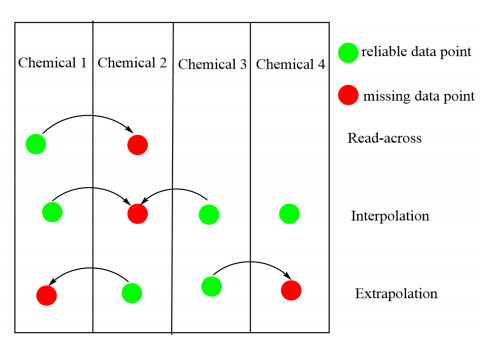
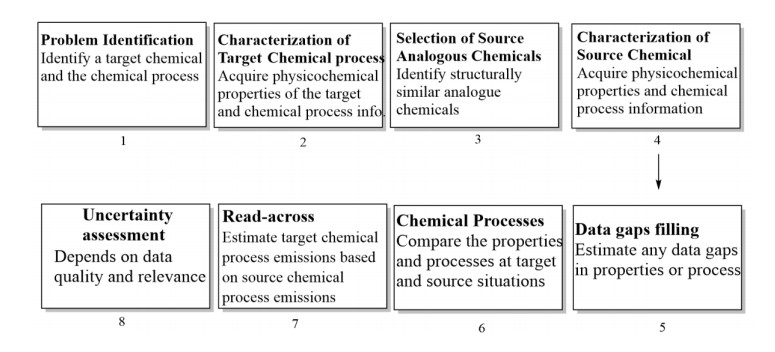
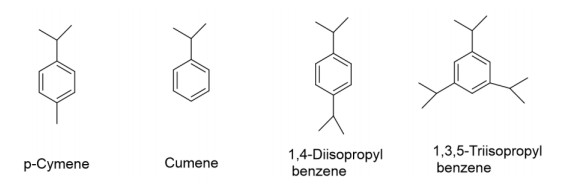
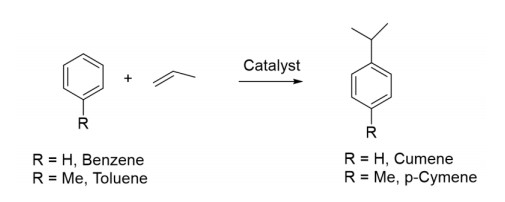
The read-across method is a popular data gap filling technique with developed application for multiple purposes, including regulatory. Within the US Environmental Protection Agency's (US EPA) New Chemicals Program under Toxic Substances Control Act (TSCA), read-across has been widely used, as well as within technical guidance published by the Organization for Economic Co-operation and Development, the European Chemicals Agency, and the European Center for Ecotoxicology and Toxicology of Chemicals for filling chemical toxicity data gaps. Under the TSCA New Chemicals Review Program, US EPA is tasked with reviewing proposed new chemical applications prior to commencing commercial manufacturing within or importing into the United States. The primary goal of this review is to identify any unreasonable human health and environmental risks, arising from environmental releases/emissions during manufacturing and the resulting exposure from these environmental releases. The authors propose the application of read-across techniques for the development and use of a framework for estimating the emissions arising during the chemical manufacturing process. This methodology is to utilize available emissions data from a structurally similar analogue chemical or a group of structurally similar chemicals in a chemical family taking into consideration their physicochemical properties under specified chemical process unit operations and conditions. This framework is also designed to apply existing knowledge of read-across principles previously utilized in toxicity estimation for an analogue or category of chemicals and introduced and extended with a concurrent case study.
Citation: Sudhakar Takkellapati, Michael A. Gonzalez. Application of read-across methods as a framework for the estimation of emissions from chemical processes[J]. Clean Technologies and Recycling, 2023, 3(4): 283-300. doi: 10.3934/ctr.2023018
The read-across method is a popular data gap filling technique with developed application for multiple purposes, including regulatory. Within the US Environmental Protection Agency's (US EPA) New Chemicals Program under Toxic Substances Control Act (TSCA), read-across has been widely used, as well as within technical guidance published by the Organization for Economic Co-operation and Development, the European Chemicals Agency, and the European Center for Ecotoxicology and Toxicology of Chemicals for filling chemical toxicity data gaps. Under the TSCA New Chemicals Review Program, US EPA is tasked with reviewing proposed new chemical applications prior to commencing commercial manufacturing within or importing into the United States. The primary goal of this review is to identify any unreasonable human health and environmental risks, arising from environmental releases/emissions during manufacturing and the resulting exposure from these environmental releases. The authors propose the application of read-across techniques for the development and use of a framework for estimating the emissions arising during the chemical manufacturing process. This methodology is to utilize available emissions data from a structurally similar analogue chemical or a group of structurally similar chemicals in a chemical family taking into consideration their physicochemical properties under specified chemical process unit operations and conditions. This framework is also designed to apply existing knowledge of read-across principles previously utilized in toxicity estimation for an analogue or category of chemicals and introduced and extended with a concurrent case study.

| [1] |
Breivik K, Arnot JA, Brown TN, et al. (2012) Screening organic chemicals in commerce for emissions in the context of environmental and human exposure. J Environ Monit 14: 2028–2037. https://doi.org/10.1039/c2em30259d doi: 10.1039/c2em30259d

|
| [2] |
Fauser P, Thomsen M, Pistocchi A, et al. (2010) Using multiple regression in estimating (semi) VOC emissions and concentrations at the European scale. Atmos Pollut Res 1: 132–140. https://doi.org/10.5094/APR.2010.017 doi: 10.5094/APR.2010.017
|
| [3] | ENV/JM/MONO(2006)6, No. 52, Comparison of emission estimation methods used in pollutant release and transfer registers and emission scenario documents: Case study of pulp and paper and textiles. OECD Series on testing and assessment, 2006. Available from: https://one.oecd.org/document/env/jm/mono(2006)6/en/pdf. |
| [4] | EPA, Air Emissions Factors and Quantification. Environmental Protection Agency, n.d. Available from: https://www.epa.gov/air-emissions-factors-and-quantification. |
| [5] |
Smith RL, Ruiz-Mercado GJ, Meyer DE, et al. (2017) Coupling computer-aided process simulation and estimations of emissions and land use for rapid life cycle inventory modeling. ACS Sustain Chem Eng 5: 3786−3794. https://doi.org/10.1021/acssuschemeng.6b02724 doi: 10.1021/acssuschemeng.6b02724
|
| [6] | NSTC, Sustainable Chemistry Report Framing the Federal Landscape. The National Science and Technology Council, 2023. Available from: https://www.whitehouse.gov/wp-content/uploads/2023/08/NSTC-JCEIPH-SCST-Sustainable-Chemistry-Federal-Landscape-Report-to-Congress.pdf. |
| [7] | EPA, EPI Suite™-Estimation Program Interface. Environmental Protection Agency, n.d. Available from: https://www.epa.gov/tsca-screening-tools/epi-suitetm-estimation-program-interface. |
| [8] | EPA, Toxicity Estimation Software Tool (TEST). Environmental Protection Agency, n.d. Available from: https://www.epa.gov/comptox-tools/toxicity-estimation-software-tool-test. |
| [9] |
Patlewicz G, Helman G, Pradeep P, et al. (2017) Navigating through the minefield of read-across tools: A review of in silico tools for grouping. Comput Toxicol 3: 1–18. https://doi.org/10.1016/j.comtox.2017.05.003 doi: 10.1016/j.comtox.2017.05.003
|
| [10] | Patlewicz G, Chemical Categories and Read-Across, European Commission Directorate General. European Communities, 2005. Available from: http://publications.jrc.ec.europa.eu/repository/bitstream/JRC31792/Chemical%20Categories%20and%20Read%20across_Dec.pdf. |
| [11] | OECD, Environment Directorate Joint Meeting of the Chemicals Committee and the Working Party on Chemicals, Pesticides and Biotechnology. OECD Publishing, 2014. Available from: http://www.oecd.org/officialdocuments/publicdisplaydocumentpdf/?cote=env/jm/mono%282014%294&doclanguage=en. |
| [12] | ECHA, Guidance on information requirements and chemical safety assessment, Chapter R.6: QSARs and grouping of chemicals. European Chemicals Agency, 2008. Available from: https://echa.europa.eu/documents/10162/17224/information_requirements_r6_en.pdf/77f49f81-b76d-40ab-8513-4f3a533b6ac9?t=1322594777272. |
| [13] | ECETOC, Technical Report No 116, Category approaches, Read-across, (Q)SAR. European Centre for Ecotoxicology and Toxicology of Chemicals, 2012. Available from: https://www.ecetoc.org/publication/tr-116-category-approaches-read-across-qsar/. |
| [14] |
Wu S, Blackburn K, Amburgey J, et al. (2010) A framework for using structural, reactivity, metabolic and physicochemical similarity to evaluate the suitability of analogs for SAR-based toxicological assessments. Reg Toxicol Pharmacol 56: 67–81. https://doi.org/10.1016/j.yrtph.2009.09.006 doi: 10.1016/j.yrtph.2009.09.006
|
| [15] |
Patlewicz G, Ball N, Booth ED, et al. (2013) Use of category approaches, read-across and (Q)SAR; general considerations. Reg Toxicol Pharmacol 67: 1–12. https://doi.org/10.1016/j.yrtph.2013.06.002 doi: 10.1016/j.yrtph.2013.06.002
|
| [16] |
Ball N, Cronin MTD, Shen J, et al. (2016) Toward good read-across practice (GRAP) guidance. ALTEX 33: 149–166. https://doi.org/10.14573/altex.1601251 doi: 10.14573/altex.1601251
|
| [17] |
Cronin MTD, Jaworska JS, Walker JD, et al. (2003) Use of QSARs in international decision-making frameworks to predict health effects of chemical substances. Environ Health Perspect 111: 1391–1401. https://doi.org/10.1289/ehp.5760 doi: 10.1289/ehp.5760
|
| [18] |
Cronin MTD, Walker JD, Jaworska JS, et al. (2003) Use of QSARs in international decision-making frameworks to predict ecologic effects and environmental fate of chemical substances. Environ Health Perspect 111: 1376–1390. https://doi.org/10.1289/ehp.5759 doi: 10.1289/ehp.5759
|
| [19] | Worth AP, Patlewicz G, A Compendium of Case Studies that Helped Shape the REACH Guidance on Chemical Categories and Read-Across. EUR 22481 EN, 2007. Available from: https://publications.jrc.ec.europa.eu/repository/handle/JRC37212. |
| [20] |
van Leeuwen K, Schultz TW, Henry T, et al. (2009) Using chemical categories to fill data gaps in hazard assessment. SAR QSAR Environ Res 20: 207–220. https://doi.org/10.1080/10629360902949179 doi: 10.1080/10629360902949179
|
| [21] | US EPA, TSCA New Chemicals Program (NCP) Chemical Categories. Office of Pollution Prevention and Toxics, US Environmental Protection Agency, 2010. Available from: https://www.epa.gov/sites/default/files/2014-10/documents/ncp_chemical_categories_august_2010_version_0.pdf. |
| [22] | ECHA, Evaluation under REACH Progress Report 2014. European Chemicals Agency, 2014. Available from: https://echa.europa.eu/documents/10162/17221/evaluation_report_2014_en.pdf/77ef2e2b-279b-4d10-a097-d8478b16ccc8?t = 1424942520291. |
| [23] |
Luechtefeld T, Maertens A, Russo DP, et al. (2016) Global analysis of publicly available safety data for 9,801 substances registered under REACH from 2008-2014. Altex 33: 95–109. https://doi.org/10.14573/altex.1510052 doi: 10.14573/altex.1510052
|
| [24] |
Berggren E, Amcoff P, Benigni R, et al. (2015) Chemical safety assessment using read-across: Assessing the use of novel testing methods to strengthen the evidence base for decision making. Environ Health Persp 123: 1232–1240. https://doi.org/10.1289/ehp.1409342 doi: 10.1289/ehp.1409342
|
| [25] |
Benfenati E, Chaudhry Q, Gini G, et al. (2019) Integrating in silico models and read-across methods for predicting toxicity of chemicals: A step-wise strategy. Environ Int 131: 105060. https://doi.org/10.1016/j.envint.2019.105060 doi: 10.1016/j.envint.2019.105060
|
| [26] |
Schultz TW, Amcoff P, Berggren E, et al. (2015) A strategy for structuring and reporting a read-across prediction of toxicity. Reg Toxicol Pharmacol 72: 586–601. https://doi.org/10.1016/j.yrtph.2015.05.016 doi: 10.1016/j.yrtph.2015.05.016
|
| [27] |
Oomen AG, Bleeker EAJ, Bos PMJ, et al. (2015) Grouping and read-across approaches for risk assessment of nanomaterials. Int J Environ Res Public Health 12: 13415–13434. https://doi.org/10.3390/ijerph121013415 doi: 10.3390/ijerph121013415
|
| [28] |
Sizochenko N, Mikolajczyk A, Jagiello K, et al. (2018) How the toxicity of nanomaterials towards different species could be simultaneously evaluated: a novel multi-nano-read-across approach. Nanoscale 10: 582–591. https://doi.org/10.1039/C7NR05618D doi: 10.1039/C7NR05618D
|
| [29] |
Lamon L, Aschberger K, Asturiol D, et al. (2019) Grouping of nanomaterials to read-across hazard endpoints: a review. Nanotoxicology 13: 100–118. https://doi.org/10.1080/17435390.2018.1506060 doi: 10.1080/17435390.2018.1506060
|
| [30] |
Ahlers J, Nendza, M, Schwartz D (2019) Environmental hazard and risk assessment of thiochemicals. Application of integrated testing and intelligent assessment strategies (ITS) to fulfil the REACH requirements for aquatic toxicity. Chemosphere 214: 480–490. https://doi.org/10.1016/j.chemosphere.2018.09.082 doi: 10.1016/j.chemosphere.2018.09.082
|
| [31] |
Abe A, Sezaki T, Kinoshita K (2019) Development of a read-across workflow for skin irritation and corrosion predictions. SAR QSAR Environ Res 30: 279–298. https://doi.org/10.1080/1062936X.2019.1595136 doi: 10.1080/1062936X.2019.1595136
|
| [32] |
van Ravenzwaay B, Sperber S, Lemke O, et al. (2016) Metabolomics as read-across tool: a case study with phenoxy herbicides. Reg Toxicol Pharmacol 81: 288–304. https://doi.org/10.1016/j.yrtph.2016.09.013 doi: 10.1016/j.yrtph.2016.09.013
|
| [33] |
Sperber S, Wahl M, Berger F, et al. (2019) Metabolomics as read-across tool: An example with 3-aminopropanol and 2-aminoethanol. Reg Toxicol Pharmacol 108: 104442. https://doi.org/10.1016/j.yrtph.2019.104442 doi: 10.1016/j.yrtph.2019.104442
|
| [34] |
Patlewicz G, Lizarraga LE, Rua D, et al. (2019) Exploring current read-across applications and needs among selected U.S. Federal Agencies. Reg Toxicol Pharmacol 106: 197–209. https://doi.org/10.1016/j.yrtph.2019.05.011 doi: 10.1016/j.yrtph.2019.05.011
|
| [35] | Schupp T (2018) Read across for the derivation of indoor air guidance values supported by PBTK modelling. EXCLI J 17: 1069–1078. |
| [36] |
Stanton K, Kruszewski FH (2016) Quantifying the benefits of using read-across and in silico techniques to fulfill hazard data requirements for chemical categories. Reg Toxicol Pharmacol 81: 250–259. https://doi.org/10.1016/j.yrtph.2016.09.004 doi: 10.1016/j.yrtph.2016.09.004
|
| [37] |
Vink SR, Mikkers J, Bouwman T, et al. (2010) Use of read-across and tiered exposure assessment in risk assessment under REACH—A case study on a phase-in substance. Reg Toxicol Pharmacol 58: 64–71. https://doi.org/10.1016/j.yrtph.2010.04.004 doi: 10.1016/j.yrtph.2010.04.004
|
| [38] |
Franken R, Shandilya N, Marquart H, et al. (2020) Extrapolating the applicability of measurement data on worker inhalation exposure to chemical substances. Ann Work Expo Health 64: 250–269. https://doi.org/10.1093/annweh/wxz097 doi: 10.1093/annweh/wxz097
|
| [39] |
Tolls J, Gomez D, Guhl W, et al. (2016) Estimating emissions from adhesives and sealants uses and manufacturing for environmental risk assessments. Integr Environ Assess Manag 12: 185–194. https://doi.org/10.1002/ieam.1662 doi: 10.1002/ieam.1662
|
| [40] | Allen D, Shonnard DR (2002) Green Engineering: Environmentally Conscious Design of Chemical Processes, Hoboken: Pearson Publishing. |
| [41] |
Meyer DE, Mittal VK, Ingwersen WW, et al. (2019) Purpose-driven reconciliation of approaches to estimate chemical releases. ACS Sustain Chem Eng 7: 1260−1270. https://doi.org/10.1021/acssuschemeng.8b04923 doi: 10.1021/acssuschemeng.8b04923
|
| [42] |
Cashman SA, Meyer DE, Edelen AN, et al. (2016) Mining available data from the United States Environmental Protection Agency to support rapid life cycle inventory modeling of chemical manufacturing. Environ Sci Technol 50: 9013−9025. https://doi.org/10.1021/acs.est.6b02160 doi: 10.1021/acs.est.6b02160
|
| [43] | EPA, Analog Identification Methodology (AIM) Tool. Environmental Protection Agency, n.d. Available from: https://www.epa.gov/tsca-screening-tools/analog-identification-methodology-aim-tool. |
| [44] |
Luechtefeld T, Marsh D, Rowlands C, et al. (2018) Machine learning of toxicological big data enables read-across structure activity relationships (RASAR) outperforming animal test reproducibility. Toxicol Sci 165: 198–212. https://doi.org/10.1093/toxsci/kfy152 doi: 10.1093/toxsci/kfy152
|
| [45] |
Butena D (1999) Unsupervised data base clustering based on daylight's fingerprint and Tanimoto similarity: A fast and automated way to cluster small and large data sets. J Chem Inf Comput Sci 39: 747–750. https://doi.org/10.1021/ci9803381 doi: 10.1021/ci9803381
|
| [46] |
Nicolas CI, Mansouri K, Phillips KA, et al. (2018) Rapid experimental measurements of physicochemical properties to inform models and testing. Sci Total Environ 636: 901–909. https://doi.org/10.1016/j.scitotenv.2018.04.266 doi: 10.1016/j.scitotenv.2018.04.266
|
| [47] |
Blackburn K, Stuard SB (2014) A framework to facilitate consistent characterization of read across uncertainty. Regul Toxicol Pharmacol 68: 353–362. https://doi.org/10.1016/j.yrtph.2014.01.004 doi: 10.1016/j.yrtph.2014.01.004
|
| [48] | Cronin MTD, Madden J, Enoch S, et al. (2013) Chemical Toxicity Prediction: Category Formation and Read-Across, London: Royal Society of Chemistry. https://doi.org/10.1039/9781849734400 |
| [49] |
Escher SE, Kamp H, Bennekou SH, et al. (2019) Towards grouping concepts based on new approach methodologies in chemical hazard assessment: the read‑across approach of the EU‑Tox Risk project. Arch Toxicol 93: 3643–3667. https://doi.org/10.1007/s00204-019-02591-7 doi: 10.1007/s00204-019-02591-7
|
| [50] |
Kuo TW, Tan CS (2001) Alkylation of toluene with propylene in supercritical carbon dioxide over chemical liquid deposition HZSM-5 pellets. Ind Eng Chem Res 40: 4724–4730. https://doi.org/10.1021/ie0104868 doi: 10.1021/ie0104868
|
| [51] | Hwang SY, Chen SS (2010) Cumene, Kirk-Othmer Encyclopedia of Chemical Technology, Hoboken: John Wiley and Sons. https://doi.org/10.1002/0471238961.0321130519030821.a01.pub3 |
| [52] |
Meyer DE, Cashman S, Gaglione A (2021) Improving the reliability of chemical manufacturing life cycle inventory constructed using secondary data. J Ind Ecol 25: 20–35. https://doi.org/10.1111/jiec.13044 doi: 10.1111/jiec.13044
|
| [53] |
Mittal V, Bailin S, Gonzalez M, et al. (2017) Toward automated inventory modeling in life cycle assessment: The utility of semantic data modeling to predict real-world chemical production. ACS Sustain Chem Eng 6: 1961–1976. https://doi.org/10.1021/acssuschemeng.7b03379 doi: 10.1021/acssuschemeng.7b03379
|
| [54] |
Meyer DE, Bailin SC, Vallero D et al. (2020) Enhancing life cycle chemical exposure assessment through ontology modeling. Sci Total Environ 712: 136263. https://doi.org/10.1016/j.scitotenv.2019.136263 doi: 10.1016/j.scitotenv.2019.136263
|
| [55] |
Hernandez-Betancur JD, Martin M, Ruiz-Mercado G (2022) A data engineering approach for sustainable chemical end-of-life management. Resour Conserv Recy 172: 106040. https://doi.org/10.1016/j.resconrec.2021.106040 doi: 10.1016/j.resconrec.2021.106040
|
| [56] |
Sengupta D, Smith R, Abraham J, et al. (2015) Industrial process system assessment: bridging process engineering and life cycle assessment through multiscale modeling. J Clean Prod 90: 142–152. https://doi.org/10.1016/j.jclepro.2014.11.073 doi: 10.1016/j.jclepro.2014.11.073
|
| [57] |
Gonzalez MA, Smith RL (2003) A methodology to evaluate process sustainability. Environ Prog 22: 269–276. https://doi.org/10.1002/ep.670220415 doi: 10.1002/ep.670220415
|
Figures(4) / Tables(3)
Sudhakar Takkellapati, Michael A. Gonzalez. Application of read-across methods as a framework for the estimation of emissions from chemical processes[J]. Clean Technologies and Recycling, 2023, 3(4): 283-300. doi: 10.3934/ctr.2023018







 DownLoad:
DownLoad: