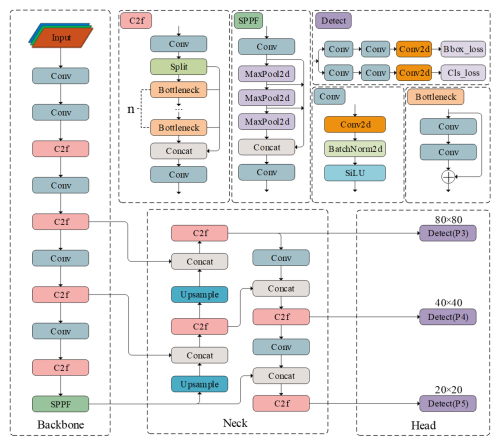
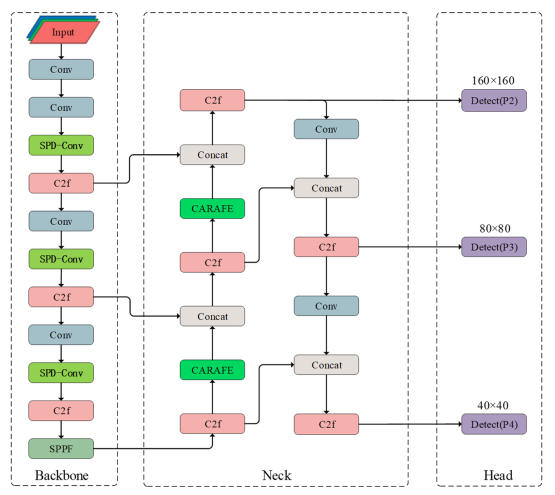
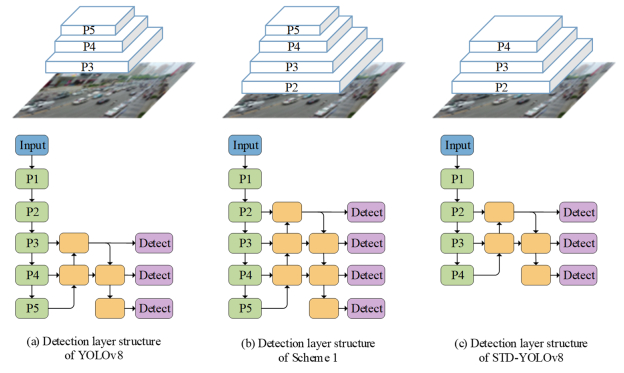
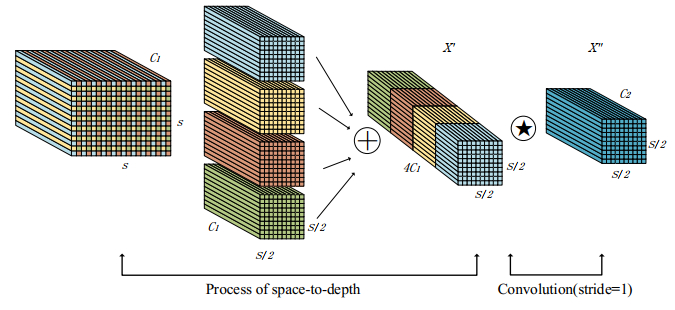
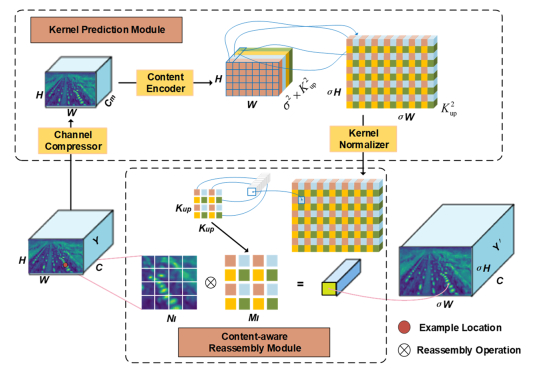
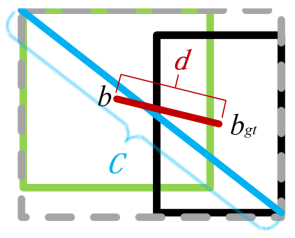
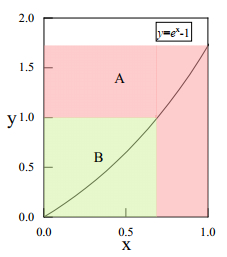
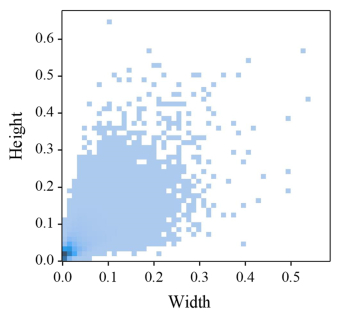
When recognizing targets by unmanned aerial vehicles (UAVs), problems such as small size, dense dispersion, and complex background are likely to occur, resulting in low recognition rates. In order to solve the above problems, this work proposed a lightweight small target detection algorithm based on the YOLOv8n: STD-YOLOv8 algorithm. First, the regression problem of small targets in different training periods was optimized, the penalty term in the original loss was improved, and a new LIoU loss function was proposed, so that the size of the penalty term could be dynamically adjusted before and after training, thus improving the performance of the algorithm. Second, in order to better adapt to the small target scale and enhance the ability of small target feature acquisition, the SPD-Conv module was integrated in the backbone network, replacing the original stepwise convolutional layer and pooling layer, so as to solve the problems of loss of fine-grained information and low efficiency of feature representation existing in the current convolutional neural network (CNN) structure. In the neck part, nearest-neighbor upsampling was replaced by the feature reassembly assembly of features operator CARAFE (content-aware reassembly of features), which enabled the model to aggregate contextual information in a larger perceptual field and enhanced the feature representation in the neck. Finally, validation experiments were conducted by comparing different algorithms under the same VisDrone-2021 dataset. The results of the ablation experiments show that the algorithms proposed in this thesis have improved the recall (R), mAP50, and mAP95 by 4.7, 5.8 and 5.7%, respectively, compared with YOLOv8n. The results of the model generalization experiments on the TinyPerson dataset show that the algorithm in this paper has superior small target detection performance with only 1.2 M model parameters (1 M = 106).
Citation: Dong Wu, Jiechang Li, Weijiang Yang. STD-YOLOv8: A lightweight small target detection algorithm for UAV perspectives[J]. Electronic Research Archive, 2024, 32(7): 4563-4580. doi: 10.3934/era.2024207
When recognizing targets by unmanned aerial vehicles (UAVs), problems such as small size, dense dispersion, and complex background are likely to occur, resulting in low recognition rates. In order to solve the above problems, this work proposed a lightweight small target detection algorithm based on the YOLOv8n: STD-YOLOv8 algorithm. First, the regression problem of small targets in different training periods was optimized, the penalty term in the original loss was improved, and a new LIoU loss function was proposed, so that the size of the penalty term could be dynamically adjusted before and after training, thus improving the performance of the algorithm. Second, in order to better adapt to the small target scale and enhance the ability of small target feature acquisition, the SPD-Conv module was integrated in the backbone network, replacing the original stepwise convolutional layer and pooling layer, so as to solve the problems of loss of fine-grained information and low efficiency of feature representation existing in the current convolutional neural network (CNN) structure. In the neck part, nearest-neighbor upsampling was replaced by the feature reassembly assembly of features operator CARAFE (content-aware reassembly of features), which enabled the model to aggregate contextual information in a larger perceptual field and enhanced the feature representation in the neck. Finally, validation experiments were conducted by comparing different algorithms under the same VisDrone-2021 dataset. The results of the ablation experiments show that the algorithms proposed in this thesis have improved the recall (R), mAP50, and mAP95 by 4.7, 5.8 and 5.7%, respectively, compared with YOLOv8n. The results of the model generalization experiments on the TinyPerson dataset show that the algorithm in this paper has superior small target detection performance with only 1.2 M model parameters (1 M = 106).

| [1] |
Z. Bi, L. Jing, C. Sun, M. Shan, YOLOX++ for transmission line abnormal target detection, IEEE Access, 11 (2023), 38157–38167. https://doi.org/10.1109/ACCESS.2023.3268106 doi: 10.1109/ACCESS.2023.3268106

|
| [2] | R. Li, Y. Chen, C. Sun, W. Fu, Improved algorithm for small target detection of traffic signs on YOLOv5s, in 2023 4th International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), (2023), 339–344. https://doi.org/10.1109/ICHCI58871.2023.10278065 |
| [3] | F. A. Kurniadi, C. Setianingsih, R. E. Syaputra, Innovation in livestock surveillance: Applying the YOLO algorithm to UAV imagery and videography, in 2023 IEEE 9th International Conference on Smart Instrumentation, Measurement and Applications (ICSIMA), (2023), 246–251. https://doi.org/10.1109/ICSIMA59853.2023.10373473 |
| [4] |
H. Y. Jiang, F. Hu, X. Q. Fu, C. R. Chen, C. Wang, L. X. Tian, et al., YOLOv8-Peas: a lightweight drought tolerance method for peas based on seed germination vigor, Front. Plant Sci., 14 (2023). https://doi.org/10.3389/fpls.2023.1257947 doi: 10.3389/fpls.2023.1257947
|
| [5] | R. Girshick, Fast R-CNN, in 2015 IEEE International Conference on Computer Vision (ICCV), (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [6] | R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in 2014 IEEE Conference on Computer Vision and Pattern Recognition, (2014), 580–587. https://doi.org/10.1109/CVPR.2014.81 |
| [7] | K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask R-CNN, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 2980–2988. https://doi.org/10.1109/ICCV.2017.322 |
| [8] |
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, in IEEE Transactions on Pattern Analysis and Machine Intelligence, 39 (2017), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 doi: 10.1109/TPAMI.2016.2577031
|
| [9] | J. Bai, H. Zhang, Z. Li, The generalized detection method for the dim small targets by faster R-CNN integrated with GAN, in 2018 IEEE 3rd International Conference on Communication and Information Systems (ICCIS), (2018), 1–5. https://doi.org/10.1109/ICOMIS.2018.8644960 |
| [10] | Z. Wang, Y. Cao, J. Li, A detection algorithm based on improved faster R-CNN for spacecraft components, in 2023 IEEE International Conference on Image Processing and Computer Applications (ICIPCA), (2023), 1–5. https://doi.org/10.1109/ICIPCA59209.2023.10257992 |
| [11] |
Z. H. He, X. Ye, Y. Li, Compact sparse R-CNN: Speeding up sparse R-CNN by reducing iterative detection heads and simplifying feature pyramid network, AIP Adv., 13 (2023). https://doi.org/10.1063/5.0146453 doi: 10.1063/5.0146453
|
| [12] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You Only look once: Unified, real-time object detection, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [13] | J. Redmon, A. Farhadi, YOLO9000: Better, faster, stronger, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 6517–6525. https://doi.org/10.1109/CVPR.2017.690 |
| [14] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, preprint, arXiv: 1804.02767. https://doi.org/10.48550/arXiv.1804.02767 |
| [15] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, YOLOv4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. https://doi.org/10.48550/arXiv.2004.10934 |
| [16] | X. Zhu, S. Lyu, X. Wang, Q. Zhao, TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios, in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), (2021), 2778–2788. https://doi.org/10.1109/ICCVW54120.2021.00312 |
| [17] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Y. Fu, et al., SSD: Single shot multibox detector, in Computer Vision–ECCV 2016. ECCV 2016. Lecture Notes in Computer Science(), Springer, 9905 (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [18] |
T. Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, IEEE Trans. Pattern Anal. Mach. Intell., 42 (2020), 318–327. https://doi.org/10.1109/TPAMI.2018.2858826 doi: 10.1109/TPAMI.2018.2858826
|
| [19] | Z. Yao, W. Douglas, S. O'Keeffe, R. Villing, Faster YOLO-LITE: Faster object detection on robot and edge devices, in RoboCup 2021: Robot World Cup XXIV, Springer, 13132 (2021), 226–237. https://doi.org/10.1007/978-3-030-98682-7_19 |
| [20] |
C. Sun, Y. B. Ai, S. Wang, W. D. Zhang, Mask-guided SSD for small-object detection, Appl. Intell., 51 (2021), 3311–3322. https://doi.org/10.1007/s10489-020-01949-0 doi: 10.1007/s10489-020-01949-0
|
| [21] |
H. Wang, H. Qian, S. Feng, GAN-STD: small target detection based on generative adversarial network, J. Real-Time Image Process., 21 (2024), 65. https://doi.org/10.1007/s11554-024-01446-4 doi: 10.1007/s11554-024-01446-4
|
| [22] | C. Chen, M. Y. Liu, O. Tuzel, J. Xiao, R-CNN for small object detection, in Computer Vision—ACCV 2016, Springer, 10115 (2017), 214–230. https://doi.org/10.1007/978-3-319-54193-8_14 |
| [23] | X. Chen, H. Fang, T. Y. Lin, R. Vedantam, S. Gupta, P. Dollár, et al., Microsoft COCO captions: Data collection and evaluation server, preprint, arXiv: 1504.00325. https://doi.org/10.48550/arXiv.1504.00325 |
| [24] | G. S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, et al., DOTA: A large-scale dataset for object detection in aerial images, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 3974–3983. https://doi.org/10.1109/CVPR.2018.00418 |
| [25] | S. Zhang, R. Benenson, B. Schiele, CityPersons: A diverse dataset for pedestrian detection, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 4457–4465. https://doi.org/10.1109/CVPR.2017.474 |
| [26] | J. Wang, K. Chen, R. Xu, Z. Liu, C. C. Loy, D. Lin, CARAFE: Content-aware reassembly of features, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 3007–3016. https://doi.org/10.1109/ICCV.2019.00310 |
| [27] | R. Sunkara, T. Luo, No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects, in Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2022, Cham: Springer Nature Switzerland, 13715 (2022), 443–459. https://doi.org/10.1007/978-3-031-26409-2_27 |
| [28] | H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, S. Savarese, Generalized intersection over union: A metric and a loss for bounding box regression, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 658–666. https://doi.org/10.1109/CVPR.2019.00075 |
| [29] | Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, D. Ren, Distance-IoU loss: Faster and better learning for bounding box regression, in AAAI Conference on Artificial Intelligence, (2019). https://doi.org/10.48550/arXiv.1911.08287 |
| [30] | Y. Cao, Z. He, L. Wang, W. Wang, Y. Yuan, D. Zhang, et al., VisDrone-DET2021: The vision meets drone object detection challenge results, in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), (2021), 2847–2854. https://doi.org/10.1109/ICCVW54120.2021.00319 |
| [31] |
C. Liu, D. G. Yang, L. Tang, X. Zhou, Y. Deng, A lightweight object detector based on spatial-coordinate self-attention for UAV aerial images, Remote Sens., 15 (2022), 83. https://doi.org/10.3390/rs15010083 doi: 10.3390/rs15010083
|
| [32] |
H. J. Nie, H. L. Pang, M. Y. Ma, R. K. Zheng, A lightweight remote sensing small target image detection algorithm based on improved YOLOv8, Sensors, 24 (2024), 2952. https://doi.org/10.3390/s24092952 doi: 10.3390/s24092952
|



Figures(12) / Tables(5)
Dong Wu, Jiechang Li, Weijiang Yang. STD-YOLOv8: A lightweight small target detection algorithm for UAV perspectives[J]. Electronic Research Archive, 2024, 32(7): 4563-4580. doi: 10.3934/era.2024207







 DownLoad:
DownLoad: