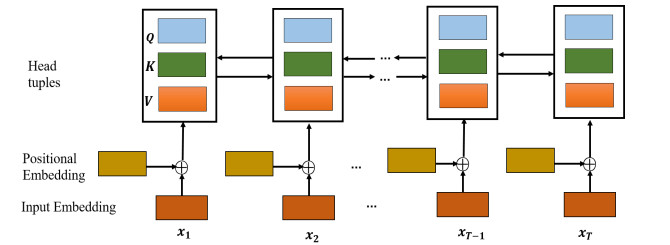
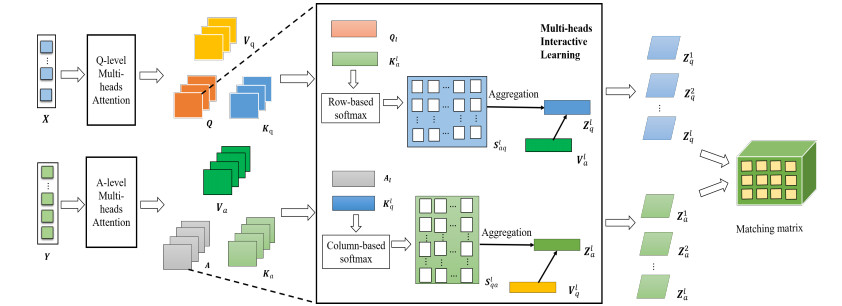
The semantic matching problem detects whether the candidate text is related to a specific input text. Basic text matching adopts the method of statistical vocabulary information without considering semantic relevance. Methods based on Convolutional neural networks (CNN) and Recurrent networks (RNN) provide a more optimized structure that can merge the information in the entire sentence into a single sentence-level representation. However, these representations are often not suitable for sentence interactive learning. We design a multi-dimensional semantic interactive learning model based on the mechanism of multiple written heads in the transformer architecture, which not only considers the correlation and position information between different word levels but also further maps the representation of the sentence to the interactive three-dimensional space, so as to solve the problem and the answer can select the best word-level matching pair, respectively. Experimentally, the algorithm in this paper was tested on Yahoo! and StackEx open-domain datasets. The results show that the performance of the method proposed in this paper is superior to the previous CNN/RNN and BERT-based methods.
Citation: Jinmeng Wu, HanYu Hong, YaoZong Zhang, YanBin Hao, Lei Ma, Lei Wang. Word-level dual channel with multi-head semantic attention interaction for community question answering[J]. Electronic Research Archive, 2023, 31(10): 6012-6026. doi: 10.3934/era.2023306
The semantic matching problem detects whether the candidate text is related to a specific input text. Basic text matching adopts the method of statistical vocabulary information without considering semantic relevance. Methods based on Convolutional neural networks (CNN) and Recurrent networks (RNN) provide a more optimized structure that can merge the information in the entire sentence into a single sentence-level representation. However, these representations are often not suitable for sentence interactive learning. We design a multi-dimensional semantic interactive learning model based on the mechanism of multiple written heads in the transformer architecture, which not only considers the correlation and position information between different word levels but also further maps the representation of the sentence to the interactive three-dimensional space, so as to solve the problem and the answer can select the best word-level matching pair, respectively. Experimentally, the algorithm in this paper was tested on Yahoo! and StackEx open-domain datasets. The results show that the performance of the method proposed in this paper is superior to the previous CNN/RNN and BERT-based methods.

| [1] | M. Pan, Q. Pei, Y. Liu, T. Li, E. A. Huang, J. Wang, et al., Sprf: a semantic pseudo-relevance feedback enhancement for information retrieval via conceptnet, Knowl.-Based Syst., 274 (2023), 110602. https://doi.org/10.1016/j.knosys.2023.110602 |
| [2] | L. Ma, H. Hong, F. Meng, Q. Wu, J. Wu, Deep progressive asymmetric quantization based on causal intervention for fine-grained image retrieval, IEEE Trans. Multimed., 2023 (2023). https://doi.org/10.1109/TMM.2023.3279990 |
| [3] | H. Hasan, H. Huang, Mals-net: A multi-head attention-based lstm sequence-to-sequence network for socio-temporal interaction modelling and trajectory prediction, Sensors, 23 (2023), 530. https://doi.org/10.3390/s23010530 |
| [4] | J. Wu, T. Mu, J. Thiyagalingam, J. Y. Goulermas, Memory-aware attentive control for community question answering with knowledge-based dual refinement, IEEE Trans. Syst. Man Cybern. Syst., 53 (2023), 3930–3943. https://doi.org/10.1109/TSMC.2023.3234297 |
| [5] |
X. Li, B. Wu, J. Song, L. Gao, P. Zeng, C. Gan, Text-instance graph: Exploring the relational semantics for text-based visual question answering, Pattern Recognit., 124 (2022), 108455. https://doi.org/10.1016/j.patcog.2021.108455 doi: 10.1016/j.patcog.2021.108455

|
| [6] |
X. Bi, H. Nie, X. Zhang, X. Zhao, Y. Yuan, G. Wang, Unrestricted multi-hop reasoning network for interpretable question answering over knowledge graph, Knowl.-Based Syst., 243 (2022), 108515. https://doi.org/10.1016/j.knosys.2022.108515 doi: 10.1016/j.knosys.2022.108515
|
| [7] |
W. Zheng, L. Yin, X. Chen, Z. Ma, S. Liu, B. Yang, Knowledge base graph embedding module design for visual question answering model, Pattern Recognit., 120 (2022), 108153. https://doi.org/10.1016/j.patcog.2021.108153 doi: 10.1016/j.patcog.2021.108153
|
| [8] | S. Lv, D. Guo, J. Xu, D. Tang, N. Duan, M. Gong, et al., Graph-based reasoning over heterogeneous external knowledge for commonsense question answering, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2022), 8449–8456. https://doi.org/10.48550/arXiv.1909.05311 |
| [9] | Z. Wang, X. Xu, G. Wang, Y. Yang, H. T. Shen, Quaternion relation embedding for scene graph generation, IEEE Trans. Multimedia, 2023 (2023). https://doi.org/10.1109/TMM.2023.3239229 |
| [10] |
J. Wu, F. Ge, H. Hong, Y. Shi, Y. Hao, L. Ma, Question-aware dynamic scene graph of local semantic representation learning for visual question answering, Pattern Recognit. Lett., 170 (2023), 93–99. https://doi.org/10.1016/j.patrec.2023.04.014 doi: 10.1016/j.patrec.2023.04.014
|
| [11] | H. Zhang, L. Cheng, Y. Hao, C. W. Ngo, Long-term leap attention, short-term periodic shift for video classification, in Proceedings of the 30th ACM International Conference on Multimedia, (2022), 5773–5782. https://doi.org/10.1145/3503161.3547908 |
| [12] |
L. Peng, Y. Yang, Z. Wang, Z. Huang, H. Shen, Mra-net: Improving vqa via multi-modal relation attention network, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2020), 318–329. https://doi.org/10.1109/TPAMI.2020.3004830 doi: 10.1109/TPAMI.2020.3004830
|
| [13] | Z. Wang, Z. Gao, G. Wang, Y. Yang, H. T. Shen, Visual embedding augmentation in fourier domain for deep metric learning, IEEE Trans. Circuits Syst. Video Technol., 2023 (2023). http://doi.org/10.1109/TCSVT.2023.3260082 |
| [14] | M. Tan, C. Santos, B. Xiang, B. Zhou, Lstm-based deep learning models for non-factoid answer selection, preprint, arXiv: 1511.04108. https://doi.org/10.48550/arXiv.1511.04108 |
| [15] | J. Devlin, M. W. Chang, K. Lee, K. Toutanova, Bert: pre-training of deep bidirectional transformers for language understanding, preprint, arXiv: 1810.04805. https://doi.org/10.48550/arXiv.1810.04805 |
| [16] | Y. Li, W. Li, L. Nie, Mmcoqa: Conversational question answering over text, tables, and images, in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), (2022), 4220–4231. |
| [17] |
X. Zhao, J. X. Huang, Bert-qanet: Bert-encoded hierarchical question-answer cross-attention network for duplicate question detection, Neurocomputing, 509 (2022), 68–74. https://doi.org/10.1016/j.neucom.2022.08.044 doi: 10.1016/j.neucom.2022.08.044
|
| [18] | Y. Guan, Z. Li, Z. Lin, Y. Zhu, J. Leng, M. Guo, Block-skim: efficient question answering for transformer, in Proceedings of the AAAI Conference on Artificial Intelligence, 36 (2022), 10710–10719. |
| [19] | Z. Yang, Z. Gan, J. Wang, X. Hu, Y. Lu, Z. Liu, et al., An empirical study of gpt-3 for few-shot knowledge-based vqa, in Proceedings of the AAAI Conference on Artificial Intelligence, 36 (2022), 3081–3089. |
| [20] | H. Sak, A. Senior, F. Beaufays, Long short-term memory recurrent neural network architectures for large scale acoustic modeling, in Interspeech 2014, (2014), 338–342. |
| [21] | G. Zhou, Y. Zhou, T. He, W. Wu, Learning semantic representation with neural networks for community question answering retrieval, Knowl.-Based Syst., 93 (2016), 75–83. https://doi.org/10.1016/j.knosys.2015.11.002 |
| [22] | A. Anderson, D. Huttenlocher, J. Kleinberg, J. Leskovec, Discovering value from community activity on focused question answering sites: a case study of stack overflow, in Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, (2012), 850–858. |
| [23] | J. Wu, T. Mu, J. Thiyagalingam, J. Y. Goulermas, Building interactive sentence-aware representation based on generative language model for community question answering, Neurocomputing, 2020 (2020), 93–107. https://doi.org/10.1016/j.neucom.2019.12.107 |
| [24] | A. Severyn, A. Moschitti, Learning to rank short text pairs with convolutional deep neural networks, in Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, (2015), 373–382. |
| [25] | Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, et al., Roberta: A robustly optimized bert pretraining approach, preprint, arXiv: 1907.11692. https://doi.org/10.48550/arXiv.1907.11692 |
| [26] | B. Hu, Z. Lu, H. Li, Q. Chen, Convolutional neural network architectures for matching natural language sentences, Adv. Neural Inf. Process. Syst., (2014), 2042–2050. |
| [27] | L. Yu, K. M. Hermann, P. Blunsom, S. Pulman, Deep learning for answer sentence selection, preprint, arXiv: 1412.1632. https://doi.org/10.48550/arXiv.1412.1632 |
| [28] | M. Seo, A. Kembhavi, A. Farhadi, H. Hajishirzi, Bidirectional attention flow for machine comprehension, preprint, arXiv: 1611.01603. https://doi.org/10.48550/arXiv.1611.01603 |
| [29] | S. Wan, Y. Lan, J. Guo, J. Xu, L. Pang, X. Cheng, A deep architecture for semantic matching with multiple positional sentence representations, in Proceedings of the AAAI Conference on Artificial Intelligence, 30 (2016), 2835–2841. |
| [30] | M. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, et al., Deep contextualized word representations, in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), (2018), 2227–2237. |
| [31] | S. Garg, T. Vu, A. Moschitti, Tanda: Transfer and adapt pre-trained transformer models for answer sentence selection, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 7780–7788. |
| [32] | L. D. Liello, S. Garg, L. Soldaini, A. Moschitti, Pre-training transformer models with sentence-level objectives for answer sentence selection, preprint, arXiv: 2205.10455. https://doi.org/10.48550/arXiv.2205.10455 |
Figures(2) / Tables(6)
Jinmeng Wu, HanYu Hong, YaoZong Zhang, YanBin Hao, Lei Ma, Lei Wang. Word-level dual channel with multi-head semantic attention interaction for community question answering[J]. Electronic Research Archive, 2023, 31(10): 6012-6026. doi: 10.3934/era.2023306







 DownLoad:
DownLoad: