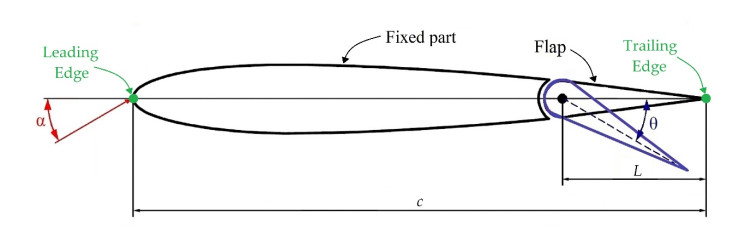
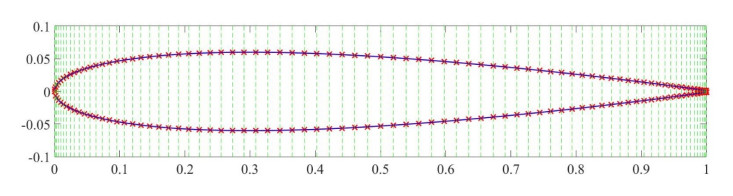
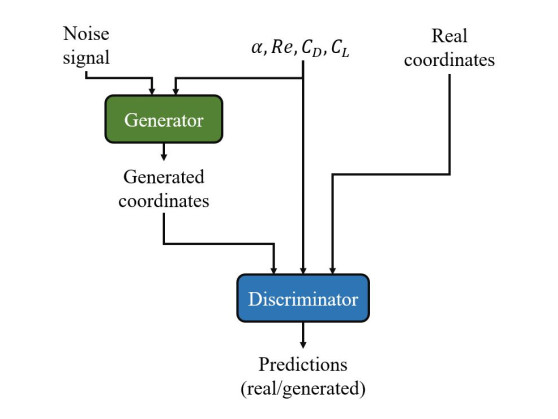
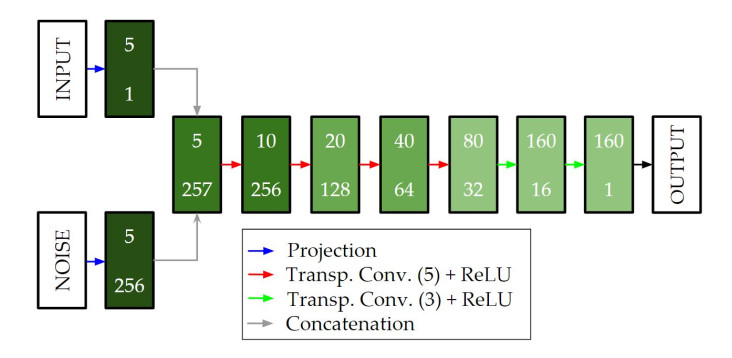
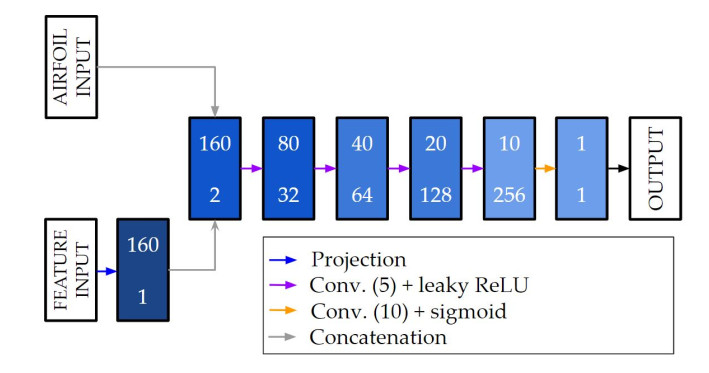
Deep learning has recently gained prominence in fluid dynamics due to advances in computational power, algorithm development, and data availability. While most applications have focused on modeling and control, its potential for design and optimization remains relatively unexplored. In this study, a conditional generative adversarial network (CGAN) was developed for inverse design of airfoils with flow control devices. This CGAN receives the characteristics of the flow (Reynolds number and angle of attack) and the desired aerodynamic characteristics (drag and lift coefficients). Based on those inputs, the CGAN generates an airfoil that fulfills the defined specifications. With this objective, numerical simulations of 4-digit NACA airfoils with variable flap configurations and flow conditions were conducted, in order to obtain the necessary aerodynamic data for training and testing the CGAN. The results demonstrate that the proposed CGAN generates airfoil geometries with high accuracy and efficiency, showing minor deviations from real geometries and achieving aerodynamic performances that approach the desired ones for all the flow conditions considered. Additionally, the model is able to generalize to extreme cases not seen during training, which significantly broadens its application range. This approach offers a significant reduction in computational time compared to traditional iterative optimization methods, making it suitable for rapid design exploration and real-time applications.
Citation: Alejandro Ballesteros-Coll, Koldo Portal-Porras, Unai Fernandez-Gamiz, Iñigo Aramendia, Daniel Teso-Fz-Betoño. Generative adversarial network for inverse design of airfoils with flow control devices[J]. Electronic Research Archive, 2025, 33(5): 3271-3284. doi: 10.3934/era.2025144
Deep learning has recently gained prominence in fluid dynamics due to advances in computational power, algorithm development, and data availability. While most applications have focused on modeling and control, its potential for design and optimization remains relatively unexplored. In this study, a conditional generative adversarial network (CGAN) was developed for inverse design of airfoils with flow control devices. This CGAN receives the characteristics of the flow (Reynolds number and angle of attack) and the desired aerodynamic characteristics (drag and lift coefficients). Based on those inputs, the CGAN generates an airfoil that fulfills the defined specifications. With this objective, numerical simulations of 4-digit NACA airfoils with variable flap configurations and flow conditions were conducted, in order to obtain the necessary aerodynamic data for training and testing the CGAN. The results demonstrate that the proposed CGAN generates airfoil geometries with high accuracy and efficiency, showing minor deviations from real geometries and achieving aerodynamic performances that approach the desired ones for all the flow conditions considered. Additionally, the model is able to generalize to extreme cases not seen during training, which significantly broadens its application range. This approach offers a significant reduction in computational time compared to traditional iterative optimization methods, making it suitable for rapid design exploration and real-time applications.

| [1] |
N. Thuerey, K. Weißenow, L. Prantl, X. Hu, Deep learning methods for Reynolds-averaged Navier–Stokes simulations of airfoil flows, AIAA J., 58 (2020), 25–36. https://doi.org/10.2514/1.J058291 doi: 10.2514/1.J058291

|
| [2] |
H. Chen, L. He, W. Qian, S. Wang, Multiple aerodynamic coefficient prediction of airfoils using a convolutional neural network, Symmetry, 12 (2020), 544. https://doi.org/10.3390/sym12040544 doi: 10.3390/sym12040544
|
| [3] | E. Yilmaz, B. German, A convolutional neural network approach to training predictors for airfoil performance, in 18th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, AIAA, 2017. https://doi.org/10.2514/6.2017-3660 |
| [4] |
K. Portal-Porras, U. Fernandez-Gamiz, E. Zulueta, A. Ballesteros-Coll, A. Zulueta, CNN-based flow control device modelling on aerodynamic airfoils, Sci. Rep., 12 (2022), 8205. https://doi.org/10.1038/s41598-022-12157-w doi: 10.1038/s41598-022-12157-w
|
| [5] |
K. Portal-Porras, U. Fernandez-Gamiz, E. Zulueta, R. Garcia-Fernandez, X. Uralde-Guinea, CNN-based vane-type vortex generator modelling, Eng. Appl. Comput. Fluid Mech., 18 (2024), 2300481. https://doi.org/10.1080/19942060.2023.2300481 doi: 10.1080/19942060.2023.2300481
|
| [6] |
S. J. Jacob, M. Mrosek, C. Othmer, H. Köstler, Deep learning for real-time aerodynamic evaluations of arbitrary vehicle shapes, SAE Int. J. Passeng. Veh. Syst., 15 (2022). https://doi.org/10.4271/15-15-02-0006 doi: 10.4271/15-15-02-0006
|
| [7] |
R. Garcia-Fernandez, K. Portal-Porras, O. Irigaray, Z. Ansa, U. Fernandez-Gamiz, CNN-based flow field prediction for bus aerodynamics analysis, Sci. Rep., 13 (2023), 21213. https://doi.org/10.1038/s41598-023-48419-4 doi: 10.1038/s41598-023-48419-4
|
| [8] |
B. Du, P. D. Lund, J. Wang, Combining CFD and artificial neural network techniques to predict the thermal performance of all-glass straight evacuated tube solar collector, Energy, 220 (2021), 119713. https://doi.org/10.1016/j.energy.2020.119713 doi: 10.1016/j.energy.2020.119713
|
| [9] |
J. Ren, H. Wang, K. Luo, J. Fan, A priori assessment of convolutional neural network and algebraic models for flame surface density of high Karlovitz premixed flames, Phys. Fluids, 33 (2021), 036111. https://doi.org/10.1063/5.0042732 doi: 10.1063/5.0042732
|
| [10] |
J. Rabault, M. Kuchta, A. Jensen, U. Réglade, N. Cerardi, Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control, J. Fluid Mech., 865 (2019), 281–302. https://doi.org/10.1017/jfm.2019.62 doi: 10.1017/jfm.2019.62
|
| [11] |
F. Ren, J. Rabault, H. Tang, Applying deep reinforcement learning to active flow control in weakly turbulent conditions, Phys. Fluids, 33 (2021), 037121. https://doi.org/10.1063/5.0037371 doi: 10.1063/5.0037371
|
| [12] |
D. Fan, L. Yang, Z. Wang, M. S. Triantafyllou, G. E. Karniadakis, Reinforcement learning for bluff body active flow control in experiments and simulations, Proc. Natl. Acad. Sci. U. S. A., 117 (2020), 26091–26098. https://doi.org/10.1073/pnas.2004939117 doi: 10.1073/pnas.2004939117
|
| [13] |
B. Z. Han, W. X. Huang, C. X. Xu, Deep reinforcement learning for active control of flow over a circular cylinder with rotational oscillations, Int. J. Heat Fluid Flow, 96 (2022), 109008. https://doi.org/10.1016/j.ijheatfluidflow.2022.109008 doi: 10.1016/j.ijheatfluidflow.2022.109008
|
| [14] |
K. Portal-Porras, U. Fernandez-Gamiz, E. Zulueta, R. Garcia-Fernandez, S. E. Berrizbeitia, Active flow control on airfoils by reinforcement learning, Ocean Eng., 287 (2023), 115775. https://doi.org/10.1016/j.oceaneng.2023.115775 doi: 10.1016/j.oceaneng.2023.115775
|
| [15] |
G. Lee, Y. Joo, S. U. Lee, T. Kim, Y. Yu, H. G. Kim, Design optimization of heat exchanger using deep reinforcement learning, Int. Commun. Heat Mass Transfer, 159 (2024), 107991. https://doi.org/10.1016/j.icheatmasstransfer.2024.107991 doi: 10.1016/j.icheatmasstransfer.2024.107991
|
| [16] |
Y. Wang, W. Wang, G. Tao, H. Li, Y. Zheng, J. Cui, Optimization of the semi-sphere vortex generator for film cooling using generative adversarial network, Int. J. Heat Mass Transfer, 183 (2022), 122026. https://doi.org/10.1016/j.ijheatmasstransfer.2021.122026 doi: 10.1016/j.ijheatmasstransfer.2021.122026
|
| [17] |
S. A. A. Mehrjardi, A. Khademi, M. Fazli, Optimization of a thermal energy storage system enhanced with fins using generative adversarial networks method, Therm. Sci. Eng. Prog., 49 (2024), 102471. https://doi.org/10.1016/j.tsep.2024.102471 doi: 10.1016/j.tsep.2024.102471
|
| [18] |
S. A. A. Mehrjardi, A. Khademi, S. M. M. Safavi, Machine learning approach to balance heat transfer and pressure loss in a dimpled tube: Generative adversarial networks in computational fluid dynamics, Therm. Sci. Eng. Prog., 57 (2025), 103116. https://doi.org/10.1016/j.tsep.2024.103116 doi: 10.1016/j.tsep.2024.103116
|
| [19] | E. Yilmaz, B. German, Conditional generative adversarial network framework for airfoil inverse design, in AIAA Aviation 2020 Forum, AIAA, 2020. https://doi.org/10.2514/6.2020-3185 |
| [20] |
V. Sekar, M. Zhang, C. Shu, B. C. Khoo, Inverse design of airfoil using a deep convolutional neural network, AIAA J., 57 (2019), 993–1003. https://doi.org/10.2514/1.J057894 doi: 10.2514/1.J057894
|
| [21] |
S. Oh, Y. Jung, S. Kim, I. Lee, N. Kang, Deep generative design: Integration of topology optimization and generative models, J. Mech. Des., 141 (2019), 111405. https://doi.org/10.1115/1.4044229 doi: 10.1115/1.4044229
|
| [22] |
D. Shu, J. Cunningham, G. Stump, S. W. Miller, M. A. Yukish, T. W. Simpson, et al., 3D design using generative adversarial networks and physics-based validation, J. Mech. Des., 142 (2019), 071701. https://doi.org/10.1115/1.4045419 doi: 10.1115/1.4045419
|
| [23] | G. Achour, W. J. Sung, O. J. Pinon-Fischer, D. N. Mavris, Development of a conditional generative adversarial network for airfoil shape optimization, in AIAA Scitech 2020 Forum, Orlando, FL, 2020. https://doi.org/10.2514/6.2020-2261 |
| [24] | W. Chen, K. Chiu, M. Fuge, Aerodynamic design optimization and shape exploration using generative adversarial networks, in AIAA Scitech 2019 Forum, San Diego, CA, 2019. https://doi.org/10.2514/6.2019-2351 |
| [25] | X. Tan, D. Manna, J. Chattoraj, L. Yong, X. Xinxing, D. M. Ha, et al., Airfoil inverse design using conditional generative adversarial networks, in 2022 17th International Conference on Control, Automation, Robotics and Vision (ICARCV), IEEE, (2022), 143–148. https://doi.org/10.1109/ICARCV57592.2022.10004343 |
| [26] |
J. Wang, R. Li, C. He, H. Chen, R. Cheng, C. Zhai, et al., An inverse design method for supercritical airfoil based on conditional generative models, Chin. J. Aeronaut., 35 (2022), 62–74. https://doi.org/10.1016/j.cja.2021.03.006 doi: 10.1016/j.cja.2021.03.006
|
| [27] | M. Drela, XFOIL: An analysis and design system for low Reynolds number airfoils, in Low Reynolds Number Aerodynamics. Lecture Notes in Engineering (eds. T. J. Mueller), Springer, Berlin, Heidelberg, 54 (1989). https://doi.org/10.1007/978-3-642-84010-4_1 |
| [28] | MATLAB, Mathworks. Available from: https://es.mathworks.com/products/matlab.html. |
| [29] | Deep Learning Toolbox, Mathworks. Available from: https://es.mathworks.com/products/deep-learning.html. |

Figures(6) / Tables(2)
Alejandro Ballesteros-Coll, Koldo Portal-Porras, Unai Fernandez-Gamiz, Iñigo Aramendia, Daniel Teso-Fz-Betoño. Generative adversarial network for inverse design of airfoils with flow control devices[J]. Electronic Research Archive, 2025, 33(5): 3271-3284. doi: 10.3934/era.2025144







 DownLoad:
DownLoad: