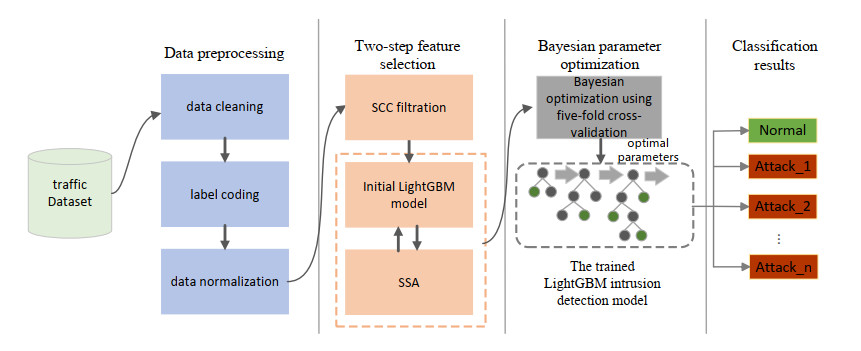
With the widespread application of the Internet of Things (IoT), security risks are becoming increasingly severe. However, due to the limitations in computing resources and energy consumption of IoT devices, traditional intrusion detection models are difficult to apply directly. Although existing methods offer high detection rates, they generally suffer from issues such as complex model structures and deployment difficulties. To address these problems, a lightweight intrusion detection method based on two-stage feature selection and Bayesian optimization is proposed. The method first employs the Spearman Correlation Coefficient (SCC) for filter-based selection to remove redundant features. Then, the Salp Swarm Algorithm (SSA) is used for wrapper-based selection to obtain the optimal feature subset. Finally, a lightweight and efficient LightGBM classifier is constructed, with its parameters adaptively optimized using Bayesian optimization. Unlike previous LightGBM-based IDS studies that rely on manually pruned features and heuristic parameter tuning, this work is the first to couple an SCC–SSA two-stage selection pipeline with Bayesian optimization, providing a fully automated and resource-aware workflow tailored for IoT devices. Experimental results show that the proposed method achieves classification accuracies of 97.22% and 96.08% on the TON_IoT and UNSW-NB15 datasets, respectively. Among them, the model size on the UNSW-NB15 dataset is only 1.77 MB, fully demonstrating its excellent detection performance and lightweight characteristics, making it suitable for deployment on resource-constrained IoT terminal devices.
Citation: Dainan Zhang, Dehui Huang, Yanying Chen, Songquan Lin, Chuxuan Li. A lightweight IoT intrusion detection method based on two-stage feature selection and Bayesian optimization[J]. AIMS Electronics and Electrical Engineering, 2025, 9(3): 359-389. doi: 10.3934/electreng.2025017
With the widespread application of the Internet of Things (IoT), security risks are becoming increasingly severe. However, due to the limitations in computing resources and energy consumption of IoT devices, traditional intrusion detection models are difficult to apply directly. Although existing methods offer high detection rates, they generally suffer from issues such as complex model structures and deployment difficulties. To address these problems, a lightweight intrusion detection method based on two-stage feature selection and Bayesian optimization is proposed. The method first employs the Spearman Correlation Coefficient (SCC) for filter-based selection to remove redundant features. Then, the Salp Swarm Algorithm (SSA) is used for wrapper-based selection to obtain the optimal feature subset. Finally, a lightweight and efficient LightGBM classifier is constructed, with its parameters adaptively optimized using Bayesian optimization. Unlike previous LightGBM-based IDS studies that rely on manually pruned features and heuristic parameter tuning, this work is the first to couple an SCC–SSA two-stage selection pipeline with Bayesian optimization, providing a fully automated and resource-aware workflow tailored for IoT devices. Experimental results show that the proposed method achieves classification accuracies of 97.22% and 96.08% on the TON_IoT and UNSW-NB15 datasets, respectively. Among them, the model size on the UNSW-NB15 dataset is only 1.77 MB, fully demonstrating its excellent detection performance and lightweight characteristics, making it suitable for deployment on resource-constrained IoT terminal devices.

| [1] |
Solmaz G, Wu FJ, Cirillo F, Kovacs E, Santana JR, Sánchez L, et al. (2019) Toward understanding crowd mobility in smart cities through the internet of things. IEEE Commun Mag 57: 40–46. https://doi.org/10.1109/MCOM.2019.1800611 doi: 10.1109/MCOM.2019.1800611

|
| [2] |
Wang T, Luo H, Jia W, Liu A, Xie M (2019) Mtes: An intelligent trust evaluation scheme in sensor-cloud-enabled industrial internet of things. IEEE T Ind Inform 16: 2054–2062. https://doi.org/10.1109/TII.2019.2930286 doi: 10.1109/TII.2019.2930286
|
| [3] |
Brotsis S, Limniotis K, Bendiab G, Kolokotronis N, Shiaeles S (2021). On the suitability of blockchain platforms for IoT applications: Architectures, security, privacy, and performance. Comput Netw 191: 108005. https://doi.org/10.1016/j.comnet.2021.108005 doi: 10.1016/j.comnet.2021.108005
|
| [4] |
Hassan WH (2019) Current research on Internet of Things (IoT) security: A survey. Comput Netw 148: 283–294. https://doi.org/10.1016/j.comnet.2018.11.025 doi: 10.1016/j.comnet.2018.11.025
|
| [5] |
Anthi E, Williams L, Słowińska M, Theodorakopoulos G, Burnap P (2019) A supervised intrusion detection system for smart home IoT devices. IEEE Internet Things 6: 9042–9053. https://doi.org/10.1109/JIOT.2019.2926365 doi: 10.1109/JIOT.2019.2926365
|
| [6] |
Abiodun OI, Abiodun EO, Alawida M, Alkhawaldeh RS, Arshad H (2021) A review on the security of the internet of things: Challenges and solutions. Wireless Pers Commun 119: 2603–2637. https://doi.org/10.1007/s11277-021-08348-9 doi: 10.1007/s11277-021-08348-9
|
| [7] |
Popoola SI, Adebisi B, Hammoudeh M, Gui G, Gacanin H (2020) Hybrid deep learning for botnet attack detection in the internet-of-things networks. IEEE Internet Things 8: 4944–4956. https://doi.org/10.1109/JIOT.2020.3034156 doi: 10.1109/JIOT.2020.3034156
|
| [8] |
Fenanir S, Semchedine F, Baadache A (2019) A Machine Learning-Based Lightweight Intrusion Detection System for the Internet of Things. Revue D Intelligence Artificielle 33: 203–211. https://doi.org/10.18280/ria.330306 doi: 10.18280/ria.330306
|
| [9] | Radivilova T, Kirichenko L, Alghawli AS, Ilkov A, Tawalbeh M, Zinchenko P (2020) The complex method of intrusion detection based on anomaly detection and misuse detection. In: 2020 IEEE 11th International Conference on Dependable Systems, Services and Technologies (DESSERT), 133–137. https://doi.org/10.1109/DESSERT50317.2020.9125051 |
| [10] |
Chou D, Jiang M (2021) A survey on data-driven network intrusion detection. ACM Computing Surveys (CSUR) 54: 1–36. https://doi.org/10.1145/3472753 doi: 10.1145/3472753
|
| [11] |
Buczak AL, Guven E (2015) A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun Surv Tut 18: 1153–1176. https://doi.org/10.1109/COMST.2015.2494502 doi: 10.1109/COMST.2015.2494502
|
| [12] |
Roy S, Li J, Choi BJ, Bai Y (2022) A lightweight supervised intrusion detection mechanism for IoT networks. Future Generation Computer Systems 127: 276–285. https://doi.org/10.1016/j.future.2021.09.027 doi: 10.1016/j.future.2021.09.027
|
| [13] |
Cho HH, Wu HT, Lai CF, Shih TK, Tseng FH (2020) Intelligent charging path planning for IoT network over blockchain-based edge architecture. IEEE Internet Things 8: 2379–2394. https://doi.org/10.1109/JIOT.2020.3027418 doi: 10.1109/JIOT.2020.3027418
|
| [14] |
Soe YN, Feng Y, Santosa PI, Hartanto R, Sakurai K (2020) Towards a lightweight detection system for cyber attacks in the IoT environment using corresponding features. Electronics 9: 144. https://doi.org/10.3390/electronics9010144 doi: 10.3390/electronics9010144
|
| [15] |
Islam N, Farhin F, Sultana I, Kaiser MS, Rahman MS, Mahmud M, et al. (2021) Towards machine learning based intrusion detection in IoT networks. Comput Mater Contin 69: 1801–1821. https://doi.org/10.32604/cmc.2021.018466 doi: 10.32604/cmc.2021.018466
|
| [16] |
Wang Z, Li Z, He D, Chan S (2022) A lightweight approach for network intrusion detection in industrial cyber-physical systems based on knowledge distillation and deep metric learning. Expert Syst Appl 206: 117671. https://doi.org/10.1016/j.eswa.2022.117671 doi: 10.1016/j.eswa.2022.117671
|
| [17] |
Imrana Y, Xiang Y, Ali L, Abdul-Rauf Z (2021) A bidirectional LSTM deep learning approach for intrusion detection. Expert Syst Appl 185: 115524. https://doi.org/10.1016/j.eswa.2021.115524 doi: 10.1016/j.eswa.2021.115524
|
| [18] |
Yang Y, Tu S, Ali RH, Alasmary H, Waqas M, Amjad MN (2023) Intrusion detection based on bidirectional long short-term memory with attention mechanism. CMC-Computer Material and Continua 74: 801–815. https://doi.org/10.32604/cmc.2023.031907 doi: 10.32604/cmc.2023.031907
|
| [19] |
Zarai R, Kachout M, Hazber M, Mahdi M (2020) Recurrent Neural Networks & Deep Neural Networks Based on Intrusion Detection System. Open Access Library Journal 7: 1–11. https://doi.org/10.4236/oalib.1106151 doi: 10.4236/oalib.1106151
|
| [20] |
Diro AA, Chilamkurti N (2018) Distributed attack detection scheme using deep learning approach for Internet of Things. Future Generation Computer Systems 82: 761–768. https://doi.org/10.1016/j.future.2017.08.043 doi: 10.1016/j.future.2017.08.043
|
| [21] |
Zhang Y, Li P, Wang X (2019) Intrusion detection for IoT based on improved genetic algorithm and deep belief network. IEEE Access 7: 31711–31722. https://doi.org/10.1109/ACCESS.2019.2903723 doi: 10.1109/ACCESS.2019.2903723
|
| [22] |
Aminanto ME, Choi R, Tanuwidjaja HC, Yoo PD, Kim K (2017) Deep abstraction and weighted feature selection for Wi-Fi impersonation detection. IEEE T Inf Foren Sec 13: 621–636. https://doi.org/10.1109/TIFS.2017.2762828 doi: 10.1109/TIFS.2017.2762828
|
| [23] |
Kim YE, Kim YS, Kim H (2022) Effective feature selection methods to detect IoT DDoS attack in 5G core network. Sensors 22: 3819. https://doi.org/10.3390/s22103819 doi: 10.3390/s22103819
|
| [24] |
Vijayanand R, Devaraj D, Kannapiran B (2018) A novel intrusion detection system for wireless mesh network with hybrid feature selection technique based on GA and MI. J Intell Fuzzy Syst 34: 1243–1250. https://doi.org/10.3233/JIFS-169421 doi: 10.3233/JIFS-169421
|
| [25] |
Kumar P, Gupta GP, Tripathi R (2021) Toward design of an intelligent cyber attack detection system using hybrid feature reduced approach for iot networks. Arab J Sci Eng 46: 3749–3778. https://doi.org/10.1007/s13369-020-05181-3 doi: 10.1007/s13369-020-05181-3
|
| [26] |
Alhakami W, ALharbi A, Bourouis S, Alroobaea R, Bouguila N (2019) Network anomaly intrusion detection using a nonparametric Bayesian approach and feature selection. IEEE access 7: 52181–52190. https://doi.org/10.1109/ACCESS.2019.2912115 doi: 10.1109/ACCESS.2019.2912115
|
| [27] | Qureshi AUH, Larijani H, Ahmad J, Mtetwa N (2019) A heuristic intrusion detection system for Internet-of-Things (IoT). In: Intelligent Computing: Proceedings of the 2019 Computing Conference 1: 86–98. https://doi.org/10.1007/978-3-030-22871-2_7 |
| [28] | Oreški D, Andročec D (2018) Hybrid data mining approaches for intrusion detection in the internet of things. In: 2018 International Conference on Smart Systems and Technologies (SST), 221–226. https://doi.org/10.1109/SST.2018.8564573 |
| [29] |
Yousaf MZ, Khalid S, Tahir MF, Tzes A, Raza A (2023) A novel dc fault protection scheme based on intelligent network for meshed dc grids. Int J Elec Power 154: 109423. https://doi.org/10.1016/j.ijepes.2023.109423 doi: 10.1016/j.ijepes.2023.109423
|
| [30] |
Yousaf MZ, Liu H, Raza A, Mustafa A (2022) Deep learning-based robust dc fault protection scheme for meshed HVdc grids. CSEE Journal of Power and Energy Systems. CSEE J Power Energy 9: 2423–2434. https://doi.org/10.17775/CSEEJPES.2021.03550 doi: 10.17775/CSEEJPES.2021.03550
|
| [31] |
Yousaf MZ, Tahir MF, Raza A, Khan MA, Badshah F (2022) Intelligent sensors for dc fault location scheme based on optimized intelligent architecture for HVdc systems. Sensors 22: 9936. https://doi.org/10.3390/s22249936 doi: 10.3390/s22249936
|
| [32] |
Zhao G, Wang Y, Wang J (2023) Intrusion detection model of Internet of Things based on LightGBM. IEICE T Commun 106: 622–634. https://doi.org/10.1587/transcom.2022EBP3169 doi: 10.1587/transcom.2022EBP3169
|
| [33] |
Yao H, Gao P, Zhang P, Wang J, Jiang C, Lu L (2019) Hybrid intrusion detection system for edge-based IIoT relying on machine-learning-aided detection. IEEE Network 33: 75–81. https://doi.org/10.1109/MNET.001.1800479 doi: 10.1109/MNET.001.1800479
|
| [34] |
Okey OD, Melgarejo DC, Saadi M, Rosa RL, Kleinschmidt JH, Rodríguez DZ (2023) Transfer learning approach to IDS on cloud IoT devices using optimized CNN. IEEE Access 11: 1023–1038. https://doi.org/10.1109/ACCESS.2022.3233775 doi: 10.1109/ACCESS.2022.3233775
|
| [35] |
Lahasan B, Samma H (2022) Optimized deep autoencoder model for internet of things intruder detection. IEEE Access 10: 8434–8448. https://doi.org/10.1109/ACCESS.2022.3144208 doi: 10.1109/ACCESS.2022.3144208
|
| [36] |
Basati A, Faghih MM (2022) PDAE: Efficient network intrusion detection in IoT using parallel deep auto-encoders. Inform Sciences 598: 57–74. https://doi.org/10.1016/j.ins.2022.03.065 doi: 10.1016/j.ins.2022.03.065
|
| [37] |
Altaf T, Wang X, Ni W, Liu RP, Braun R (2023) NE-GConv: A lightweight node edge graph convolutional network for intrusion detection. Comput Secur 130: 103285. https://doi.org/10.1016/j.cose.2023.103285 doi: 10.1016/j.cose.2023.103285
|
| [38] |
Jan SU, Ahmed S, Shakhov V, Koo I (2019) Toward a lightweight intrusion detection system for the internet of things. IEEE access 7: 42450–42471. https://doi.org/10.1109/ACCESS.2019.2907965 doi: 10.1109/ACCESS.2019.2907965
|
| [39] |
Yang Z, Liu Z, Zong X, Wang G (2023) An optimized adaptive ensemble model with feature selection for network intrusion detection. Concurr Comput-Pract Exp 35: e7529. https://doi.org/10.1002/cpe.7529 doi: 10.1002/cpe.7529
|
| [40] |
Mirjalili S, Gandomi AH, Mirjalili SZ, Saremi S, Faris H, Mirjalili SM (2017) Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv Eng Softw 114: 163–191. https://doi.org/10.1016/j.advengsoft.2017.07.002 doi: 10.1016/j.advengsoft.2017.07.002
|
| [41] | Saber A, Abbas M, Fergani B (2021) Two-dimensional intrusion detection system: a new feature selection technique. In: 2020 2nd International Workshop on Human-Centric Smart Environments for Health and Well-being (IHSH), 69–74. https://doi.org/10.1109/IHSH51661.2021.9378721 |
| [42] |
Greenhill S, Rana S, Gupta S, Vellanki P, Venkatesh S (2020) Bayesian optimization for adaptive experimental design: A review. IEEE access 8: 13937–13948. https://doi.org/10.1109/ACCESS.2020.2966228 doi: 10.1109/ACCESS.2020.2966228
|
| [43] |
Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, et al. (2017) Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems 30: 3149–3157. https://doi.org/10.5555/3294996.3295074 doi: 10.5555/3294996.3295074
|
| [44] |
Zhang C, Zhang Y, Shi X, Almpanidis G, Fan G, Shen X (2019) On incremental learning for gradient boosting decision trees. Neural Process Lett 50: 957–987. https://doi.org/10.1007/s11063-019-09999-3 doi: 10.1007/s11063-019-09999-3
|
| [45] |
Peng Y, Zhao S, Zeng Z, Hu X, Yin Z (2023) LGBMDF: A cascade forest framework with LightGBM for predicting drug-target interactions. Front Microbiol 13: 1092467. https://doi.org/10.3389/fmicb.2022.1092467 doi: 10.3389/fmicb.2022.1092467
|
| [46] |
Alsaedi A, Moustafa N, Tari Z, Mahmood A, Anwar A (2020) TON_IoT telemetry dataset: A new generation dataset of IoT and IIoT for data-driven intrusion detection systems. IEEE Access 8: 165130–165150. https://doi.org/10.1109/ACCESS.2020.3022862 doi: 10.1109/ACCESS.2020.3022862
|
| [47] | Moustafa N, Slay J (2015) UNSW-NB15: a comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In: 2015 military communications and information systems conference (MilCIS), 1–6. https://doi.org/10.1109/MilCIS.2015.7348942 |
| [48] |
Moustafa N, Slay J (2016) The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Information Security Journal: A Global Perspective 25: 18–31. https://doi.org/10.1080/19393555.2015.1125974 doi: 10.1080/19393555.2015.1125974
|
| [49] | Ali MH, Fadlizolkipi M, Firdaus A, Khidzir NZ (2018) A hybrid particle swarm optimization-extreme learning machine approach for intrusion detection system. In: 2018 IEEE student conference on research and development (SCOReD), 1–4. https://doi.org/10.1109/SCORED.2018.8711287 |
| [50] |
Tao P, Sun Z, Sun Z (2018) An improved intrusion detection algorithm based on GA and SVM. IEEE Access 6: 13624–13631. https://doi.org/10.1109/ACCESS.2018.2810198 doi: 10.1109/ACCESS.2018.2810198
|
Figures(10) / Tables(15)

Dainan Zhang, Dehui Huang, Yanying Chen, Songquan Lin, Chuxuan Li. A lightweight IoT intrusion detection method based on two-stage feature selection and Bayesian optimization[J]. AIMS Electronics and Electrical Engineering, 2025, 9(3): 359-389. doi: 10.3934/electreng.2025017







 DownLoad:
DownLoad: