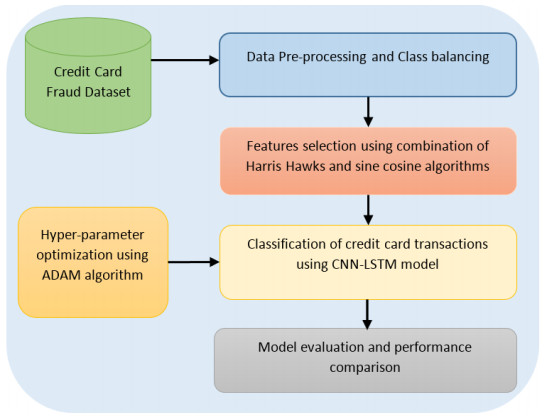
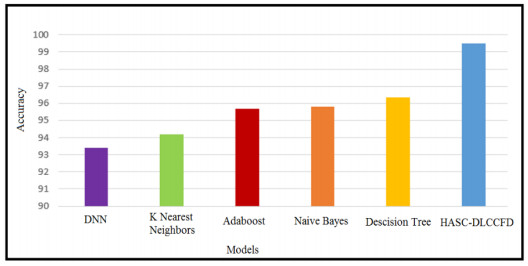
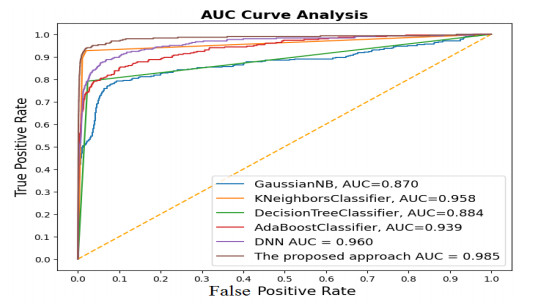
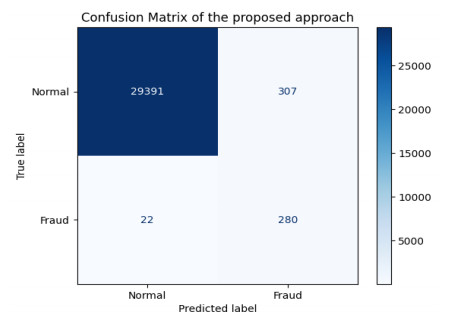
Credit cards have become an integral part of the modern financial landscape, and their use is essential for individuals and businesses. This has resulted in a significant increase in their usage in recent years, especially with the growing popularity of online payments. Unfortunately, this increase in credit card use has also led to a corresponding rise in credit card fraud, posing a serious threat to financial security and privacy. Therefore, this research introduces a novel deep learning-based hybrid Harris hawks with sine cosine method for credit card fraud detection system (HASC-DLCCFD). The aim of the presented HASC-DLCCFD approach is to identify fraudulent credit card transactions. The suggested HASC-DLCCFD scheme introduces a HASC technique for feature selection, by combining Harris hawks optimization (HHO) with the sine cosine algorithm (SCA). For the purpose of identifying credit card fraud, an architecture of a convolutional neural network combined with long short-term memory (CNN–LSTM) is utilized in this study. Finally, the adaptive moment estimation (Adam) algorithm is utilized as a hyperparameter optimizer of the CNN-LSTM model. The performance of the suggested HASC-DLCCFD approach was experimentally evaluated using a publicly available database. The results demonstrate that the suggested HASC-DLCCFD approach outperforms other current techniques and achieved the highest accuracy of 99.5%.
Citation: Altyeb Taha. A novel deep learning-based hybrid Harris hawks with sine cosine approach for credit card fraud detection[J]. AIMS Mathematics, 2023, 8(10): 23200-23217. doi: 10.3934/math.20231180
Credit cards have become an integral part of the modern financial landscape, and their use is essential for individuals and businesses. This has resulted in a significant increase in their usage in recent years, especially with the growing popularity of online payments. Unfortunately, this increase in credit card use has also led to a corresponding rise in credit card fraud, posing a serious threat to financial security and privacy. Therefore, this research introduces a novel deep learning-based hybrid Harris hawks with sine cosine method for credit card fraud detection system (HASC-DLCCFD). The aim of the presented HASC-DLCCFD approach is to identify fraudulent credit card transactions. The suggested HASC-DLCCFD scheme introduces a HASC technique for feature selection, by combining Harris hawks optimization (HHO) with the sine cosine algorithm (SCA). For the purpose of identifying credit card fraud, an architecture of a convolutional neural network combined with long short-term memory (CNN–LSTM) is utilized in this study. Finally, the adaptive moment estimation (Adam) algorithm is utilized as a hyperparameter optimizer of the CNN-LSTM model. The performance of the suggested HASC-DLCCFD approach was experimentally evaluated using a publicly available database. The results demonstrate that the suggested HASC-DLCCFD approach outperforms other current techniques and achieved the highest accuracy of 99.5%.

| [1] | R. Van Belle, B. Baesens, J. De Weerdt, CATCHM: A novel network-based credit card fraud detection method using node representation learning, Decis. Support Syst., 164 (2023), 113866. https://doi.org/10.1016/j.dss.2022.113866 |
| [2] | G. Zhang, Z. Li, J. Huang, J. Wu, C. Zhou, J. Yang, et al., efraudcom: An e-commerce fraud detection system via competitive graph neural networks, ACM T. Inform. Syst., 40 (2022), 1–29. https://doi.org/10.1145/3474379 |
| [3] | N. Prabhakaran, R. Nedunchelian, Oppositional Cat Swarm optimization-based feature selection approach for credit card fraud detection, Comput. Intell. Neurosci., 2023 (2023), Article ID 2693022. https://doi.org/10.1155/2023/2693022 |
| [4] |
H. Fanai, H. Abbasimehr, A novel combined approach based on deep Autoencoder and deep classifiers for credit card fraud detection, Expert Syst. Appl., 217 (2023), 119562. https://doi.org/10.1016/j.eswa.2023.119562 doi: 10.1016/j.eswa.2023.119562

|
| [5] |
H. Tingfei, C. Guangquan, H. Kuihua, Using variational auto encoding in credit card fraud detection, IEEE Access, 8 (2020), 149841–149853. https://doi.org/10.1109/ACCESS.2020.3015600 doi: 10.1109/ACCESS.2020.3015600
|
| [6] |
I. D. Mienye, Y. Sun, A deep learning ensemble with data resampling for credit card fraud detection, IEEE Access, 11 (2023), 30628–30638. https://doi.org/10.1109/ACCESS.2023.3262020 doi: 10.1109/ACCESS.2023.3262020
|
| [7] |
E. F. Malik, K. W. Khaw, B. Belaton, W. P. Wong, X. Chew, Credit card fraud detection using a new hybrid machine learning architecture, Mathematics, 10 (2022), 1480. https://doi.org/10.3390/math10091480 doi: 10.3390/math10091480
|
| [8] |
A. A.Taha, S. J. Malebary, An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine, IEEE Access, 8 (2020), 25579–25587. https://doi.org/10.1109/ACCESS.2020.2971354 doi: 10.1109/ACCESS.2020.2971354
|
| [9] | E. Btoush, X. Zhou, R. Gururaian, K. C. Chan, X. Tao, A survey on credit card fraud detection techniques in banking industry for cyber security, In: Proceedings of the 2021 8th International Conference on Behavioral and Social Computing (BESC), Doha, Qatar, 2021. https://doi.org/10.1109/BESC53957.2021.9635559 |
| [10] | A. Cherif, A. Badhib, H. Ammar, S. Alshehri, M. Kalkatawi, A. Imine, Credit card fraud detection in the era of disruptive technologies: A systematic review, J. King Saud Univ. Comput. Inf. Sci., 35 (2022), 145–174. https://doi.org/10.1016/j.jksuci.2022.11.008 |
| [11] |
I. D. Mienye, Y. Sun, Performance analysis of cost-sensitive learning methods with application to imbalanced medical data, Inform. Med. Unlocked, 25 (2021), 100690. https://doi.org/10.1016/j.imu.2021.100690 doi: 10.1016/j.imu.2021.100690
|
| [12] |
E. Strelcenia, S. Prakoonwit, Improving classification performance in credit card fraud detection by using new data augmentation, AI, 4 (2023), 172–198. https://doi.org/10.3390/ai4010008 doi: 10.3390/ai4010008
|
| [13] |
M. Afif, R. Ayachi, Y. Said, M. Atri, An evaluation of EfficientDet for object detection used for indoor robots assistance navigation, J. Real Time Image Process., 19 (2022), 651–661. https://doi.org/10.1007/s11554-022-01212-4 doi: 10.1007/s11554-022-01212-4
|
| [14] | R. Ayachi, M. Afif, Y. Said, A. Ben Abdelali, Drivers fatigue detection using EfficientDet in advanced driver assistance systems, In: Proceedings of the 18th International Multi-Conference on Systems, Signals & Devices, Monastir, Tunisia, 2021. https://doi.org/10.1109/SSD52085.2021.9429294 |
| [15] | N. Ayoobi, D. Sharifrazi, R. Alizadehsani, A. Shoeibi, J. M. Gorriz, H. Moosaei, et al., Time series forecasting of new cases and new deaths rate for COVID-19 using deep learning methods, Results Phys., 27 (2021), 104495. https://doi.org/10.1016/j.rinp.2021.104495 |
| [16] |
R. Bin Sulaiman, V. Schetinin, P. Sant, Review of machine learning approach on credit card fraud detection, Human-Centric Intel. Syst., 2 (2022), 55–68. https://doi.org/10.1007/s44230-022-00004-0 doi: 10.1007/s44230-022-00004-0
|
| [17] |
M. Alamri, M. Ykhlef, Survey of credit card anomaly and fraud detection using sampling techniques, Electronics, 11 (2022), 4003. https://doi.org/10.3390/electronics11234003 doi: 10.3390/electronics11234003
|
| [18] |
E. Strelcenia, S. Prakoonwit, A survey on GAN techniques for data augmentation to address the imbalanced data issues in credit card fraud detection, Mach. Learn. Knowl. Extr, 5 (2023), 304–329. https://doi.org/10.3390/make5010019 doi: 10.3390/make5010019
|
| [19] | C. Sudha, D. Akila, Credit Card Fraud Detection System based on Operational Transaction features using SVM and Random Forest Classifiers, In: Proceedings of 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, UAE, 19-21 January 2021. https://doi.org/10.1109/ICCAKM50778.2021.9357709 |
| [20] | T. Wang, Y. Zhao, Credit Card Fraud Detection using Logistic Regression, In: Proceedings of 2022 International Conference on Big Data, Information and Computer Network (BDICN), Sanya, China, 20 Jan 2022. 301–305. https://doi.org/10.1109/BDICN55575.2022.00064 |
| [21] | J. K. Afriyie, K. Tawiah, W. A. Pels, S. Addai-Henne, H. A. Dwamena, E. O. Owiredu, et al., Supervised machine learning algorithm for detecting and predicting fraud in credit card transactions, Decis. Anal., 6 (2023), 100163. https://doi.org/10.1016/j.dajour.2023.100163 |
| [22] | C. Wang, Y. Wang, Z. Ye, L. Yan, W. Cai, S. Pan, Credit Card Fraud Detection Based on Whale Algorithm Optimized BP Neural Network, In: Proceedings of 2018 13th International Conference on Computer Science Education (ICCSE), Colombo, Sri Lanka, 8-11August, 2018. https://doi.org/10.1109/ICCSE.2018.8468855 |
| [23] | X. Kewei, B. Peng, Y. Jiang, T. Lu, A Hybrid Deep Learning Model For Online Fraud Detection, In: Proceedings of 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021. https://doi.org/10.1109/ICCECE51280.2021.9342110 |
| [24] |
X. Zhang, Y. Han, W. Xu, Q. Wang, Hoba: A novel feature engineering methodology for credit card fraud detection with a deep learning architecture., Inf. Sci., 557 (2021), 302–316. https://doi.org/10.1016/j.ins.2019.05.023 doi: 10.1016/j.ins.2019.05.023
|
| [25] |
Y. Xie, G. Liu, C. Yan, C. Jiang, M. Zhou, M. Li, Learning transactional behavioral representations for credit card fraud detection, IEEE T. Neural Net. Lear., 2022, 1–14. https://doi.org/10.1109/TNNLS.2022.3208967 doi: 10.1109/TNNLS.2022.3208967
|
| [26] |
Y. Xie, G. Liu, C. Yan, C. Jiang, M. Zhou, Time-aware attention-based gated network for credit card fraud detection by extracting transactional behaviors, IEEE Trans. Comput. Soc., 10 (2022), 1004–1016. https://doi.org/10.1109/TCSS.2022.3158318 doi: 10.1109/TCSS.2022.3158318
|
| [27] |
Z. Li, M. Huang, G. Liu, C. Jiang, A hybrid method with dynamic weighted entropy for handling the problem of class imbalance with overlap in credit card fraud detection, Expert Syst. Appl., 175 (2021), 114750. https://doi.org/10.1016/j.eswa.2021.114750 doi: 10.1016/j.eswa.2021.114750
|
| [28] | H. Q. Abdulrab, F. A. Hussin, I. Ismail, M. Assaad, A. Awang, H. Shutari, et al., Hybrid Harris Hawks with Sine Cosine for Optimal Node Placement and Congestion Reduction in an Industrial Wireless Mesh Network, IEEE Access, 11 (2023), 2500–2523. https://doi.org/10.1109/ACCESS.2023.3234109 |
| [29] |
Y. Liu, C. Yang, K. Huang, W. Liu, A multi-factor selection and fusion method through the CNN-LSTM network for dynamic price forecasting, Mathematics, 11 (2023), 1132. https://doi.org/10.3390/math11051132 doi: 10.3390/math11051132
|
| [30] |
R. Gao, J. Xu, Y. Chen, K. Cho, Heterogeneous feature fusion module based on CNN and transformer for multiview stereo reconstruction, Mathematics, 11 (2023), 112. https://doi.org/10.3390/math11010112 doi: 10.3390/math11010112
|
| [31] |
W. Lu, J. Li, J. Wang, L. Qin, A CNN-BiLSTM-AM method for stock price prediction, Neural Comput. Appl., 33 (2020), 4741–4753. https://doi.org/10.1007/s00521-020-05532-z doi: 10.1007/s00521-020-05532-z
|
| [32] | Credit card fraud dataset. Available from: https://www.kaggle.com/datasets/kartik2112/fraud-detection. (Accessed on 3 March 2023). |
| [33] | I. Goodfellow, Y. Bengio, A. Courville, Deep learning, Genet. Program. Evol. M., 19 (2018), 305–307. https://doi.org/10.1007/s10710-017-9314-z |
| [34] | P. B. Le, Z. T. Nguyen, ROC curves, loss functions, and distorted probabilities in binary classification, Mathematics, 10 (2022), 1410. https://doi.org/10.3390/math10091410 |
| [35] |
S. Jiang, R. Dong, J. Wang, M. Xia, Credit card fraud detection based on unsupervised attentional anomaly detection network, Systems, 1 (2023), 1–14. https://doi.org/10.3390/systems11060305 doi: 10.3390/systems11060305
|
| [36] | T. Baabdullah, D. B. Rawat, C. Liu, A. Alzahrani, An Ensemble-Based Machine Learning for Predicting Fraud of Credit Card Transactions, In: Proceedings of Intelligent Computing: In Proceedings of 2022 Computing Conference, London, United Kingdom, July 14–15, 2022. https://doi.org/10.1007/978-3-031-10464-0_14 |
| [37] |
H. Ahmad, B. Kasasbeh, B. Aldabaybah, E. Rawashdeh, Class balancing framework for credit card fraud detection based on clustering and similarity-based selection (SBS), Int. J. Inf., 15 (2023), 325–333. https://doi.org/10.1007/s41870-022-00987-w doi: 10.1007/s41870-022-00987-w
|
| [38] | A. Mniai, K. Jebari, Credit Card Fraud Detection by Improved SVDD, In: Proceedings of 2022 World Congress on Engineering, WCE 2022, London, U.K., 6–8 July, 2022. ISBN: 978-988-14049-3-0 |
Figures(7) / Tables(3)

Altyeb Taha. A novel deep learning-based hybrid Harris hawks with sine cosine approach for credit card fraud detection[J]. AIMS Mathematics, 2023, 8(10): 23200-23217. doi: 10.3934/math.20231180







 DownLoad:
DownLoad: