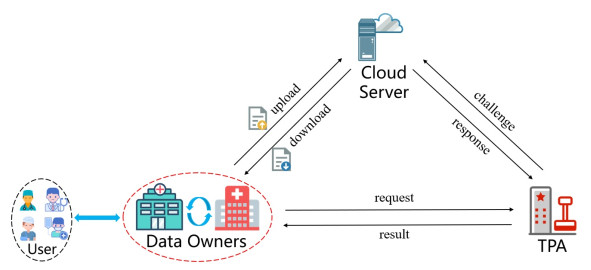
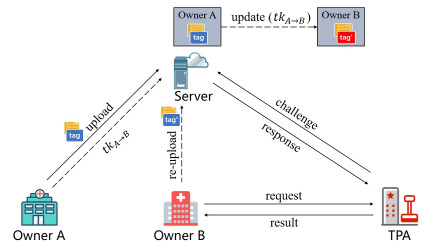
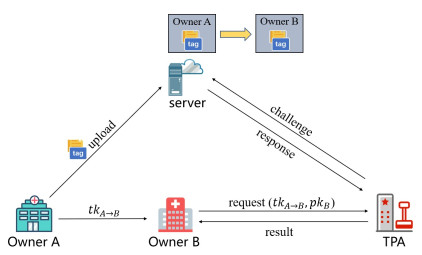
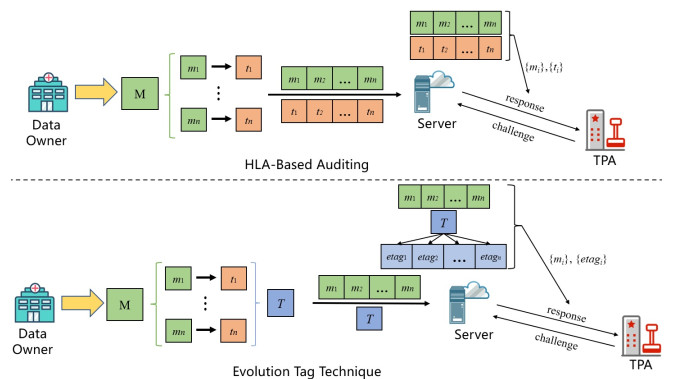
The rapid development and wide adoption of electronic healthcare systems provide huge conveniences for the users. The health records are normally outsourced to a server for centralized management. To ensure data integrity, auditing techniques are promising candidates to be applied. In practice, there is always a need to transfer data, such as when the user changes the hospital or medical center. Moreover, how to provide efficient data transfer and not bring complicated transfer process for auditing should be given attention. For traditional data transfer processes, the tags need to be recomputed or updated and then stored on the server. The scheme we proposed in this paper has the property that the tags remain the same during data transfer. This process is referred to as static transfer since the data and tags do not change. In addition, the basic construction is built upon Shacham-Waters auditing, which is the foundation of the homomorphic linear authenticator (HLA). Therefore, our scheme is compatible with other optimizations for HLA schemes, such as the evolution tag technique proposed recently to achieve a compact tag. To show the effectiveness of our scheme, we combined the evolution tag and our construction to achieve static data transfer functionality and compact tag efficiency. The improvement in our scheme preserves the underlying HLA structure and hence does not complicate the tag generation, challenge, and response phases while achieving static data transfer.
Citation: Ge Wu, Longlong Cao, Hua Shen, Liquan Chen, Xitong Tan, Jinguang Han. Cloud auditing for outsourced storage service in healthcare systems with static data transfer[J]. Electronic Research Archive, 2025, 33(4): 2577-2600. doi: 10.3934/era.2025115
The rapid development and wide adoption of electronic healthcare systems provide huge conveniences for the users. The health records are normally outsourced to a server for centralized management. To ensure data integrity, auditing techniques are promising candidates to be applied. In practice, there is always a need to transfer data, such as when the user changes the hospital or medical center. Moreover, how to provide efficient data transfer and not bring complicated transfer process for auditing should be given attention. For traditional data transfer processes, the tags need to be recomputed or updated and then stored on the server. The scheme we proposed in this paper has the property that the tags remain the same during data transfer. This process is referred to as static transfer since the data and tags do not change. In addition, the basic construction is built upon Shacham-Waters auditing, which is the foundation of the homomorphic linear authenticator (HLA). Therefore, our scheme is compatible with other optimizations for HLA schemes, such as the evolution tag technique proposed recently to achieve a compact tag. To show the effectiveness of our scheme, we combined the evolution tag and our construction to achieve static data transfer functionality and compact tag efficiency. The improvement in our scheme preserves the underlying HLA structure and hence does not complicate the tag generation, challenge, and response phases while achieving static data transfer.

| [1] |
G. Andrews, N. Titov, Treating people you never see: Internet-based treatment of the internalising mental disorders, Aust. Health Rev., 34 (2010), 144–147. https://doi.org/10.1071/ah09775 doi: 10.1071/ah09775

|
| [2] |
P. Musiat, P. Goldstone, N. Tarrier, Understanding the acceptability of e-mental health-attitudes and expectations towards computerised self-help treatments for mental health problems, BMC psychiatry, 14 (2014), 1–8. https://doi.org/10.1186/1471-244x-14-109 doi: 10.1186/1471-244x-14-109
|
| [3] | S. Padmanaban, M. Zand, M. A. Nasab, M. Shahbazi, H. Nourizadeh, Smart and Power Grid Systems–Design Challenges and Paradigms, 1$^{st}$ edition, River Publishers, New York, 2022. https://doi.org/10.1201/9781003339557 |
| [4] | M. Blaze, G. Bleumer, M. Strauss, Divertible protocols and atomic proxy cryptography, in Advances in Cryptology-EUROCRYPT'98, Springer, (1998), 127–144. https://doi.org/10.1007/BFb0054122 |
| [5] | J. Shen, F. Guo, X. Chen, W. Susilo, Secure cloud auditing with efficient ownership transfer, in Computer Security–ESORICS 2020, Springer, (2020), 611–631. https://doi.org/10.1007/978-3-030-58951-6_30 |
| [6] |
J. Shen, X. Chen, J. Wei, F. Guo, W. Susilo, Blockchain-based accountable auditing with multi-ownership transfer, IEEE Trans. Cloud Comput., 11 (2023), 2711–2724. https://doi.org/10.1109/TCC.2022.3224440 doi: 10.1109/TCC.2022.3224440
|
| [7] |
Y. Wang, W. You, Y. Zhang, A. Ye, L. Xu, Cloud EMRs auditing with decentralized (t, n)-threshold ownership transfer, Cybersecurity, 7 (2024), 53. https://doi.org/10.1186/s42400-024-00246-4 doi: 10.1186/s42400-024-00246-4
|
| [8] |
Y. Huang, W. Shen, J. Qin, Certificateless cloud storage auditing supporting data ownership transfer, Comput. Secur., 139 (2024), 103738. https://doi.org/10.1016/j.cose.2024.103738 doi: 10.1016/j.cose.2024.103738
|
| [9] | W. T. Liew, K. Tsai, J. Luo, M. Yang, Novel designated ownership transfer with grouping proof, in IEEE Conference on Dependable and Secure Computing–DSC 2017, (2017), 433–440. https://doi.org/10.1109/DESEC.2017.8073863 |
| [10] |
S. F. Aghili, H. Mala, M. Shojafar, P. Peris-Lopez, LACO: Lightweight three-factor authentication, access control and ownership transfer scheme for E-Health systems in IoT, Future Gener. Comput. Syst., 96 (2019), 410–424. https://doi.org/10.1016/j.future.2019.02.020 doi: 10.1016/j.future.2019.02.020
|
| [11] |
R. Kumar, R. Tripathi, Data provenance and access control rules for ownership transfer using blockchain, Int. J. Inf. Secur. Privacy, 15 (2021), 87–112. https://doi.org/10.4018/IJISP.2021040105 doi: 10.4018/IJISP.2021040105
|
| [12] | M. Badakhshan, G. Gong, Privacy-preserving ownership transfer: Challenges and an outlined solution based on zero-knowledge proofs, in 9th IEEE World Forum on Internet of Things - WF-IoT 2023, (2023), 1–9. https://doi.org/10.1109/WF-IoT58464.2023.10539396 |
| [13] |
M. Kiran, B. Ray, J. Hassan, A. Kashyap, V. Y. Chandrappa, Blockchain based secure ownership transfer protocol for smart objects in the internet of things, Internet Things, 25 (2024), 101002. https://doi.org/10.1016/j.iot.2023.101002 doi: 10.1016/j.iot.2023.101002
|
| [14] | G. Ateniese, R. C. Burns, R. Curtmola, J. Herring, L. Kissner, Z. N. J. Peterson, et al., Provable data possession at untrusted stores, in Proceedings of the 2007 ACM Conference on Computer and Communications Security, (2007), 598–609. https://doi.org/10.1145/1315245.1315318 |
| [15] | A. Juels, B. S. Kaliski, Pors: Proofs of retrievability for large files, in Proceedings of the 2007 ACM Conference on Computer and Communications Security, (2007), 584–597. https://doi.org/10.1145/1315245.1315317 |
| [16] | H. Shacham, B. Waters, Compact proofs of retrievability, in Advances in Cryptology - ASIACRYPT 2008, Springer, (2008), 90–107. https://doi.org/10.1007/978-3-540-89255-7_7 |
| [17] | F. Armknecht, J. Bohli, G. O. Karame, Z. Liu, C. A. Reuter, Outsourced proofs of retrievability, in Proceedings of the 2014 ACM Conference on Computer and Communications Security - CCS 2014, (2014), 831–843. https://doi.org/10.1145/2660267.2660310 |
| [18] | G. Ateniese, R. D. Pietro, L. V. Mancini, G. Tsudik, Scalable and efficient provable data possession, in 4th International ICST Conference on Security and Privacy in Communication Networks, (2008), 1–10. https://doi.org/10.1145/1460877.1460889 |
| [19] | K. D. Bowers, A. Juels, A. Oprea, Proofs of retrievability: Theory and implementation, in Proceedings of the 1st ACM Cloud Computing Security Workshop, (2009), 43–54. https://doi.org/10.1145/1655008.1655015 |
| [20] | R. Curtmola, O. Khan, R. C. Burns, G. Ateniese, MR-PDP: Multiple-replica provable data possession, in 28th IEEE International Conference on Distributed Computing Systems, (2008), 411–420. https://doi.org/10.1109/ICDCS.2008.68 |
| [21] | D. Cash, A. Küpçü, D. Wichs, Dynamic proofs of retrievability via oblivious RAM, in Advances in Cryptology - EUROCRYPT 2013, Springer, (2013), 279–295. https://doi.org/10.1007/978-3-642-38348-9_17 |
| [22] |
Y. Yu, M. H. Au, G. Ateniese, X. Huang, W. Susilo, Y. Dai, et al., Identity-based remote data integrity checking with perfect data privacy preserving for cloud storage, IEEE Trans. Inf. Forensics Secur., 12 (2017), 767–778. https://doi.org/10.1109/TIFS.2016.2615853 doi: 10.1109/TIFS.2016.2615853
|
| [23] |
K. Yang, X. Jia, An efficient and secure dynamic auditing protocol for data storage in cloud computing, IEEE Trans. Parallel Distributed Syst., 24 (2013), 1717–1726. https://doi.org/10.1109/TPDS.2012.278 doi: 10.1109/TPDS.2012.278
|
| [24] | J. Yuan, S. Yu, Proofs of retrievability with public verifiability and constant communication cost in cloud, in Proceedings of the 2013 International Workshop on Security in Cloud Computing, (2013), 19–26. https://doi.org/10.1145/2484402.2484408 |
| [25] |
J. Yuan, S. Yu, Pcpor: Public and constant-cost proofs of retrievability in cloud, J. Comput. Secur., 23 (2015), 403–425. https://doi.org/10.3233/JCS-150525 doi: 10.3233/JCS-150525
|
| [26] | C. C. Erway, A. Küpçü, C. Papamanthou, R. Tamassia, Dynamic provable data possession, in Proceedings of the 2009 ACM Conference on Computer and Communications Security, (2009), 213–222. https://doi.org/10.1145/269990 |
| [27] |
D. Cash, A. Küpçü, D. Wichs, Dynamic proofs of retrievability via oblivious RAM, J. Cryptology, 30 (2017), 22–57. https://doi.org/10.1007/s00145-015-9216-2 doi: 10.1007/s00145-015-9216-2
|
| [28] |
C. C. Erway, A. Küpçü, C. Papamanthou, R. Tamassia, Dynamic provable data possession, ACM Trans. Inf. Syst. Secur., 17 (2015), 1–29. https://doi.org/10.1145/2699909 doi: 10.1145/2699909
|
| [29] | E. Stefanov, M. van Dijk, A. Juels, A. Oprea, Iris: A scalable cloud file system with efficient integrity checks, in 28th Annual Computer Security Applications Conference, (2012), 229–238. https://doi.org/10.1145/2420950.2420985 |
| [30] | F. Armknecht, L. Barman, J. Bohli, G. O. Karame, Mirror: Enabling proofs of data replication and retrievability in the cloud, in 25th USENIX Security Symposium-USENIX 2016, (2016), 1051–1068. |
| [31] |
W. Shen, J. Qin, J. Yu, R. Hao, J. Hu, Enabling identity-based integrity auditing and data sharing with sensitive information hiding for secure cloud storage, IEEE Trans. Inf. Forensics Secur., 14 (2019), 331–346. https://doi.org/10.1109/TIFS.2018.2850312 doi: 10.1109/TIFS.2018.2850312
|
| [32] |
Y. Wang, Q. Wu, B. Qin, W. Shi, R. H. Deng, J. Hu, Identity-based data outsourcing with comprehensive auditing in clouds, IEEE Trans. Inf. Forensics Secur., 12 (2017), 940–952. https://doi.org/10.1109/TIFS.2016.2646913 doi: 10.1109/TIFS.2016.2646913
|
| [33] |
Y. Yu, L. Xue, M. H. Au, W. Susilo, J. Ni, Y. Zhang, et al., Cloud data integrity checking with an identity-based auditing mechanism from RSA, Future Gener. Comput. Syst., 62 (2016), 85–91. https://doi.org/10.1016/j.future.2016.02.003 doi: 10.1016/j.future.2016.02.003
|
| [34] |
Y. Li, Y. Yu, G. Min, W. Susilo, J. Ni, K. R. Choo, Fuzzy identity-based data integrity auditing for reliable cloud storage systems, IEEE Trans. Dependable Secure Comput., 16 (2019), 72–83. https://doi.org/10.1109/TDSC.2017.2662216 doi: 10.1109/TDSC.2017.2662216
|
| [35] |
J. R. Gudeme, S. K. Pasupuleti, R. Kandukuri, Attribute-based public integrity auditing for shared data with efficient user revocation in cloud storage, J. Ambient Intell. Hum. Comput., 12 (2021), 2019–2032. https://doi.org/10.1007/s12652-020-02302-6 doi: 10.1007/s12652-020-02302-6
|
| [36] |
Y. Yu, Y. Li, B. Yang, W. Susilo, G. Yang, J. Bai, Attribute-based cloud data integrity auditing for secure outsourced storage, IEEE Trans. Emerging Top. Comput., 8 (2020), 377–390. https://doi.org/10.1109/TETC.2017.2759329 doi: 10.1109/TETC.2017.2759329
|
| [37] | S. Shen, W. Tzeng, Delegable provable data possession for remote data in the clouds, in Information and Communications Security, Springer, (2011), 93–111. https://doi.org/10.1007/978-3-642-25243-3_8 |
| [38] | J. Xu, A. Yang, J. Zhou, D. S. Wong, Lightweight delegatable proofs of storage, in Computer Security-ESORICS 2016, Springer, (2016), 324–343. https://doi.org/10.1007/978-3-319-45744-4_16 |
| [39] |
A. Yang, J. Xu, J. Weng, J. Zhou, D. S. Wong, Lightweight and privacy-preserving delegatable proofs of storage with data dynamics in cloud storage, IEEE Trans. Cloud Comput., 9 (2021), 212–225. https://doi.org/10.1109/TCC.2018.2851256 doi: 10.1109/TCC.2018.2851256
|
| [40] |
H. Li, L. Liu, C. Lan, C. Wang, H. Guo, Lattice-based privacy-preserving and forward-secure cloud storage public auditing scheme, IEEE Access, 8 (2020), 86797–86809. https://doi.org/10.1109/ACCESS.2020.2991579 doi: 10.1109/ACCESS.2020.2991579
|
| [41] | Z. Liu, Y. Liao, X. Yang, Y. He, K. Zhao, Identity-based remote data integrity checking of cloud storage from lattices, in 3rd International Conference on Big Data Computing and Communications - BIGCOM 2017, (2017), 128–135. https://doi.org/10.1109/BIGCOM.2017.29 |
| [42] | Y. Zhang, Y. Sang, Z. Xi, H. Zhong, Lattice based multi-replica remote data integrity checking for data storage on cloud, in Parallel Architectures, Algorithms and Programming, Springer, (2019), 440–451. https://doi.org/10.1007/978-981-15-2767-8_39 |
| [43] | W. Susilo, Y. Li, F. Guo, J. Lai, G. Wu, Public cloud data auditing revisited: Removing the tradeoff between proof size and storage cost, in Computer Security - ESORICS 2022, Springer, (2022), 65–85. https://doi.org/10.1007/978-3-031-17146-8_4 |
| [44] | D. Boneh, X. Boyen, E. Goh, Hierarchical identity based encryption with constant size ciphertext, in Advances in Cryptology-EUROCRYPT 2005, Springer, (2005), 440–456. https://doi.org/10.1007/11426639_26 |
| [45] |
H. Yan, W. Gui, Efficient identity-based public integrity auditing of shared data in cloud storage with user privacy preserving, IEEE Access, 9 (2021), 45822–45831. https://doi.org/10.1109/ACCESS.2021.3066497 doi: 10.1109/ACCESS.2021.3066497
|
| [46] |
B. Wang, B. Li, H. Li, Panda: Public auditing for shared data with efficient user revocation in the cloud, IEEE Trans. Serv. Comput., 8 (2015), 92–106. https://doi.org/10.1109/TSC.2013.2295611 doi: 10.1109/TSC.2013.2295611
|
Figures(9) / Tables(4)
Ge Wu, Longlong Cao, Hua Shen, Liquan Chen, Xitong Tan, Jinguang Han. Cloud auditing for outsourced storage service in healthcare systems with static data transfer[J]. Electronic Research Archive, 2025, 33(4): 2577-2600. doi: 10.3934/era.2025115







 DownLoad:
DownLoad: