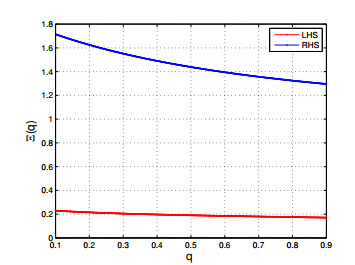
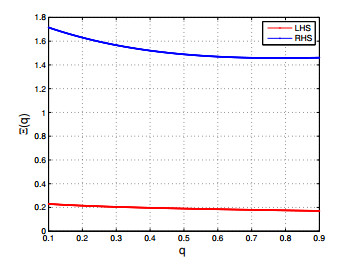
The objective of this paper is to explore novel unified continuous and discrete versions of the Trapezium-Jensen-Mercer (TJM) inequality, incorporating the concept of convex mapping within the framework of $ {\mathfrak{q}} $-calculus, and utilizing majorized tuples as a tool. To accomplish this goal, we establish two fundamental lemmas that utilize the $ _{{\varsigma_{1}}}{\mathfrak{q}} $ and $ ^{{{\varsigma_{2}}}}{\mathfrak{q}} $ differentiability of mappings, which are critical in obtaining new left and right side estimations of the midpoint $ {\mathfrak{q}} $-TJM inequality in conjunction with convex mappings. Our findings are significant in a way that they unify and improve upon existing results. We provide evidence of the validity and comprehensibility of our outcomes by presenting various applications to means, numerical examples, and graphical illustrations.
Citation: Bandar Bin-Mohsin, Muhammad Zakria Javed, Muhammad Uzair Awan, Hüseyin Budak, Awais Gul Khan, Clemente Cesarano, Muhammad Aslam Noor. Unified inequalities of the $ {\mathfrak{q}} $-Trapezium-Jensen-Mercer type that incorporate majorization theory with applications[J]. AIMS Mathematics, 2023, 8(9): 20841-20870. doi: 10.3934/math.20231062
The objective of this paper is to explore novel unified continuous and discrete versions of the Trapezium-Jensen-Mercer (TJM) inequality, incorporating the concept of convex mapping within the framework of $ {\mathfrak{q}} $-calculus, and utilizing majorized tuples as a tool. To accomplish this goal, we establish two fundamental lemmas that utilize the $ _{{\varsigma_{1}}}{\mathfrak{q}} $ and $ ^{{{\varsigma_{2}}}}{\mathfrak{q}} $ differentiability of mappings, which are critical in obtaining new left and right side estimations of the midpoint $ {\mathfrak{q}} $-TJM inequality in conjunction with convex mappings. Our findings are significant in a way that they unify and improve upon existing results. We provide evidence of the validity and comprehensibility of our outcomes by presenting various applications to means, numerical examples, and graphical illustrations.

| [1] | S. S. Dragomir, C. Pearce, Selected topics on Hermite-Hadamard inequalities and applications, 2003. |
| [2] | A. M. D. Mercer, A variant of Jensen's inequality, J. Inequal. Pure Appl. Math., 4 (2003), 73. |
| [3] |
S. S. Dragomir, R. P. Agarwal, Two inequalities for differentiable mappings and applications to special means of real numbers and to trapezoidal formula, Appl. Math. Lett., 11 (1998), 91–95. https://doi.org/10.1016/S0893-9659(98)00086-X doi: 10.1016/S0893-9659(98)00086-X

|
| [4] | M. Kian, M. S. Moslehian, Refinements of the operator Jensen-Mercer inequality, Electron.J. Linear Al., 26 2013,742–753. https://doi.org/10.13001/1081-3810.1684 |
| [5] |
H. Ogulmus, M. Z. Sarikaya, Hermite-Hadamard-Mercer type inequalities for fractional integrals, Filomat, 35 (2021), 2425–2436. https://doi.org/10.2298/FIL2107425O doi: 10.2298/FIL2107425O
|
| [6] |
S. I. Butt, A. Kashuri, M. Umar, A. Aslam, W. Gao, Hermite-Jensen-Mercer type inequalities via $\Lambda $-Riemann-Liouville $k$-fractional integrals, AIMS Math., 5 (2020), 5193–5220. https://doi.org/10.3934/math.2020334 doi: 10.3934/math.2020334
|
| [7] |
S. I. Butt, M. Umar, S. Rashid, A. O. Akdemir, Y. M. Chu, New Hermite-Jensen-Mercer-type inequalities via $k$-fractional integrals, Adv. Differ. Equ., 2020 (2020), 635. https://doi.org/10.1186/s13662-020-03093-y doi: 10.1186/s13662-020-03093-y
|
| [8] |
H. H. Chu, S. Rashid, Z. Hammouch, Y. M. Chu, New fractional estimates for Hermite-Hadamard-Mercer's type inequalities, Alex. Eng. J., 59 (2020), 3079–3089. https://doi.org/10.1016/j.aej.2020.06.040 doi: 10.1016/j.aej.2020.06.040
|
| [9] |
M. Vivas-Cortez, M. A. Ali, A. Kashuri, H. Budak, Generalizations of fractional Hermite-Hadamard-Mercer like inequalities for convex functions, AIMS Math., 6 (2021), 9397–9421. https://doi.org/10.3934/math.2021546 doi: 10.3934/math.2021546
|
| [10] |
M. Vivas-Cortez, M. U. Awan, M. Z. Javed, A. Kashuri, M. A Noor, K. I. Noor, Some new generalized $k$-fractional Hermite-Hadamard-Mercer type integral inequalities and their applications, AIMS Math., 7 (2022), 3203–3220. https://doi.org/10.3934/math.2022177 doi: 10.3934/math.2022177
|
| [11] |
W. Sudsutad, S. K. Ntouyas, J. Tariboon, Quantum integral inequalities for convex functions, J. Math. Inequal., 9 (2015), 781–793. https://doi.org/10.7153/jmi-09-64 doi: 10.7153/jmi-09-64
|
| [12] |
M. A. Noor, K. I. Noor, M. U. Awan, Some quantum estimates for Hermite-Hadamard inequalities, Appl. Math. Comput., 251 (2015), 675–679. https://doi.org/10.1016/j.amc.2014.11.090 doi: 10.1016/j.amc.2014.11.090
|
| [13] |
N. Alp, M. Z. Sarıkaya, M. Kunt, İ. İşcan, $ q$-Hermite Hadamard inequalities and quantum estimates for midpoint type inequalities via convex and quasi-convex functions, J. King Saud Univ. Sci., 30 (2018), 193–203. https://doi.org/10.1016/j.jksus.2016.09.007 doi: 10.1016/j.jksus.2016.09.007
|
| [14] |
Y. Zhang, T. S. Du, H. Wang Y. J, Shen, Different types of quantum integral inequalities via $(\alpha, m)$-convexity, J. Inequal. Appl., 2018 (2018), 264. https://doi.org/10.1186/s13660-018-1860-2 doi: 10.1186/s13660-018-1860-2
|
| [15] |
Y. Deng, M. U. Awan, S. Wu, Quantum integral inequalities of Simpson-type for strongly preinvex functions, Mathematics, 7 (2019), 751. https://doi.org/10.3390/math7080751 doi: 10.3390/math7080751
|
| [16] | M. Kunt, M. Aljasem, Fractional quantum Hermite-Hadamard type inequalities, Konuralp J. Math., 8 (2020), 122–136. |
| [17] |
M. Vivas-Cortez, M. Z. Javed, M. U. Awan, A. Kashuri, M. A. Noor, Generalized $(p, q)$-analogues of Dragomir-Agarwal's inequalities involving Raina's mapping and applications, AIMS Math, 7 (2022), 11464–11486. https://doi.org/10.3934/math.2022639 doi: 10.3934/math.2022639
|
| [18] |
S. Erden, S. Iftikhar, R. M. Delavar, P. Kumam, P. Thounthong, W. Kumam, On generalizations of some inequalities for convex functions via quantum integrals, RACSAM Rev. R. Acad. A, 114 (2020), 110. https://doi.org/10.1007/s13398-020-00841-3 doi: 10.1007/s13398-020-00841-3
|
| [19] |
P. P. Wang, T. Zhu, T. S. Du, Some inequalities using $s$-preinvexity via quantum calculus, J. Interdiscip. Math., 24 (2021), 613–636. https://doi.org/10.1080/09720502.2020.1809117 doi: 10.1080/09720502.2020.1809117
|
| [20] |
M. Vivas-Cortez, M. U. Awan, S. Talib, A. Kashuri, M. A. Noor, Multi-parameter quantum integral identity involving Raina's function and corresponding $q$-integral inequalities with applications, Symmetry, 14 (2022), 606. https://doi.org/10.3390/sym14030606 doi: 10.3390/sym14030606
|
| [21] |
Y. M. Chu, M. U. Awan, S. Talib, M. A. Noor, K. I. Noor, New post quantum analogues of Ostrowski-type inequalities using new definitions of left-right $(p, q$-derivatives and definite integrals, Adv. Differ. Equ., 2020 (2020), 634. https://doi.org/10.1186/s13662-020-03094-x doi: 10.1186/s13662-020-03094-x
|
| [22] |
H. Kalsoom, M. Vivas-Cortez, $q_1, q_2$-Ostrowski-type integral inequalities involving property of generalized higher-order strongly $n$-polynomial preinvexity, Symmetry, 14 (2022), 717. https://doi.org/10.3390/sym14040717 doi: 10.3390/sym14040717
|
| [23] |
M. A. Ali, H. Budak, M. Feckan, S, Khan, A new version of $q$-Hermite-Hadamard's midpoint and trapezoid type inequalities for convex functions, Math. Slovaca, 73 (2023), 369–386. https://doi.org/10.1515/ms-2023-0029 doi: 10.1515/ms-2023-0029
|
| [24] |
B. Bin-Mohsin, M. Saba, M. Z. Javed, M. U. Awan, H. Budak, K. Nonlaopon, A quantum calculus view of Hermite-Hadamard-Jensen-Mercer inequalities with applications, Symmetry, 14 (2022), 1246. https://doi.org/10.3390/sym14061246 doi: 10.3390/sym14061246
|
| [25] | H. Budak, H. Kara, On quantum Hermite-Jensen-Mercer inequalities, Miskolc Math. Notes, 2016. |
| [26] |
M. Bohner, H. Budak, H. Kara, Post-quantum Hermite-Jensen-Mercer inequalities, Rocky Mountain J. Math., 53 (2023), 17–26. https://doi.org/10.1216/rmj.2023.53.17 doi: 10.1216/rmj.2023.53.17
|
| [27] |
H. Budak, M. A. Ali, M. Tarhanaci, Some new quantum Hermite-Hadamard-like inequalities for coordinated convex functions, J. Optim. Theory Appl., 186 (2020), 899–910. https://doi.org/10.1007/s10957-020-01726-6 doi: 10.1007/s10957-020-01726-6
|
| [28] |
M. A. Ali, H. Budak, M. Abbas, Y. M. Chu, Quantum Hermite-Hadamard-type inequalities for functions with convex absolute values of second $ q^a$ derivatives, Adv. Differ. Equ., 2021 (2021), 7. https://doi.org/10.1186/s13662-020-03163-1 doi: 10.1186/s13662-020-03163-1
|
| [29] |
K. Nonlaopon, M. U. Awan, M. Z. Javed, H. Budak, M. A. Noor, Some $q$-fractional estimates of trapezoid like inequalities involving Raina's function, Fractal Fract., 6 (2022), 185. https://doi.org/10.3390/fractalfract6040185 doi: 10.3390/fractalfract6040185
|
| [30] |
N. Siddique, M. Imran, K. A. Khan, J. Pecaric, Majorization inequalities via Green functions and Fink's identity with applications to Shannon entropy, J. Inequal. Appl., 2020 (2020), 192. https://doi.org/10.1186/s13660-020-02455-0 doi: 10.1186/s13660-020-02455-0
|
| [31] |
N. Siddique, M. Imran, K. A. Khan, J. Pecaric, Difference equations related to majorization theorems via Montgomery identity and Green's functions with application to the Shannon entropy, Adv. Differ. Equ., 2020 (2020), 430. https://doi.org/10.1186/s13662-020-02884-7 doi: 10.1186/s13662-020-02884-7
|
| [32] |
S. Faisal, M. A. Khan, T. U. Khan, T. Saeed, A. M. Alshehri, E. R Nwaeze, New conticrete Hermite-Hadamard-Jensen-Mercer fractional inequalities, Symmetry, 14 (2022), 294. https://doi.org/10.3390/sym14020294 doi: 10.3390/sym14020294
|
| [33] |
J. Tariboon, S. K. Ntouyas, Quantum calculus on finite intervals and applications to impulsive difference equations, Adv. Differ. Equ., 2013 (2013), 282. https://doi.org/10.1186/1687-1847-2013-282 doi: 10.1186/1687-1847-2013-282
|
| [34] |
S. Bermudo, P. Korus, J. N. Valdes, On $q$-Hermite-Hadamard inequalities for general convex functions, Acta Math. Hungar., 162 (2020), 364–374. https://doi.org/10.1007/s10474-020-01025-6 doi: 10.1007/s10474-020-01025-6
|
| [35] | S. S. Dragomir, Some majorization type discrete inequalities for convex functions, Math. Inequal. Appl., 7 (2004), 207–216. |
| [36] | G. H. Hardy, J. E. Littlewood, G. Pólya, Inequalities, Cambridge University Press, 1952. |
| [37] | N. Latif, I. Peric, J. Pecaric, On discrete Farvald's and Bervald's inequalities, Commun. Math. Anal., 12 (2012) 34–57. |
| [38] |
M. Niezgoda, A generalization of Mercer's result on convex functions, Nonlinear Anal. Theor., 71 (2009), 2771–2779. https://doi.org/10.1016/j.na.2009.01.120 doi: 10.1016/j.na.2009.01.120
|
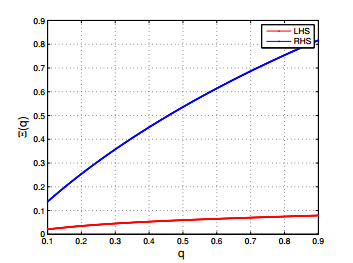
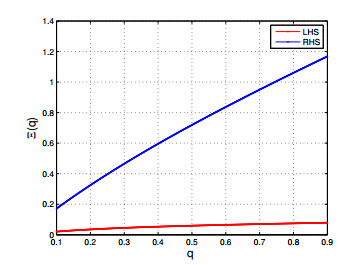
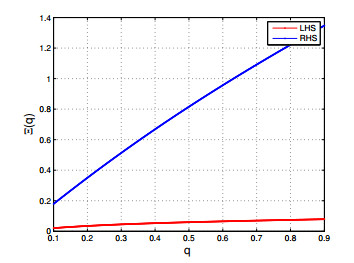
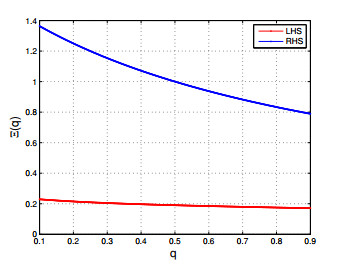
Figures(6)

Bandar Bin-Mohsin, Muhammad Zakria Javed, Muhammad Uzair Awan, Hüseyin Budak, Awais Gul Khan, Clemente Cesarano, Muhammad Aslam Noor. Unified inequalities of the $ {\mathfrak{q}} $-Trapezium-Jensen-Mercer type that incorporate majorization theory with applications[J]. AIMS Mathematics, 2023, 8(9): 20841-20870. doi: 10.3934/math.20231062







 DownLoad:
DownLoad: