Citation: Ling Li, Dan He, Cheng Zhang. An image filtering method for dataset production[J]. Electronic Research Archive, 2024, 32(6): 4164-4180. doi: 10.3934/era.2024187

| [1] | J. Deng, W. Dong, R. Socher, L. J. Li, K. Li, F. F. Li, Imagenet: A large-scale hierarchical image database, in IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, (2009), 248–255. https://doi.org/10.1109/CVPR.2009.5206848 |
| [2] |
A. Krizhevsky, I. Sutskever, G. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386

|
| [3] |
A. V. Emchinov, V. V. Ryazanov, Research and development of deep learning algorithms for the classification of pneumonia type and detection of ground-glass loci on radiological images, Pattern Recognit. Image Anal., 32 (2022), 707–716. https://doi.org/10.1134/S1054661822030105 doi: 10.1134/S1054661822030105
|
| [4] | H. Tang, Research progress and development of deep learning based on convolutional neural network, in 2021 2nd International Conference on Computing and Data Science (CDS), Stanford, CA, USA, (2021), 259–264. https://doi.org/10.1109/CDS52072.2021.00052 |
| [5] |
H. Luo, J. Luo, R. Li, M. Yu, Optimization algorithm design of laser marking contour extraction and graphics hatching based on image processing technology, J. Phys. Conf. Ser., 2173 (2022), 012078. https://doi.org/10.1088/1742-6596/2173/1/012078 doi: 10.1088/1742-6596/2173/1/012078
|
| [6] |
L. Zhang, Y. P. Sui, H. S. Wang, S. K. Hao, N. B. Zhang, Image feature extraction and recognition model construction of coal and gangue based on image processing technology, Sci. Rep., 12 (2022), 20983. https://doi.org/10.1038/s41598-022-25496-5 doi: 10.1038/s41598-022-25496-5
|
| [7] | X. L. Chen, H. Fang, T. Y. Lin, R. Vedantam, S. Gupta, P. Dollar, et al., Microsoft COCO captions: Data collection and evaluation server, preprint, arXiv: 1504.00325. https://doi.org/10.48550/arXiv.1504.00325 |
| [8] | O. M. Parkhi, A. Vedaldi, A. Zisserman, Deep face recognition, in BMVC 2015 - Proceedings of the British Machine Vision Conference 2015, Swansea, UK, (2015), 1–12. |
| [9] |
B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, T, Antonio, Places: A 10 million image database for scene recognition, IEEE Trans. Pattern Anal. Mach. Intell., 40 (2018), 1452–1464. https://doi.org/10.1109/TPAMI.2017.2723009 doi: 10.1109/TPAMI.2017.2723009
|
| [10] |
M. Kumar, A. Bindal, R. Gautam, R. Bhatia, Keyword query based focused Web crawler, Procedia Comput. Sci., 125 (2018), 584–590. https://doi.org/10.1016/j.procs.2017.12.075 doi: 10.1016/j.procs.2017.12.075
|
| [11] |
G. Lin, Y. Liang, A. Tavares, Design of an energy supply and demand forecasting system based on web crawler and a grey dynamic model, Energies, 16 (2023), 1431. https://doi.org/10.3390/en16031431 doi: 10.3390/en16031431
|
| [12] | Q. C. Deng, K. Cheng, Collection and semi-automatic labeling of custom target detection dataset (in Chinese), Soft. Guide, 21 (2022), 116–122. |
| [13] |
M. Z. Hua, L. M. Wang, J. W. Jiang, Construction of large-scale coral dataset based on web resources (in Chinese), J. North. Nor. Univer., 55 (2023), 72–79. https://doi.org/10.16163/j.cnki.dslkxb202209230003 doi: 10.16163/j.cnki.dslkxb202209230003
|
| [14] |
M. J. Shenza, The discrete wavelet transform: wedding the a trous and mallat algorithms, IEEE Trans. Signal Process., 40 (1992), 2464–2482. https://doi.org/10.1109/78.157290 doi: 10.1109/78.157290
|
| [15] |
H. Y. Chen, H. Y. Long, Y. J. Song, H. L. Chen, X. B. Zhou, W. Deng, M3FuNet: An unsupervised multivariate feature fusion network for hyperspectral image classification, IEEE Trans. Geosci. Remote. Sens., 62 (2024), 1–15. https://doi.org/10.1109/TGRS.2024.3380087 doi: 10.1109/TGRS.2024.3380087
|
| [16] |
L. Pinjarkar, M. Sharma, S. Selot, Deep CNN combined with relevance feedback for trademark image retrieval, J. Intell. Syst., 29 (2020), 894–909. https://doi.org/10.1515/jisys-2018-0083 doi: 10.1515/jisys-2018-0083
|
| [17] |
Z. Zeng, S. Sun, J. Sun, J. Yin, Y. Shen, Constructing a mobile visual search framework for Dunhuang murals based on fine-tuned CNN and ontology semantic distance, Electron. Lib., 40 (2022), 121–139. https://doi.org/10.1108/EL-09-2021-0173 doi: 10.1108/EL-09-2021-0173
|
| [18] |
T. Rajasenbagam, S. Jeyanthi, Semantic content-based image retrieval system using deep learning model for lung cancer CT images, J. Med. Imaging Health Inf., 11 (2021), 2675–2682. https://doi.org/10.1166/jmihi.2021.3859 doi: 10.1166/jmihi.2021.3859
|
| [19] |
M. A. Aljanabi, Z. M. Hussain, S. F. Lu, An entropy-histogram approach for image similarity and face recognition, Math. Probl. Eng., 2018 (2018), 1–18. https://doi.org/10.1155/2018/9801308 doi: 10.1155/2018/9801308
|
| [20] |
Y. Zhang, Y. Yao, Y. Wan, W. Liu, W. Yang, Z. Zheng, et al., Histogram of the orientation of the weighted phase descriptor for multi-modal remote sensing image matching, J. Photogramm. Remote Sens., 196 (2023), 1–15. https://doi.org/10.1016/j.isprsjprs.2022.12.018 doi: 10.1016/j.isprsjprs.2022.12.018
|
| [21] | A. Drmic, M. Silic, G. Delac, K. Vladimir, A. S. Kurdija, Evaluating robustness of perceptual image hashing algorithms, in 2017 40th International Convention on Information and Communication Technology, Electronics and Microelectronics, Opatija, Croatia, (2017), 995–1000. https://doi.org/10.23919/MIPRO.2017.7973569 |
| [22] |
D. G. Lowe, Distinctive image features from scale-invariant keypoints, Int. J. Comput. Vision, 60 (2004), 91–110. https://doi.org/10.1023/B:VISI.0000029664.99615.94 doi: 10.1023/B:VISI.0000029664.99615.94
|
| [23] | N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA, (2005), 886–893. https://doi.org/10.1109/CVPR.2005.177 |
| [24] | K. H. Sri, G. T. Manasa, G. G. Reddy, S. Bano, V. B. Trinadh, Detecting image similarity using SIFT, in Expert Clouds and Applications: Proceedings of ICOECA 2021, Singapore, 209 (2022), 561–575. https://doi.org/10.1007/978-981-16-2126-0_45 |
| [25] |
F. Naiemi, V. Ghods, H. Khalesi, An efficient character recognition method using enhanced HOG for spam image detection, Soft Comput., 23 (2019), 11759–11774. https://doi.org/10.1007/s00500-018-03728-z doi: 10.1007/s00500-018-03728-z
|
| [26] |
Y. L. Liu, G. J. Xin Y. Xiao, Robust image hashing using Radon transform and invariant features, Radioengineering, 25 (2016), 556–564. https://doi.org/10.13164/re.2016.0556 doi: 10.13164/re.2016.0556
|
| [27] | N. Hussein, M. Ali, M. E. Mahdi, Detecting similarity in color images based on perceptual image hash algorithm, in IOP Conference Series: Materials Science and Engineering, Istanbul, Turkey, 737 (2020), 012244. https://doi.org/10.1088/1757-899X/737/1/012244 |
| [28] |
M. Hori, T. Hori, Y. Ohno, S. Tsuruta, H. Iwase, T. Kawai, A novel identification method using perceptual degree of concordance of occlusal surfaces calculated by a Python program, Forensic Sci. Int., 313 (2020), 110358. https://doi.org/10.1016/j.forsciint.2020.110358 doi: 10.1016/j.forsciint.2020.110358
|
| [29] |
M. Fei, J. Li, H. Liu, Visual tracking based on improved foreground detection and perceptual hashing, Neucomputing, 152 (2015), 413–428. https://doi.org/10.1016/j.neucom.2014.09.060 doi: 10.1016/j.neucom.2014.09.060
|
| [30] |
D. M. Mo, W. K. Wong, X. J. Liu, Y. Ge, Concentrated hashing with neighborhood embedding for image retrieval and classification, Int. J. Mach. Learn. Cybern., 13 (2022), 1571–1587. https://doi.org/10.1007/s13042-021-01466-7 doi: 10.1007/s13042-021-01466-7
|
| [31] | A. Jose, D. Filbert, C. Rohlfing, J. R. Ohm, Deep hashing with hash center update for efficient image retrieval, in ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, (2022), 4773–4777. https://doi.org/10.1109/ICASSP43922.2022.9746805 |
| [32] |
W. J. Yang, L. J. Wang, S. L. Cheng, Y. M. Li, A. Y. Du, Deep hash with improved dual attention for image retrieval, Information, 12 (2021), 285. https://doi.org/10.3390/info12070285 doi: 10.3390/info12070285
|
| [33] |
C. Tian, M. Zheng, W. Zuo, B. Zhang, Y. Zhang, D. Zhang, Multi-stage image denoising with the wavelet transform, Pattern Recognit., 134 (2023), 109050. https://doi.org/10.1016/j.patcog.2022.109050 doi: 10.1016/j.patcog.2022.109050
|
| [34] | J. Bhardwaj, A. Nayak, Haar wavelet transform-based optimal bayesian method for medical image fusion, Med. Biol. Eng. Comput., 58 (2020), 2397–2411. https://link.springer.com/article/10.1007/s11517-020-02209-6 |
| [35] |
R. Ranjan, P. Kumar, An improved image compression algorithm using 2D dwt and pca with canonical huffman encoding, Entropy, 25 (2023), 1382. https://doi.org/10.3390/e25101382 doi: 10.3390/e25101382
|
| [36] |
G. Strang, The discrete cosine transform, SIAM Rev., 41 (1998), 135–147. https://doi.org/10.1137/S0036144598336745 doi: 10.1137/S0036144598336745
|
| [37] |
M. Norouzi, A. Punjani, D. J. Fleet, Fast exact search in hamming space with multi-index hashing, IEEE Trans. Pattern Anal. Mach. Intell., 6 (2014), 1107–1119. https://doi.org/10.1109/TPAMI.2013.231 doi: 10.1109/TPAMI.2013.231
|
| [38] |
H. W. Zhang, Y. B. Dong, J. Li, D. Q. Xu, An efficient method for time series similarity search using binary code representation and hamming distance, Intell. Data Anal., 25 (2021), 439–461. https://doi.org/10.3233/IDA-194876 doi: 10.3233/IDA-194876
|
| [39] |
F. Rashid, A. Miri, I. Woungang, Secure image deduplication through image compression, J. Inf. Secur. Appl., 27 (2016), 54–64. https://doi.org/10.1016/j.jisa.2015.11.003 doi: 10.1016/j.jisa.2015.11.003
|
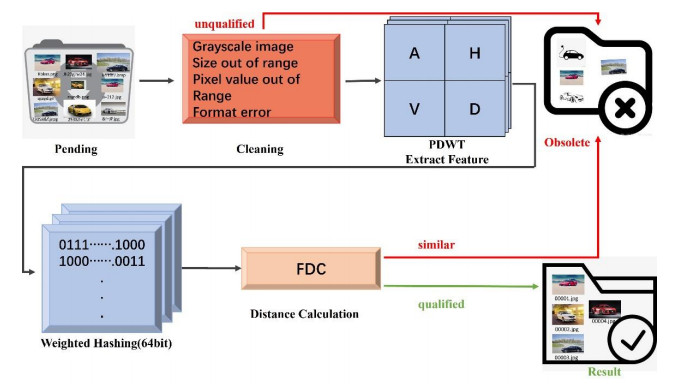
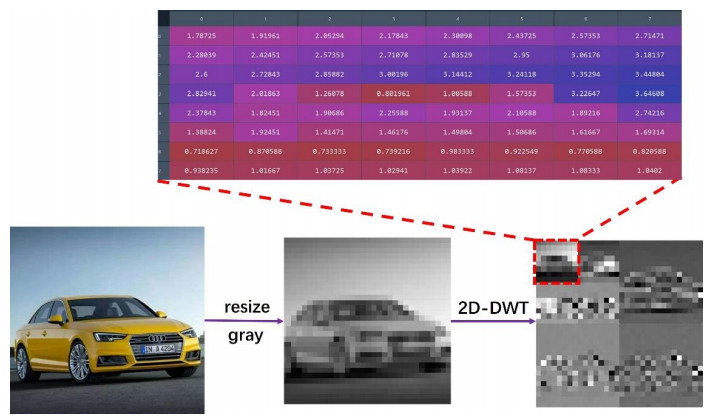

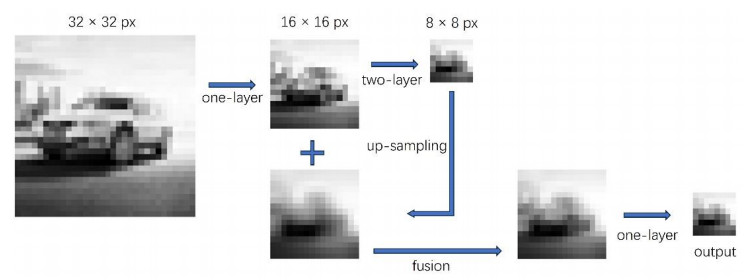
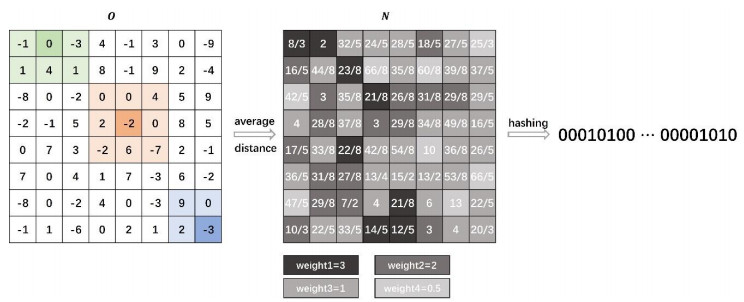

Figures(7) / Tables(8)
Ling Li, Dan He, Cheng Zhang. An image filtering method for dataset production[J]. Electronic Research Archive, 2024, 32(6): 4164-4180. doi: 10.3934/era.2024187







 DownLoad:
DownLoad: