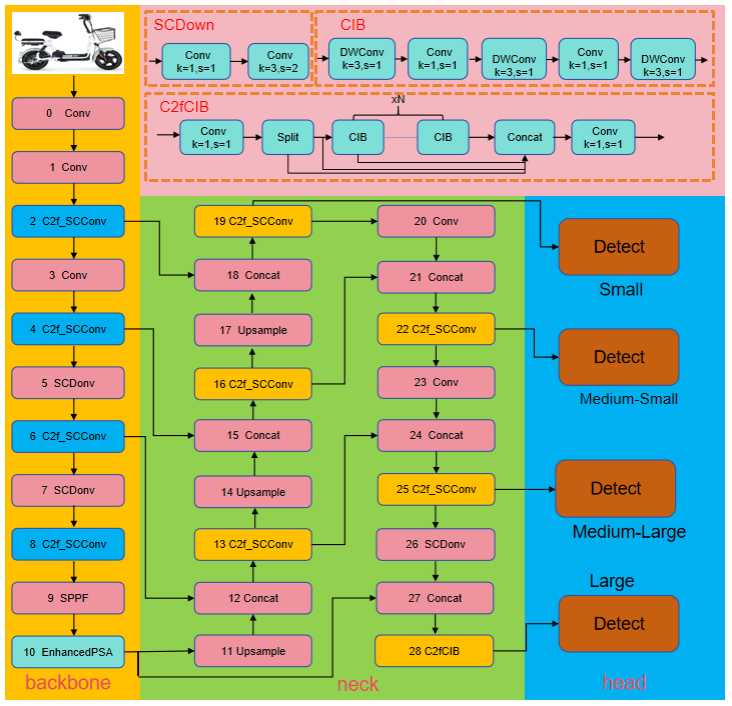
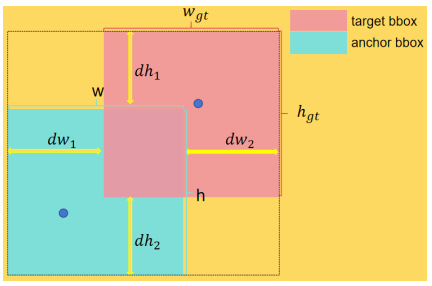
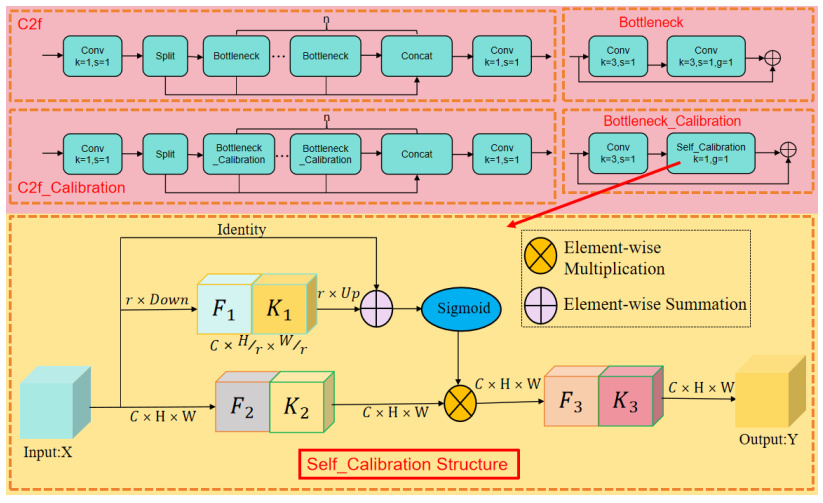
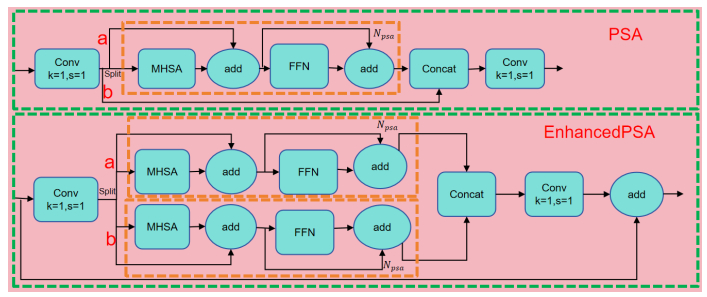
The presence of electric bicycles in elevators poses serious safety hazards, necessitating reliable automatic detection solutions. To address these issues, this paper proposes EBike-YOLO, an enhanced real-time detection model based on YOLOv10n, specifically optimized for elevator environments. EBike-YOLO introduces three key innovations: 1) the PIoU2_NWD loss function, combining adaptive penalty mechanisms, anchor-quality-aware gradient adjustments, non-monotonic attention, and Wasserstein distance for significantly improved object localization; 2) the EnhancedPSA structure, refining self-attention and feed-forward network architectures to enhance feature extraction; and 3) the C2f_Calibration module, incorporating self-calibration operations to robustly manage diverse orientations and scales of electric bicycles. Extensive experiments on a custom elevator dataset demonstrate substantial improvements over the YOLOv10n baseline, achieving notable enhancements in precision (4.1%), recall (0.3%), F1 score (2.0%), and mAP@50 (2.23%). Further validations on standard benchmark datasets (VisDrone2019, VOC2007, VOC2012) confirm the model's strong generalization capability, underscoring its applicability beyond specific elevator scenarios. These results clearly highlight the effectiveness, novelty, and practical value of the proposed model for diverse real-world detection tasks.
Citation: Tong Li, Lanfang Lei, Zhong Wang, Peibei Shi, Zhize Wu. An efficient improved YOLOv10 algorithm for detecting electric bikes in elevators[J]. Electronic Research Archive, 2025, 33(6): 3673-3698. doi: 10.3934/era.2025163
The presence of electric bicycles in elevators poses serious safety hazards, necessitating reliable automatic detection solutions. To address these issues, this paper proposes EBike-YOLO, an enhanced real-time detection model based on YOLOv10n, specifically optimized for elevator environments. EBike-YOLO introduces three key innovations: 1) the PIoU2_NWD loss function, combining adaptive penalty mechanisms, anchor-quality-aware gradient adjustments, non-monotonic attention, and Wasserstein distance for significantly improved object localization; 2) the EnhancedPSA structure, refining self-attention and feed-forward network architectures to enhance feature extraction; and 3) the C2f_Calibration module, incorporating self-calibration operations to robustly manage diverse orientations and scales of electric bicycles. Extensive experiments on a custom elevator dataset demonstrate substantial improvements over the YOLOv10n baseline, achieving notable enhancements in precision (4.1%), recall (0.3%), F1 score (2.0%), and mAP@50 (2.23%). Further validations on standard benchmark datasets (VisDrone2019, VOC2007, VOC2012) confirm the model's strong generalization capability, underscoring its applicability beyond specific elevator scenarios. These results clearly highlight the effectiveness, novelty, and practical value of the proposed model for diverse real-world detection tasks.

| [1] |
Y. Liu, Q. Xu, Y. Yang, W. Zhang, Detection of electric bicycle indoor charging for electrical safety: A NILM approach, IEEE Trans. Smart Grid, 14 (2023), 3862–3875. https://doi.org/10.1109/TSG.2023.3245636 doi: 10.1109/TSG.2023.3245636

|
| [2] |
Y. Li, L. Han, X. Ning, Y. Xu, Fire risk of electric bicycle based on fuzzy Bayesian network, J. Phys.: Conf. Ser. , 1578 (2020), 012153. https://doi.org/10.1088/1742-6596/1578/1/012153 doi: 10.1088/1742-6596/1578/1/012153
|
| [3] | W. Ying, Z. Yongping, X. Fang, X. Jian, Analysis model for fire accidents of electric bicycles based on principal component analysis, in 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), 1 (2017), 760–762. https://doi.org/10.1109/CSE-EUC.2017.149 |
| [4] |
P. Viola, M. J. Jones, Robust real-time face detection, Int. J. Comput. Vis. , 57 (2004), 137–154. https://doi.org/10.1023/B:VISI.0000013087.49260.fb doi: 10.1023/B:VISI.0000013087.49260.fb
|
| [5] | N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Pecognition (CVPR'05), 1 (2005), 886–893. https://doi.org/10.1109/CVPR.2005.177 |
| [6] | S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, Adv. Neural Inf. Process. Syst., 28 (2015). |
| [7] | R. Girshick, Fast r-cnn, in Proceedings of the IEEE International Conference on Computer Vision, (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [8] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [9] | J. Redmon, A. Farhadi, YOLO9000: Better, faster, stronger, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 7263–7271. https://doi.org/10.1109/CVPR.2017.690 |
| [10] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, preprint, arXiv: 1804.02767. |
| [11] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, YOLOv4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. |
| [12] |
L. Li, X. Wang, M. Yang, H. Zhang, An accurate shared bicycle detection network based on faster R-CNN, IET Image Process., 17 (2023), 1919–1930. https://doi.org/10.1049/ipr2.12766 doi: 10.1049/ipr2.12766
|
| [13] |
A. John, D. Meva, N. Arora, Deep learning based road traffic assessment for vehicle rerouting: An extensive experimental study of RetinaNet and YOLO models, Int. Res. J. Multidiscip. Technovation, 6 (2024), 134–152. https://doi.org/10.54392/irjmt2459 doi: 10.54392/irjmt2459
|
| [14] |
J. Miguel, P. Mendonça, A. Quelhas, J. M. Caldeira, V. N. Soares, Using computer vision to collect information on cycling and hiking trails users, Future Internet, 16 (2024), 104. https://doi.org/10.3390/fi16030104 doi: 10.3390/fi16030104
|
| [15] | W. Wang, Y. Xu, Z. Xu, C. Zhang, T. Li, J. Wang, et al., A detection method of electro-bicycle in elevators based on improved YOLO v4, in 2021 26th International Conference on Automation and Computing (ICAC), (2021), 1–6. https://doi.org/10.23919/ICAC50006.2021.9594217 |
| [16] | C. Zhang, A. Xiong, X. Luo, C. Zhou, J. Liang, Electric bicycle detection based on improved YOLOv5, in 2022 4th International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), (2022), 1–5. https://doi.org/10.1109/CTISC54888.2022.9849750 |
| [17] | J. Sun, Y. Zhang, Electric bicycle detection based on deep learning, in Proceedings of the 5th International Conference on Computer Science and Software Engineering, (2022), 115–120. https://doi.org/10.1145/3569966.3570001 |
| [18] |
J. Su, M. Yang, X. Tang, Integration of ShuffleNet V2 and YOLOv5s networks for a lightweight object detection model of electric bikes within elevators, Electronics, 13 (2024), 394. https://doi.org/10.3390/electronics13020394 doi: 10.3390/electronics13020394
|
| [19] |
Z. Zhao, S. Li, C. Wu, X. Wei, Research on the rapid recognition method of electric bicycles in elevators based on machine vision, Sustainability, 15 (2023), 13550. https://doi.org/10.3390/su151813550 doi: 10.3390/su151813550
|
| [20] |
Z. Liu, C. Dai, X. Li, An electric bicycle tracking algorithm for improved traffic management, Heliyon, 10 (2024). https://doi.org/10.1016/j.heliyon.2024.e32708 doi: 10.1016/j.heliyon.2024.e32708
|
| [21] | H. Zhong, Z. Wang, Z. Chen, W. Chen, Y. Li, A novel fire monitoring system for electric bicycle shed based on YOLOv8, in 2023 IEEE 16th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), (2023), 142–147. https://doi.org/10.1109/MCSoC60832.2023.00029 |
| [22] |
C. Liu, K. Wang, Q. Li, F. Zhao, K. Zhao, H. Ma, Powerful-IoU: More straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism, Neural Networks, 170 (2024), 276–284. https://doi.org/10.1016/j.neunet.2023.11.041 doi: 10.1016/j.neunet.2023.11.041
|
| [23] | J. Wang, C. Xu, W. Yang, L. Yu, A normalized Gaussian Wasserstein distance for tiny object detection, preprint, arXiv: 2110.13389. |
| [24] | J. J. Liu, Q. Hou, M. M. Cheng, C. Wang, J. Feng, Improving convolutional networks with self-calibrated convolutions, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 10096–10105. |
| [25] | Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, D. Ren, Distance-IoU loss: Faster and better learning for bounding box regression, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 12993–13000. https://doi.org/10.1609/aaai.v34i07.6999 |
| [26] | Z. Tong, Y. Chen, Z. Xu, R. Yu, Wise-IoU: Bounding box regression loss with dynamic focusing mechanism, preprint, arXiv: 2301.10051. |
| [27] | Z. Gevorgyan, SIoU loss: More powerful learning for bounding box regression, preprint, arXiv: 2205.12740. |
| [28] | H. Zhang, S. Zhang, Shape-IoU: More accurate metric considering bounding box shape and scale, preprint, arXiv: 2312.17663. |
| [29] | H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, S. Savarese, Generalized intersection over union: A metric and a loss for bounding box regression, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 658–666. https://doi.org/10.1109/CVPR.2019.00075 |
| [30] |
Y. F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, T. Tan, Focal and efficient IOU loss for accurate bounding box regression, Neurocomputing, 506 (2022), 146–157. https://doi.org/10.1016/j.neucom.2022.07.042 doi: 10.1016/j.neucom.2022.07.042
|
| [31] | S. Ma, Y. Xu, MPDIoU: A loss for efficient and accurate bounding box regression, preprint, arXiv: 2307.07662. |
| [32] | H. Zhang, C. Xu, S. Zhang, Inner-IoU: More effective intersection over union loss with auxiliary bounding box, preprint, arXiv: 2311.02877. |
| [33] | C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, et al., YOLOv6: A single-stage object detection framework for industrial applications, preprint, arXiv: 2209.02976. |
| [34] | C. Y. Wang, A. Bochkovskiy, H. Y. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721 |
| [35] | C. Y. Wang, I. H. Yeh, H. Y. Mark Liao, Yolov9: Learning what you want to learn using programmable gradient information, in European Conference on Computer Vision, (2024), 1–21. https://doi.org/10.1007/978-3-031-72751-1_1 |
| [36] | A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, Yolov10: Real-time end-to-end object detection, Adv. Neural Inf. Process. Syst. , 37 (2024), 107984–108011. |
| [37] | Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, et al., DETRs beat YOLOs on real-time object detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2024), 16965–16974. https://doi.org/10.1109/CVPR52733.2024.01605 |
| [38] | D. Du, P. Zhu, L. Wen, X. Bian, H. Lin, Q. Hu, et al., VisDrone-DET2019: The vision meets drone object detection in image challenge results, in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019. |
| [39] |
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, A. Zisserman, The pascal visual object classes (voc) challenge, Int. J. Comput. Vis. , 88 (2010), 303–338. https://doi.org/10.1007/s11263-009-0275-4 doi: 10.1007/s11263-009-0275-4
|
| [40] | M. Everingham, J. Winn, The pascal visual object classes challenge 2012 (voc2012) development kit, Pattern Anal. Stat. Model. Comput. Learn., Tech. Rep. , 8 (2011), 2–5. |


Figures(10) / Tables(7)
Tong Li, Lanfang Lei, Zhong Wang, Peibei Shi, Zhize Wu. An efficient improved YOLOv10 algorithm for detecting electric bikes in elevators[J]. Electronic Research Archive, 2025, 33(6): 3673-3698. doi: 10.3934/era.2025163







 DownLoad:
DownLoad: