE Conference on computer vision and pattern recognition (CVPR), 2017, 6517–6525. https://doi.org/10.1109/CVPR.2017.690 |
| [10] | J. Redmon, Ali Farhadi, Yolov3: An incremental improvement, arXiv: 1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767 |
| [11] | A. Bochkovskiy, C. Wang, H. M. Liao, YOLOv4: Optimal speed and accuracy of object detection, arXiv: 2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934 |
| [12] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, et al., SSD: Single shot multibox detector, In: Computer vision-ECCV 2016, Springer, 9905 (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [13] | T. -Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, In: 2017 IEEE International conference on computer vision (ICCV), 2017, 2999–3007. https://doi.org/10.1109/ICCV.2017.324 |
| [14] |
M. Afif, R. Ayachi, Y. Said, E. Pissaloux, M. Atri, An evaluation of RetinaNet on indoor object detection for blind and visually impaired persons assistance navigation, Neural Process Lett., 51 (2020), 2265–2279. https://doi.org/10.1007/s11063-020-10197-9 doi: 10.1007/s11063-020-10197-9
|
| [15] |
R. Ayachi, M. Afif, Y. Said, M. Atri, Traffic signs detection for real-world application of an advanced driving assisting system using deep learning, Neural Process Lett., 51 (2020), 837–851. https://doi.org/10.1007/s11063-019-10115-8 doi: 10.1007/s11063-019-10115-8
|
| [16] | T. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, et al., Microsoft coco: Common objects in context, In: Computer vision-ECCV 2014, Springer, 8693 (2014), 740–755. https://doi.org/10.1007/978-3-319-10602-1_48 |
| [17] |
M. Everingham, L. V. Gool, C. K. I. Williams, J. Winn, A. Zisserman, The PASCAL visual object classes (voc) challenge, Int. J. Comput. Vis., 88 (2010), 303–338. https://doi.org/10.1007/s11263-009-0275-4 doi: 10.1007/s11263-009-0275-4
|
| [18] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, In: 2016 IEEE Conference on computer vision and pattern rRecognition (CVPR), 2016,770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [19] | F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, et al., BDD100K: A diverse driving dataset for heterogeneous multitask learning, In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), 2020, 2633–2642. https://doi.org/10.1109/CVPR42600.2020.00271 |
| [20] | C. Ning, H. Zhou, Y. Song, J. Tang, Inception single shot multibox detector for object detection, In: 2017 IEEE International conference on multimedia & expo workshops (ICMEW), 2017,549–554. https://doi.org/10.1109/ICMEW.2017.8026312 |
| [21] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), 2016, 2818–2826. https://doi.org/10.1109/CVPR.2016.308 |
| [22] | X. Wang, H. -M. Hu, Y. Zhang, Pedestrian detection based on spatial attention module for outdoor video surveillance, In: 2019 IEEE Fifth international conference on multimedia big data (BigMM), 2019,247–251. https://doi.org/10.1109/BigMM.2019.00-17 |
| [23] | Z. Zhang, J. Wu, X. Zhang, C. Zhang, Multi-target, multi-camera tracking by hierarchical clustering: Recent progress on dukemtmc project, arXiv: 1712.0953, 2017. https://doi.org/10.48550/arXiv.1712.09531 |
| [24] | X. Wang, Dml dataset. Available from: https://dml-file.dong-liu.com |
| [25] | M. Schembri, D. Seychell, Small object detection in highly variable backgrounds, In: 2019 11th International symposium on image and snal pocessing and aalysis (ISPA), 2019, 32–37. https://doi.org/10.1109/ISPA.2019.8868719 |
| [26] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv: 1409.1556, 2014. https://doi.org/10.48550/arXiv.1409.1556 |
| [27] | Dataset of images of trash, 2017. Available from: https://github.com/garythung/trashnet |
| [28] |
W. Wu, J. Lai. Multi camera localization handover based on YOLO object detection algorithm in complex environments, IEEE Access, 12 (2024), 15236–15250. https://doi.org/10.1109/ACCESS.2024.3357519 doi: 10.1109/ACCESS.2024.3357519
|
| [29] |
A. Yadav, P. K. Chaturvedi, S. Rani, Object detection and tracking using YOLOv8 and DeepSORT, Adv. Communi. Syst., 2024, 81–90. https://doi.org/10.56155/978-81-955020-7-3-7 doi: 10.56155/978-81-955020-7-3-7
|
| [30] |
L. C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, A. L. Yuille, Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs, IEEE Trans. Pattern Anal. Mach. Intell., 40 (2017), 834–848. https://doi.org/10.1109/TPAMI.2017.2699184 doi: 10.1109/TPAMI.2017.2699184
|

Figures(5) / Tables(4)

Yahia Said, Amjad A. Alsuwaylimi. AI-based outdoor moving object detection for smart city surveillance[J]. AIMS Mathematics, 2024, 9(6): 16015-16030. doi: 10.3934/math.2024776







 DownLoad:
DownLoad: