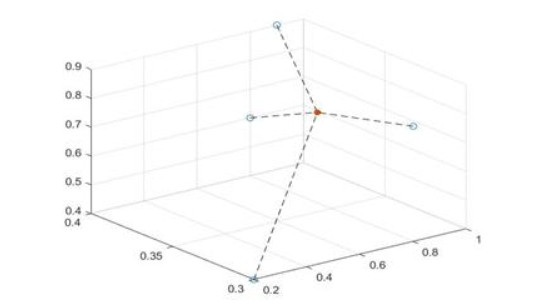
The social division of labor has become increasingly specialized, and there are more and more group decision-making problems participated by multiple decision-makers. With respect to the multi-attribute group decision making problem, including two-tuple linguistic information, based on the theory and method of group decision making, Steiner point constraint and plant growth simulation algorithm, we establish a novel multi-attribute group decision making approach based on two-tuple linguistic information aggregation. We introduce Steiner points into group consensus decision making and use the PGSA algorithm to seek the global optimal point. The method seeks set points that are both mathematically and geometrically meaningful to reduce set bias. In this paper, to begin with, according to the constraints of multi-dimensional Steiner point, we map the evaluation vectors of the group experts over the alternatives into multi-dimensional space and then we propose a two-tuple linguistic information aggregation model. Moreover, we construct a comprehensive evaluation decision making approach and then design a plant growth simulation algorithm to select the optimal alternative. Finally, a case verifies the validity and rationality of the proposed model.
Citation: Zu-meng Qiu, Huan-huan Zhao, Jun Yang. A group decision making approach based on the multi-dimensional Steiner point[J]. AIMS Mathematics, 2024, 9(1): 942-958. doi: 10.3934/math.2024047
The social division of labor has become increasingly specialized, and there are more and more group decision-making problems participated by multiple decision-makers. With respect to the multi-attribute group decision making problem, including two-tuple linguistic information, based on the theory and method of group decision making, Steiner point constraint and plant growth simulation algorithm, we establish a novel multi-attribute group decision making approach based on two-tuple linguistic information aggregation. We introduce Steiner points into group consensus decision making and use the PGSA algorithm to seek the global optimal point. The method seeks set points that are both mathematically and geometrically meaningful to reduce set bias. In this paper, to begin with, according to the constraints of multi-dimensional Steiner point, we map the evaluation vectors of the group experts over the alternatives into multi-dimensional space and then we propose a two-tuple linguistic information aggregation model. Moreover, we construct a comprehensive evaluation decision making approach and then design a plant growth simulation algorithm to select the optimal alternative. Finally, a case verifies the validity and rationality of the proposed model.

| [1] |
J. C. Jiang, X. D. Liu, G. Harish, S. T. Zhang, Large group decision-making based on interval rough integrated cloud model, Adv. Eng. Inform., 56 (2023), 101964. https://doi.org/10.1016/j.aei.2023.101964 doi: 10.1016/j.aei.2023.101964

|
| [2] |
J. C. Jiang, X. D. Liu, Z. W. Wang, W. P. Ding, S. T. Zhang, Large group emergency decision-making with bi-directional trust in social networks: A probabilistic hesitant fuzzy integrated cloud approach, Inform. Fusion, 102 (2024), 102062. https://doi.org/10.1016/j.inffus.2023.102062 doi: 10.1016/j.inffus.2023.102062
|
| [3] |
E. Herrera-Viedma, L. Martinez, F. Mata, F. Chiclana, A consensus support system model for group decision-making problems with multi-granular linguistic preference relations, IEEE T. Fuzzy Syst., 13 (2005), 644–658. https://doi.org/10.1109/TFUZZ.2005.856561 doi: 10.1109/TFUZZ.2005.856561
|
| [4] |
Y. P. Jiang, Z. P. Fan, J. Ma, A method for group decision making with multi-granularity linguistic assessment information, Inf. Sci., 178 (2008), 1098–1109. https://doi.org/10.1016/j.ins.2007.09.007 doi: 10.1016/j.ins.2007.09.007
|
| [5] |
F. Herrera, L. Martinez, A model based on linguistic 2-tuples for dealing with multigranularity hierarchical linguistic contexts in multi-expert decision making, IEEE T. Syst. Man Cy. B, 31 (2001), 227–234. https://doi.org/10.1109/3477.915345 doi: 10.1109/3477.915345
|
| [6] |
Z. S. Xu, J. Chen, An interactive method for fuzzy multiple attribute group decision making, Inf. Sci., 177 (2007), 248–263. https://doi.org/10.1016/j.ins.2006.03.001 doi: 10.1016/j.ins.2006.03.001
|
| [7] |
F. Herrera, L. Martinez, A 2-tuple fuzzy linguistic representation model for computing with words, IEEE T. Fuzzy Syst., 8 (2000), 746–752. https://doi.org/10.1109/91.890332 doi: 10.1109/91.890332
|
| [8] |
Y. P. Jiang, Z. P. Fan, Property analysis of aggregation operators for two-tuple linguistic information, Control Decis., 2003,754–757. https://doi.org/10.13195/j.cd.2003.06.116.jiangyp.028 doi: 10.13195/j.cd.2003.06.116.jiangyp.028
|
| [9] |
F. Herrera, E. Herrera-Viedma, Aggregation operators for linguistic weighted information, IEEE T. Syst. Man Cy., 27 (1997), 646–656. https://doi.org/10.1109/3468.618263 doi: 10.1109/3468.618263
|
| [10] | Z. S. Xu, A priority method based on induced ordered weighted averaging (IOWA) operator for fuzzy linguistic preference matrices, Syst. Eng. Electron. Techn., 25 (2003), 440–442. |
| [11] | Z. S. Xu, Method based on fuzzy linguistic assessments and GIOWA operator in multi-attribute group decision-making, Syst. Sci. Math., 24 (2004), 218–224. |
| [12] | Z. S. Xu, A method based on fuzzy linguistic assessments and linguistic ordered weighted averaging (OWA) operator for multi-attribute group decision-making problems, Systems Eng., 20 (2002), 79–82. |
| [13] | G. W. Wei, Study on methods for fuzzy multiple attribute decision making under some situations, Southwest Jiaotong Univ., 2009. |
| [14] |
S. Faizi, W. Salabun, N. Shaheen, A. U. Rehman, J. Watróbski, A novel multi-criteria group decision-making approach based on Bonferroni and Heronian mean operators under hesitant 2-tuple linguistic environment, Mathematics, 9 (2021), 1489. https://doi.org/10.3390/math9131489 doi: 10.3390/math9131489
|
| [15] |
M. Akram, U. Noreen, M. M. A. A1-Shamiri, D. Pamucar, Integrated decision-making methods based on 2-tuple linguistic m-polar fuzzy information, AIMS Math., 7 (2022), 14557–14594. https://doi.org/10.3934/math.2022802 doi: 10.3934/math.2022802
|
| [16] |
M. Akram, M. Sultan, A. Adeel, M. M. A. Al-Shamiri, Pythagorean fuzzy N-Soft PROMETHEE approach: A new framework for group decision making, AIMS Math., 8 (2023), 17354–17380. https://doi.org/10.3934/math.2023887 doi: 10.3934/math.2023887
|
| [17] |
W. He, R. M. Rodríguez, B. Dutta, L. Martinez, A type-1 OWA operator for extended comparative linguistic expressions with symbolic translation, Fuzzy Set. Syst., 446 (2022), 167–192. https://doi.org/10.1016/j.fss.2021.08.002 doi: 10.1016/j.fss.2021.08.002
|
| [18] |
M. Akram, S. Naz, T. Abbas, Complex q-rung orthopair fuzzy 2-tuple linguistic group decision-making framework with Muirhead mean operators, Artif. Intell. Rev., 56 (2023), 10227–10274. https://doi.org/10.1007/s10462-023-10408-4 doi: 10.1007/s10462-023-10408-4
|
| [19] |
M. Akram, S. Naz, G. Santos-Garcia, M. R. Saeed, Extended CODAS method for MAGDM with 2-tuple linguistic T-spherical fuzzy sets, AIMS Math., 8 (2023), 3428–3468. https://doi.org/10.3934/math.2023176 doi: 10.3934/math.2023176
|
| [20] |
M. Akram, S. Naz, F. Feng, G. Ali, A. Shafiq, Extended MABAC method based on 2-tuple linguistic T-spherical fuzzy sets and Heronian mean operators: An application to alternative fuel selection, AIMS Math., 8 (2023), 10619–10653. https://doi.org/10.3934/math.2023539 doi: 10.3934/math.2023539
|
| [21] |
F. Herrera, L. Martínez, The 2-tuple linguistic computational model. advantages of its linguistic description, accuracy and consistency, Int. J. Uncertain. Fuzz., 9 (2001), 33–48. https://doi.org/10.1142/S0218488501000971 doi: 10.1142/S0218488501000971
|
| [22] | Y. P. Jiang, Z. P. Fan, Approach to group decision making with multi-granularity linguistic comparison matrices, J. Syst. Eng., 21 (2006), 249–253. |
| [23] |
X. D. Liu, X. D. Liu, S. T. Zhang, G. Harish, An approach to probabilistic hesitant fuzzy risky multi-attribute decision making with unknown probability information, Int. J. Intell. Syst., 36 (2021), 5714–5740. https://doi.org/10.1002/int.22527 doi: 10.1002/int.22527
|
| [24] |
Z. L. Wang, Y. M. Wang, A method for multiple attribute group decision making with complete unknown weight information based on 2-dimension 2-tuple linguistic information, Control Decis., 34 (2019), 1999–2009. https://doi.org/10.13195/j.kzyjc.2018.0115 doi: 10.13195/j.kzyjc.2018.0115
|
| [25] |
W. F. Dai, C. Z. Qi, Multi-attribute group decision making method based on interval 2-tuple linguistic VIKOR, Stat. Decis. Ma., 34 (2018), 41–45. https://doi.org/10.13546/j.cnki.tjyjc.2018.09.009 doi: 10.13546/j.cnki.tjyjc.2018.09.009
|
| [26] |
S. Zhang, Method for multiple attribute group decision making based on relational analysis of two-tuple linguistic representation, Stat. Decis. Ma., 2017, 62–65. https://doi.org/10.13546/j.cnki.tjyjc.2017.11.016 doi: 10.13546/j.cnki.tjyjc.2017.11.016
|
| [27] |
S. N. Ge, C. P. Wei, Hesitant fuzzy language decision making method based on 2-tuple, Oper. Res. Manage., 26 (2017), 108–114. https://doi.org/10.12005/orms.2017.0064 doi: 10.12005/orms.2017.0064
|
| [28] |
J. Wu, J. Chang, Q. W. Cao, C. Y. Liang, A trust propagation and collaborative filtering-based method for incomplete information in social network group decision making with type-2 linguistic trust, Comput. Ind. Eng., 127 (2019), 853–864. https://doi.org/10.1016/j.cie.2018.11.020 doi: 10.1016/j.cie.2018.11.020
|
| [29] |
J. Wu, F. Chiclana, H. Fujita, E. Herrera-Viedma, A visual interaction consensus model for social network group decision making with trust propagation, Knowl.-Based Syst., 122 (2017), 39–50. https://doi.org/10.1016/j.knosys.2017.01.031 doi: 10.1016/j.knosys.2017.01.031
|
| [30] |
Y. Z. Wu, Y. C. Dong, J. D. Qin, W. Pedrycz, Flexible linguistic expressions and consensus reaching with accurate constraints in group decision-making, IEEE T. Cybernetics, 50 (2020), 2488–2501. https://doi.org/10.1109/TCYB.2019.2906318 doi: 10.1109/TCYB.2019.2906318
|
| [31] |
B. W. Zhang, Y. C. Dong, Consensus rules with minimum adjustments for multiple attribute group decision making, Procedia Comput. Sci., 17 (2013), 473–481. https://doi.org/10.1016/j.procs.2013.05.061 doi: 10.1016/j.procs.2013.05.061
|
| [32] |
Q. B. Zha, Y. C. Dong, H. J. Zhang, F. Chiclana, E. Herrera-Viedma, A personalized feedback mechanism based on bounded confidence learning to support consensus reaching in group decision making, IEEE T. Cybernetics, 51 (2019), 3900–3910. https://doi.org/10.1109/TSMC.2019.2945922 doi: 10.1109/TSMC.2019.2945922
|
| [33] |
Q. W. Cao, L. F. Dai, Q. Sun, J. Wu, A distributed trust based online evaluation under social network, Control Decis., 35 (2020), 1697–1702. https://doi.org/10.13195/j.kzyjc.2018.1527 doi: 10.13195/j.kzyjc.2018.1527
|
| [34] |
Y. J. Liu, C. Y. Liang, F. Chiclana, J. Wu, A trust induced recommendation mechanism for reaching consensus in group decision making, Knowl.-Based Syst., 119 (2017), 221–231. https://doi.org/10.1016/j.knosys.2016.12.014 doi: 10.1016/j.knosys.2016.12.014
|
| [35] |
J. Wu, S. Wang, F. Chiclana, E. Herrera-Viedma, Two-fold personalized feedback mechanism for social network consensus by uninorm interval trust propagation, IEEE T. Cybernetics, 52 (2021), 11081–11092. https://doi.org/10.1109/TCYB.2021.3076420 doi: 10.1109/TCYB.2021.3076420
|
| [36] |
Z. W. Gong, H. Wang, W. W. Guo, Z. J. Gong, G. Wei, Measuring trust in social networks based on linear uncertainty theory, Inf. Sci., 508 (2020), 154–172. https://doi.org/10.1016/j.ins.2019.08.055 doi: 10.1016/j.ins.2019.08.055
|
| [37] |
P. Wu, Q. Wu, L. G. Zhou, H. Y. Chen, Optimal group selection model for large-scale group decision making, Inform. Fusion, 61 (2020), 1–12. https://doi.org/10.1016/j.inffus.2020.03.002 doi: 10.1016/j.inffus.2020.03.002
|
| [38] |
J. F. Chu, X. W. Liu, Y. M. Wang, Social network analysis-based approach to group decision making problem with fuzzy preference relations, J. Intell. Fuzzy Syst., 31 (2016), 1271–1285. https://doi.org/10.3233/ifs-162193 doi: 10.3233/ifs-162193
|
| [39] |
Y. L. Lu, Y. J. Xu, E. Herrera-Viedma, Y. F. Han, Consensus of large-scale group decision making in social network: the minimum cost model based on robust optimization, Inf. Sci., 547 (2021), 910–930. https://doi.org/10.1016/j.ins.2020.08.022 doi: 10.1016/j.ins.2020.08.022
|
| [40] |
J. Wu, L. F. Dai, F. Chiclana, H. Fujita, E. Herrera-Viedma, A minimum adjustment cost feedback mechanism-based consensus model for group decision making under social network with distributed linguistic trust, Inform. Fusion, 41 (2018), 232–242. https://doi.org/10.1016/j.inffus.2017.09.012 doi: 10.1016/j.inffus.2017.09.012
|
| [41] |
T. Wu, X. W. Liu, Z. W. Gong, H. H. Zhang, F. Herrera, The minimum cost consensus model considering the implicit trust of opinions similarities in social network group decision-making, Int. J. Intell. Syst., 35 (2020), 470–493. https://doi.org/10.1002/int.22214 doi: 10.1002/int.22214
|
| [42] |
X. H. Xu, B. Wang, Y. J. Zhou, A method based on trust model for large group decision-making with incomplete preference information, J. Intell. Fuzzy Syst., 30 (2016), 3551–3565. https://doi.org/10.3233/IFS-162100 doi: 10.3233/IFS-162100
|
| [43] |
J. Wu, J. Chen, W. Liu, Y. J. Liu, C. Y. Liang, M. S. Cao, A calibrated individual semantic based failure mode and effect analysis and its application in industrial internet platform, Mathematics, 10 (2022), 2492. https://doi.org/10.3390/math10142492 doi: 10.3390/math10142492
|
| [44] |
X. L. Tian, Z. S. Xu, J. Gu, F. Herrera, A consensus process based on regret theory with probabilistic linguistic term sets and its application in venture capital, Inf. Sci., 562 (2021), 347–369. https://doi.org/10.1016/j.ins.2021.02.003 doi: 10.1016/j.ins.2021.02.003
|
| [45] |
D. C. Liang, Y. Y. Fu, Z. S. Xu, Three-way group consensus decision based on hierarchical social network consisting of decision makers and participants, Inf. Sci., 585 (2022), 289–312. https://doi.org/10.1016/j.ins.2021.11.057 doi: 10.1016/j.ins.2021.11.057
|
| [46] |
X. L. You, F. J. Hou, A self-confidence and leadership-based feedback mechanism for consensus of group decision making with probabilistic linguistic preference relation, Inf. Sci., 582 (2022), 547–572. https://doi.org/10.1016/j.ins.2021.09.044 doi: 10.1016/j.ins.2021.09.044
|
| [47] |
Z. M. Zhang, S. M. Chen, Group decision making based on multiplicative consistency and consensus of Pythagorean fuzzy preference relations, Inf. Sci., 601 (2022), 340–356. https://doi.org/10.1016/j.ins.2022.03.097 doi: 10.1016/j.ins.2022.03.097
|
| [48] |
W. C. Zou, S. P. Wan, J. Y. Dong, L. Martinez, A new social network driven consensus reaching process for multi-criteria group decision making with probabilistic linguistic information, Inf. Sci., 632 (2023), 467–502. https://doi.org/10.1016/j.ins.2023.01.088 doi: 10.1016/j.ins.2023.01.088
|
| [49] |
F. Herrera, L. Martinez, An approach for combining linguistic numerical information based on the 2-tuple fuzzy linguistic representation model in decision-making, Int. J. Uncertain. Fuzz., 8 (2000), 539–562. https://doi.org/10.1142/S0218488500000381 doi: 10.1142/S0218488500000381
|
| [50] |
L. Li, M. T. Zong, J. Li, Research on a method of uncertain linguistic information group decision-making based on the Steiner point, Oper. Res. Manage., 27 (2018), 59–66. https://doi.org/10.12005/orms.2018.0134 doi: 10.12005/orms.2018.0134
|
| [51] | H. Y. Li, Z. P. Fan, Multi-criteria group decision making method based on two-tuple linguistic information processing, J. Northeast. U., 24 (2003), 495–498. |
| [52] |
J. Z. Liang, W. Song, Clustering based on Steiner points, Int. J. Mach. Learn. Cyb., 3 (2012), 141–148. https://doi.org/10.1007/s13042-011-0047-7 doi: 10.1007/s13042-011-0047-7
|
| [53] |
G. Georgeakopoulos, C. H. Papadimitriou, The 1-steiner tree problem, J. Algorithms, 8 (1987), 122–130. https://doi.org/10.1016/0196-6774(87)90032-0 doi: 10.1016/0196-6774(87)90032-0
|
| [54] |
X. Liu, H. Y. Chen, L. G. Zhou, Two-tuple linguistic multi-attribute decision making method based on T-GOWA and T-IGOWA operators, Stat. Decis. Ma., 2011, 22–26. https://doi.org/10.13546/j.cnki.tjyjc.2011.21.059 doi: 10.13546/j.cnki.tjyjc.2011.21.059
|
| [55] | T. Li, Z. T. Wang, Plant growth simulation algorithm and the thinking in knowledge innovation, J. Manag. Sci. China, 13 (2010), 87–96. |
| [56] |
T. Li, C. F. Wang, W. B. Wang, W. T. Su, A global optimization bionics algorithm for solving integer programming—plant growth simulation algorithm, Syst. Eng.-Theory Pra., 25 (2005), 76–85. https://doi.org/10.3321/j.issn:1000-6788.2005.01.012 doi: 10.3321/j.issn:1000-6788.2005.01.012
|
| [57] | T. Li, Z. T. Wang, Optimization layout of underground logistics network in big cities with plant growth simulation algorithm, Syst. Eng.-Theory Pra., 33 (2013), 971–980. |
| [58] | Q. Zhou, T. Li, C. F. Mao, W. Yang, The optimal model of cooperative R & D network decision based PGSA, Oper. Res. Manage., 23 (2014), 96–101. |
| [59] |
L. Li, X. L. Xie, R. Guo, Research on group decision making with interval numbers based on plant growth simulation algorithm, Kybernetes, 43 (2014), 250–264. https://doi.org/10.1108/K-07-2013-0138 doi: 10.1108/K-07-2013-0138
|
Figures(1) / Tables(1)

Zu-meng Qiu, Huan-huan Zhao, Jun Yang. A group decision making approach based on the multi-dimensional Steiner point[J]. AIMS Mathematics, 2024, 9(1): 942-958. doi: 10.3934/math.2024047







 DownLoad:
DownLoad: