Several random phenomena have been modeled by using extreme value distributions. Based on progressive type-Ⅱ censored data with three different distributions (i.e., fixed, discrete uniform, and binomial random removal), the statistical inference of the generalized extreme value distribution under liner normalization (GEVL distribution) parameters is investigated in this study. Since there is no analytical solution, determining the maximum likelihood parameters for the GEVL distribution is considered to be a problem. Standard numerical methods are frequently insufficient for this dilemma, requiring the use of artificial intelligence algorithms to address this difficulty. Here, nonlinear minimization and a genetic algorithm have been used to tackle that problem. In addition, Lindley approximation and Monte Carlo estimation were implemented via Metropolis-Hastings algorithms to carry out the Bayesian point estimation based on both the squared error loss function and LINEX loss functions. Moreover, the highest posterior density intervals were applied. The proposed theoretical inference techniques have been applied in a numerical simulation and a real-life example.
Citation: Rasha Abd El-Wahab Attwa, Shimaa Wasfy Sadk, Hassan M. Aljohani. Investigation the generalized extreme value under liner distribution parameters for progressive type-Ⅱ censoring by using optimization algorithms[J]. AIMS Mathematics, 2024, 9(6): 15276-15302. doi: 10.3934/math.2024742
Several random phenomena have been modeled by using extreme value distributions. Based on progressive type-Ⅱ censored data with three different distributions (i.e., fixed, discrete uniform, and binomial random removal), the statistical inference of the generalized extreme value distribution under liner normalization (GEVL distribution) parameters is investigated in this study. Since there is no analytical solution, determining the maximum likelihood parameters for the GEVL distribution is considered to be a problem. Standard numerical methods are frequently insufficient for this dilemma, requiring the use of artificial intelligence algorithms to address this difficulty. Here, nonlinear minimization and a genetic algorithm have been used to tackle that problem. In addition, Lindley approximation and Monte Carlo estimation were implemented via Metropolis-Hastings algorithms to carry out the Bayesian point estimation based on both the squared error loss function and LINEX loss functions. Moreover, the highest posterior density intervals were applied. The proposed theoretical inference techniques have been applied in a numerical simulation and a real-life example.

| [1] |
M. Gilli, E. këllezi, An application of extreme value theory for measuring financial risk, Comput. Econ., 27 (2006), 207–228. https://doi.org/10.1007/s10614-006-9025-7 doi: 10.1007/s10614-006-9025-7

|
| [2] |
R. A. Fisher, L. H. C. Tippett, Limiting forms of the frequency distribution of the largest or smallest member of a sample, Math. Proc. Cambridge, 24 (1928), 180–190. https://doi.org/10.1017/S0305004100015681 doi: 10.1017/S0305004100015681
|
| [3] |
T. G. Bali, The generalized extreme value distribution, Econ. Lett., 79 (2003), 423–427. https://doi.org/10.1016/S0165-1765(03)00035-1 doi: 10.1016/S0165-1765(03)00035-1
|
| [4] |
J. Hosking, J. Wallis, E. Wood, Estimation of the generalized extreme-value distribution by the method of probability-weighted moments, Technometrics, 27 (1985), 251–261. https://doi.org/10.2307/1269706 doi: 10.2307/1269706
|
| [5] |
E. Bertin, M. Clusel, Generalized extreme value statistics and sum of correlated variables, J. Phys. A Math. Gen., 39 (2006), 7607. https://doi.org/10.1088/0305-4470/39/24/001 doi: 10.1088/0305-4470/39/24/001
|
| [6] |
S. Zhou, A. Xu, Y. Tang, L. Shen, Fast Bayesian inference of reparameterized gamma process with random effects, IEEE T. Reliab., 73 (2024), 399–412. https://doi.org/10.1109/TR.2023.3263940 doi: 10.1109/TR.2023.3263940
|
| [7] |
L. Zhuang, A. Xu, X. Wang, A prognostic driven predictive maintenance framework based on Bayesian deep learning, Reliab. Eng. Syst. Safe., 234 (2023), 109181. https://doi.org/10.1016/j.ress.2023.109181 doi: 10.1016/j.ress.2023.109181
|
| [8] | W. Wang, Z. Cui, R. Chen, Y. Wang, X. Zhao, Regression analysis of clustered panel count data with additive mean models, Stat. Papers, 2023. https: /doi.org/10.1007/s00362-023-01511-3 |
| [9] |
S. Phoong, M. Ismail, A comparison between Bayesian and maximum likelihood estimations in estimating finite mixture model for financial data, Sains Malays., 44 (2015), 1033–1039. https://doi.org/10.17576/jsm-2015-4407-16 doi: 10.17576/jsm-2015-4407-16
|
| [10] |
S. Wang, W. Chen, M. Chen, Y. Zhou, Maximum likelihood estimation of the parameters of the inverse Gaussian distribution using maximum rank set sampling with unequal samples, Math. Popul. Stud., 30 (2023), 1–21. https://doi.org/10.1080/08898480.2021.1996822 doi: 10.1080/08898480.2021.1996822
|
| [11] | S. Coles, J. Bawa, L. Trenner, P. Dorazio, An introduction to statistical modeling of extreme values, London: Springer, 2001. |
| [12] | H. Barakat, O. Khaled, E. Nigm, Statistical techniques for modeling extreme value data and related applications, Cambridge Scholars Publishing, 2019. |
| [13] | J. Dennis Jr, R. Schnabel, Numerical methods for unconstrained optimization and nonlinear equations, Society for Industrial and Applied Mathematics, 1996. |
| [14] | L. Haldurai, T. Madhubala, R. Rajalakshmi, A study on Genetic algorithm and its applications, Int. J. Comput. Sci. Eng., 4 (2016), 2347–2693. |
| [15] |
L. Scrucca, GA: A package for genetic algorithm in R, J. Stat. Softw., 53 (2013), 1–37. https://doi.org/10.18637/jss.v053.i04 doi: 10.18637/jss.v053.i04
|
| [16] | N. Balakrishnan, R. Aggarwala, Progressive censoring: theory, methods, and applications, Springer Science & Business Media, 2000. https://doi.org/10.1007/978-1-4612-1334-5 |
| [17] | nlm: Non-linear minimization, stats (version 3.6.2), 2019. Available from: https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/nlm. |
| [18] | J. F. Lawless, Statistical models and methods for lifetime data, John Wiley & Sons, 2003. https://doi.org/10.1002/9781118033005 |
| [19] |
N. A. Mokhlis, E. J. Ibrahim, D. M. Gharieb, Stress-strength reliability with general form distributions, Commun. Stati. Theor. M., 46 (2017), 1230–1246. https://doi.org/10.1080/03610926.2015.1014110 doi: 10.1080/03610926.2015.1014110
|
| [20] |
N. A. Mokhlis, S. K. Khames, Estimation of stress-strength reliability for Marshall-Olkin extended Weibull family based on type-Ⅱ progressive censoring, J. Stat. Appl. Probab., 10 (2021), 385–396. https://doi.org/10.18576/jsap/100210 doi: 10.18576/jsap/100210
|
| [21] |
S. Ahn, C. Park, H. Kim, Hazard rate estimation of a mixture model with censored lifetimes, Stoch. Environ. Rese. Risk Assess., 21 (2007), 711–716. https://doi.org/10.1007/s00477-006-0082-1 doi: 10.1007/s00477-006-0082-1
|
| [22] |
N. Khatun, M. Matin, A study on LINEX loss function with different estimating methods, Open J. Stat., 10 (2020), 52–63. https://doi.org/10.4236/ojs.2020.101004 doi: 10.4236/ojs.2020.101004
|
| [23] |
D. V. Lindley, Approximate Bayesian methods, Trabajos de Estadistica Y de Investigacion Operativa, 31 (1980), 223–245. https://doi.org/10.1007/BF02888353 doi: 10.1007/BF02888353
|
| [24] |
C. Wang, M. H. Chen, E. Schifano, J. Wu, J. Yan, Statistical methods and computing for big data, Stat. interface, 9 (2016), 399–414. https://doi.org/10.4310/SII.2016.v9.n4.a1 doi: 10.4310/SII.2016.v9.n4.a1
|
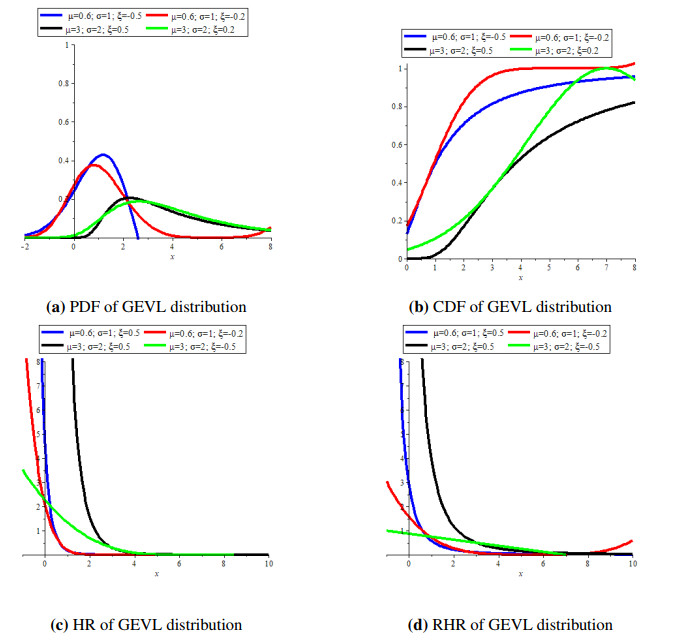
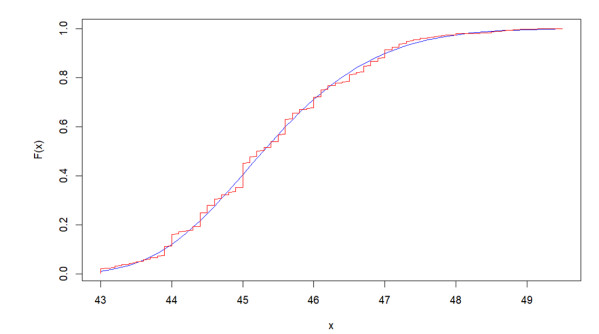
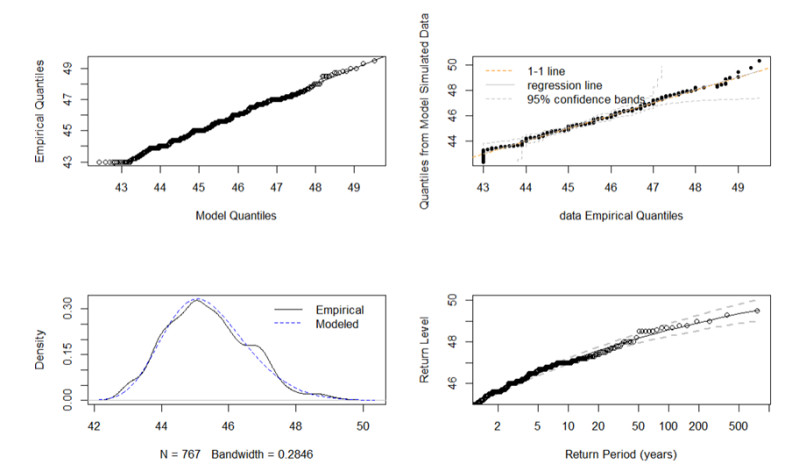
Figures(3) / Tables(8)

Rasha Abd El-Wahab Attwa, Shimaa Wasfy Sadk, Hassan M. Aljohani. Investigation the generalized extreme value under liner distribution parameters for progressive type-Ⅱ censoring by using optimization algorithms[J]. AIMS Mathematics, 2024, 9(6): 15276-15302. doi: 10.3934/math.2024742







 DownLoad:
DownLoad: