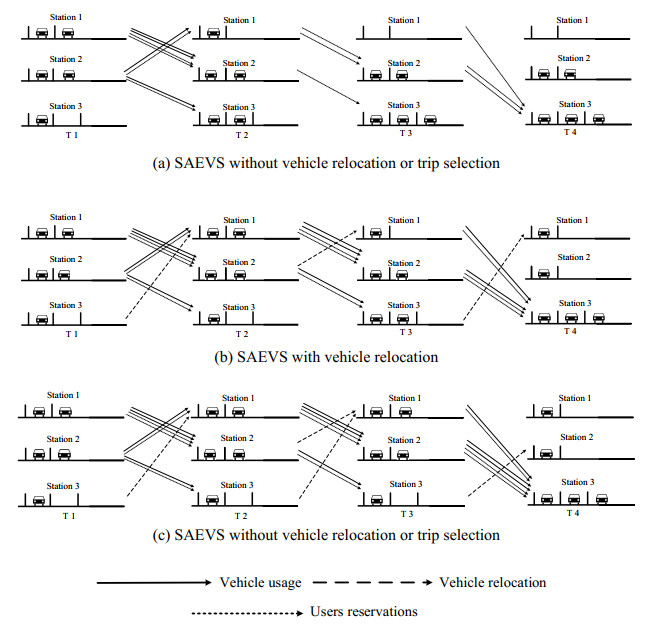
Shared autonomous electric vehicle systems (SAEVS) combine autonomous driving technology with shared electric vehicle services to provide advantages over traditional shared vehicle systems, including autonomous vehicle relocation and rapid response to user needs. In this study, we seek to enhance the operational efficiency and profitability of SAEVS by considering trip selection and the potential opportunity cost associated with unmet user demands. An integer linear programming (ILP) model is developed using a spatio-temporal state network to optimize the system design planning (e.g., charging facility, vehicle fleet sizing and distribution) and operational decisions (e.g., vehicle operational relocation and trip selection strategy). To handle the computational complexities of this model, we propose a Lagrangian relaxation (LR) algorithm. The performance of the LR algorithm is evaluated through a case study. The results, along with a parameter sensitivity analysis, reveal several key findings: (ⅰ) Allocating vehicles to stations with concentrated early peak demand, distributing charging facilities to stations with high total demand throughout the day and implementing vehicle relocation after the early demand peak can mitigate uneven vehicle distribution; (ⅱ) Implementing trip selection enhances SAEVS profitability; (ⅲ) Increasing opportunity cost meets user demands but at the expense of reduced profit; (ⅳ) It is recommended that SAEVS be equipped with charging facilities of suitable charging power based on operational conditions.
Citation: Hao Li, Zhengwu Wang, Shuiwang Chen, Weiyao Xu, Lu Hu, Shuai Huang. Integrated optimization of planning and operation of a shared automated electric vehicle system considering the trip selection and opportunity cost[J]. Electronic Research Archive, 2024, 32(1): 41-71. doi: 10.3934/era.2024003
Shared autonomous electric vehicle systems (SAEVS) combine autonomous driving technology with shared electric vehicle services to provide advantages over traditional shared vehicle systems, including autonomous vehicle relocation and rapid response to user needs. In this study, we seek to enhance the operational efficiency and profitability of SAEVS by considering trip selection and the potential opportunity cost associated with unmet user demands. An integer linear programming (ILP) model is developed using a spatio-temporal state network to optimize the system design planning (e.g., charging facility, vehicle fleet sizing and distribution) and operational decisions (e.g., vehicle operational relocation and trip selection strategy). To handle the computational complexities of this model, we propose a Lagrangian relaxation (LR) algorithm. The performance of the LR algorithm is evaluated through a case study. The results, along with a parameter sensitivity analysis, reveal several key findings: (ⅰ) Allocating vehicles to stations with concentrated early peak demand, distributing charging facilities to stations with high total demand throughout the day and implementing vehicle relocation after the early demand peak can mitigate uneven vehicle distribution; (ⅱ) Implementing trip selection enhances SAEVS profitability; (ⅲ) Increasing opportunity cost meets user demands but at the expense of reduced profit; (ⅳ) It is recommended that SAEVS be equipped with charging facilities of suitable charging power based on operational conditions.

| [1] |
J. Yang, L. Hu, Y. S. Jiang, An overnight relocation problem for one-way carsharing systems considering employment planning, return restrictions, and ride sharing of temporary workers, Transp. Res. Part E Logist. Transp. Rev., 168 (2022), 102950. https://doi.org/10.1016/j.tre.2022.102950 doi: 10.1016/j.tre.2022.102950

|
| [2] | Robo Taxi Market, 2021. Available from: https://www.alliedmarketresearch.com/robo-taxi-market. |
| [3] |
L. Al-Kanj, J. Nascimento, W. B. Powell, Approximate dynamic programming for planning a ride-hailing system using autonomous fleets of electric vehicles, Eur. J. Oper. Res., 3 (2020), 1088–1106. https://doi.org/10.1016/j.ejor.2020.01.033 doi: 10.1016/j.ejor.2020.01.033
|
| [4] |
M. Xu, T. Wu, Z. Tan, Electric vehicle fleet size for carsharing services considering on-demand charging strategy and battery degradation, Transp. Res. Part C Emerging Technol., 127 (2021), 103146. https://doi.org/10.1016/j.trc.2021.103146 doi: 10.1016/j.trc.2021.103146
|
| [5] |
G. Santos, S. Birolini, G. Correia, A flow-based integer programming approach to design an interurban shared automated vehicle system and assess its financial viability, Transp. Res. Part C Emerging Technol., 128 (2021), 103092. https://doi.org/10.1016/j.trc.2021.103092 doi: 10.1016/j.trc.2021.103092
|
| [6] |
G. Guo, Y. Hou, Rebalancing of one-way car-sharing systems considering elastic demand and waiting time, IEEE Trans. Intell. Transp. Syst., 23 (2022), 23295–23310. https://doi.org/10.1109/TITS.2022.3208215 doi: 10.1109/TITS.2022.3208215
|
| [7] |
M. Xu, Q. Meng, Fleet sizing for one-way electric carsharing services considering dynamic vehicle relocation and nonlinear charging profile, Transp. Res. Part B Methodol., 128 (2019), 23–49. https://doi: 10.1016/j.trb.2019.07.016 doi: 10.1016/j.trb.2019.07.016
|
| [8] |
H. Miao, H. Jia, J. Li, T. Qiu, Autonomous connected electric vehicle (acev)-based car-sharing system modeling and optimal planning: A united two-stage multi-objective optimization methodology, Energy, 169 (2019), 797–818. https://doi.org/10.1016/j.trc.2021.103146 doi: 10.1016/j.trc.2021.103146
|
| [9] | H. Li, L. Hu, Y. Jiang, Dynamic pricing, vehicle relocation and staff rebalancing for station-based one-way electric carsharing systems considering nonlinear charging profile, Transp. Lett., 15 (2023), 659–684. https://doi.org/19427867.2022.2079870 |
| [10] |
K. Huang, K. An, G. Correia, J. Rich, W. Ma, An innovative approach to solve the carsharing demand-supply imbalance problem under demand uncertainty, Transp. Res. Part C Emerging Technol., 132 (2021), 103369. https://doi.org/10.1016/j.trc.2021.103369 doi: 10.1016/j.trc.2021.103369
|
| [11] |
R. Nair, E. Miller-Hooks, Fleet management for vehicle sharing operations, Transp. Sci., 45 (2011), 524–540. https://doi.org/10.1287/trsc.1100.0347 doi: 10.1287/trsc.1100.0347
|
| [12] |
M. Nourinejad, S. Zhu, S. Bahram, M. Roorda, Vehicle relocation and staff rebalancing in one-way carsharing systems, Transp. Res. Part E Logist. Transp. Rev., 81 (2015), 98–113. https://doi.org/10.1016/j.tre.2015.06.012 doi: 10.1016/j.tre.2015.06.012
|
| [13] |
M. Repoux, M. Kaspi, B. Boyac, N. Geroliminis, Dynamic prediction-based relocation policies in one-way station-based carsharing systems with complete journey reservations, Transp. Res. Part B Methodol., 130 (2019), 82–104. https://doi.org/10.1016/j.trb.2019.10.004. doi: 10.1016/j.trb.2019.10.004
|
| [14] |
B. Boyaci, K. G. Zografos, Investigating the effect of temporal and spatial flexibility on the performance of one-way electric carsharing systems, Transp. Res. Part B Methodol., 129 (2019), 244–272. http://dx.doi.org/10.1016/j.trb.2019.09.003 doi: 10.1016/j.trb.2019.09.003
|
| [15] |
M. Zhao, X. Li, J. Yin, An integrated framework for electric vehicle rebalancing and staff relocation in one-way carsharing systems: Model formulation and Lagrangian relaxation-based solution approach, Transp. Res. Part B Methodol., 117 (2018), 542–572. https://doi.org/10.1016/j.trb.2018.09.014 doi: 10.1016/j.trb.2018.09.014
|
| [16] |
K. Huang, K. An, J. Rich, W. Ma, Vehicle relocation in one-way station-based electric carsharing systems: A comparative study of operator-based and user-based methods, Transp. Res. Part E Logist. Transp. Rev., 142 (2020), 102081. https://doi.org/10.1016/j.tre.2020.102081 doi: 10.1016/j.tre.2020.102081
|
| [17] |
G. H. A. Correia, A. Antunes, Optimization approach to depot location and trip selection in one-way carsharing systems, Transp. Res. Part E Logist. Transp. Rev., 48 (2012), 233–247. http://doi.org/10.1016/j.tre.2011.06.003 doi: 10.1016/j.tre.2011.06.003
|
| [18] |
K. Huang, G. H. A. Correia, K. An, Solving the station-based one-way carsharing network planning problem with relocation and non-linear demand, Transp. Res. Part C Emerging Technol., 90 (2018). https://doi.org/10.1016/j.trc.2018.02.020 doi: 10.1016/j.trc.2018.02.020
|
| [19] |
W. Huang, S. Jian, One-way carsharing service design under demand uncertainty: A service reliability-based two-stage stochastic program approach, Transp. Res. Part E Logist. Transp. Rev., 159 (2022), 102624. https://doi.org/10.1016/j.tre.2022.102624 doi: 10.1016/j.tre.2022.102624
|
| [20] |
J. Wu, L. Hu, Y. Jiang, Collaborative strategic and tactical planning for one-way station-based carsharing systems with trip selection and vehicle relocation, Transp. Lett., 15 (2023), 18–29. https://doi.org/10.1080/19427867.2021.2008176 doi: 10.1080/19427867.2021.2008176
|
| [21] |
L. Hu, Y. Liu, Joint design of parking capacities and fleet size for one-way station-based Carsharing systems with road congestion constraint, Transp. Res. Part B Methodol., 93 (2016), 268–299. https://doi.org/10.1016/j.trb.2016.07.021 doi: 10.1016/j.trb.2016.07.021
|
| [22] |
G. Brandstater, M. Kahr, M. Leitner, Determining optimal locations for charging stations of electric carsharing systems under stochastic demand, Transp. Res. Part B Methodol., 104 (2017), 17–35. https://doi.org/10.1287/trsc.2021.0494 doi: 10.1287/trsc.2021.0494
|
| [23] |
M. Xu, Q. Meng, Z. Liu, Electric vehicle fleet size and trip pricing for one-way carsharing Services considering vehicle relocation and personnel assignment, Transp. Res. Part B Methodol., 111 (2018), 60–82. https://doi.org/10.1016/j.trb.2018.03.001 doi: 10.1016/j.trb.2018.03.001
|
| [24] |
Y. Hua, D. Zhao, X. Wang, X. Li, Joint infrastructure planning and fleet management for one-way electric car sharing under time-varying uncertain demand, Transp. Res. Part B Methodol., 128 (2019), 185–206. https://doi.org/10.1016/j.trb.2019.07.005 doi: 10.1016/j.trb.2019.07.005
|
| [25] |
Y. Chen, Y. Liu, Integrated optimization of planning and operations for shared autonomous electric vehicle systems, Transp. Sci., 57 (2023), 106–134. https://doi.org/10.1016/j.trb.2019.07.005 doi: 10.1016/j.trb.2019.07.005
|
| [26] |
K. M. Gurumurthy, K. M. Kockelman, M. D. Simoni, Benefits and costs of ride-sharing in shared automated vehicles across Austin, Texas: Opportunities for congestion pricing, Transp. Res. Rec., 2673 (2019), 548–556. https://doi.org/10.1177/0361198119850785 doi: 10.1177/0361198119850785
|
| [27] |
H. Hosni, J. Naoum-Sawaya, H. Artail, The shared-taxi problem: formulation and solution methods, Transp. Res. Part B Methodol., 70 (2014), 303–318. https://doi.org/10.1287/trsc.2022.1156 doi: 10.1287/trsc.2022.1156
|
| [28] |
F. Jiang, V. Cacchiani, P. Toth, Train timetabling by skip-stop planning in highly congested lines, Transp. Res. Part B Methodol., 104 (2017), 149–174. https://doi.org/10.1016/j.trb.2017.06.018 doi: 10.1016/j.trb.2017.06.018
|
| [29] |
C. Zhang, Y. Gao, L. Yang, Z. Gao, J. Qi, Joint optimization of train scheduling and maintenance planning in a railway network: A heuristic algorithm using Lagrangian relaxation, Transp. Res. Part B Methodol., 134 (2020), 64–92. https://doi.org/10.1016/j.trb.2020.02.008 doi: 10.1016/j.trb.2020.02.008
|
| [30] |
G.Brandstater, M. Leitne, I. Ljubi, Location of charging stations in electric car sharing systems, Transp. Sci., 54 (2020). https://doi.org/10.1287/trsc.2019.0931 doi: 10.1287/trsc.2019.0931
|
| [31] | M. Siamak, R. Andrea, E.Matthias, A bi-objective column generatin algorithm for the multi-commodity minimum cost flow problem, Eur. J. Oper. Res., 244 (2015), 369–378. https://doi.org/.1016/j.ejor.2015.01.021 |
| [32] |
L. D. Cicco, G. Manfredi, V. Palmisano, S. Mascolo, A multi-commodity flow problem for fair resource allocation in multi-path video delivery networks, IFAC-Papers OnLine, 53 (2020), 7386–7391. https://doi.org/10.1016/j.ifacol.2020.12.1266 doi: 10.1016/j.ifacol.2020.12.1266
|
| [33] |
T. Alessio, C. Francesco, F. K. David, P. David, The multi-commodity network flow problem with soft transit time constraints: Application to liner shipping, Transp. Res. Part E Logist. Transp. Rev., 150 (2021), 102342. https://doi.org/10.1016/j.tre.2021.102342 doi: 10.1016/j.tre.2021.102342
|
| [34] |
L. Yang, X. Zhou, Constraint reformulation and a Lagrangian relaxation-based solution algorithm for a least expected time path problem, Transp. Res. Part B Methodol., 59 (2014), 22–44. https://doi.org/10.1016/j.trb.2013.10.012 doi: 10.1016/j.trb.2013.10.012
|
| [35] |
Y. Zhang, M. Shen, Z.Jun, S.Song, Lagrangian relaxation for the reliable shortest path problem with correlated link travel times, Transp. Res. Part B Methodol., 104 (2017), 501–521. https://doi.org/10.1016/j.trb.2017.04.006 doi: 10.1016/j.trb.2017.04.006
|
| [36] |
N. Hernández-Leandro, V. Boyer, M. AngélicaSalazar-Aguilar, L. Rousseau, A matheuristic based on Lagrangian relaxation for the multi-activity shift scheduling problem, Eur. J. Oper. Res., 272 (2019), 859–867. https://doi.org/10.1016/j.ejor.2018.07.010 doi: 10.1016/j.ejor.2018.07.010
|
| [37] |
S. Yang, L. Ning, P. Shang, L.Tong, Augmented Lagrangian relaxation approach for logistics vehicle routing problem with mixed backhauls and time windows, Transp. Res. Part E Logist. Transp. Rev., 134 (2020). https://doi.org/10.1016/j.tre.2020.101891 doi: 10.1016/j.tre.2020.101891
|
| [38] |
M. Mahmoudi, X. Zhou, Finding optimal solutions for vehicle routing problem with pickup and delivery services with time windows: A dynamic programming approach based on state-space-time network representations, Transp. Res. Part B Methodol., 89 (2016), 19–42. https://doi.org/10.1016/j.trb.2016.03.009 doi: 10.1016/j.trb.2016.03.009
|










Figures(11) / Tables(5)
Hao Li, Zhengwu Wang, Shuiwang Chen, Weiyao Xu, Lu Hu, Shuai Huang. Integrated optimization of planning and operation of a shared automated electric vehicle system considering the trip selection and opportunity cost[J]. Electronic Research Archive, 2024, 32(1): 41-71. doi: 10.3934/era.2024003







 DownLoad:
DownLoad: