Citation: Anton Velinov. On the importance of testing structural identification schemes and the potential consequences of incorrectly identified models[J]. Quantitative Finance and Economics, 2018, 2(1): 591-611. doi: 10.3934/QFE.2018.1.106

| [1] | Allen D, Yang W (2004) Do UK stock prices deviate from fundamentals? Math comput simul 64: 373-383. |
| [2] | Allen DE, Yang WJ (2001) Variation of share prices due to fundamental and non-fundamental innovations. Int J Bus Stud 1-24. |
| [3] | Amisano G, Giannini C (1997) Topics in structural VAR econometrics. Berl/Heidelb. |
| [4] | Binswanger M (2000) Stock market booms and real economic activity: Is this time different? Int Rev Econ Financ 9: 387-415. |
| [5] | Binswanger M (2004a) How do stock prices respond to fundamental shocks? Financ Res Lett 1: 90-99. |
| [6] | Binswanger M (2004b) How important are fundamentals? Evidence from a structural VAR model for the stock markets in the US, Japan and Europe. J Int Financ Markets, Inst Money 14: 185-201. |
| [7] | Binswanger M(2004c) Stock returns and real activity in the g-7 countries: Did the relationship change during the 1980s? Q Rev Econ Financ 44: 237-252. |
| [8] | Blanchard O, Quah D (1989) The dynamic e ects of aggregate demand and supply disturbances. Am Econ Rev 79: 655-673. |
| [9] | Canova F, De Nicolo G (1995) Stock returns and real activity: A structural approach. European Econ Rev 39: 981-1015. |
| [10] | Cheung Y, Ng L (1998) International evidence on the stock market and aggregate economic activity. J Empir Financ 5: 281-296. |
| [11] | Chung H, Lee B (1998) Fundamental and nonfundamental components in stock prices of pacific-rim countries. Pac-Basin Financ J 6: 321-346. |
| [12] | Erceg CJ, Guerrieri L, Gust C (2005) Can long-run restrictions identify technology shocks? J European Econ Assoc 3: 1237-1278. |
| [13] | Fama EF (1990) Stock returns, expected returns, and real activity. J Financ 45: 1089-1108. |
| [14] | Gospodinov N (2010) Inference in nearly nonstationary SVAR models with long-run identifying restrictions. J Bus Econ Stat 28: 1-12. |
| [15] | Hamilton, J (1994) Time series analysis. Princeton Univ Pr. |
| [16] | Hatipoglu M, Uckun N, Terzi S (2014) The impact of fundamental shocks on stock prices: Evidence from turkey. Res Appl Econ 6: 61-72. |
| [17] | Herwartz H, Lütkepohl H (2014) Structural vector autoregressions with markov switching: Combining conventional with statistical identification of shocks. J Econom 183: 104-116. |
| [18] | Jean R, Eldomiaty T (2010) How do stock prices respond to fundamental shocks in the case of the United States? Evidence from NASDAQ and DJIA. Q Rev Econ Financ 50: 310-322. |
| [19] | Johansen S (1995) Likelihood-based inference in cointegrated vector autoregressive models. Oxford University Press, USA. |
| [20] | King R, Plosser C, Stock J, et al. (1991) Stochastic trends and economic fluctuations. Am Econ Re 81: 819-840. |
| [21] | Krolzig H (1997) Markov-Switching Vector Autoregressions-Modelling. Stat Inference Appl Bus Cycle Anal. |
| [22] | Lanne M, Lütkepohl H (2010) Structural vector autoregressions with nonnormal residuals. J Bus Econ Stat 28: 159-168. |
| [23] | Lanne M, Lütkepohl H, Maciejowska K (2010) Structural vector autoregressions with markov switching. J Econ Dyn Control 34: 121-131. |
| [24] | Laopodis N (2009) Are fundamentals still relevant for european economies in the post-euro period? Econ Model 26: 835-850. |
| [25] | Laopodis NT (2011) Equity prices and macroeconomic fundamentals: International evidence. J Int Financ Markets, Inst Money 21: 247-276. |
| [26] | Lee B (1995a) Fundamentals and bubbles in asset prices: Evidence from us and japanese asset prices. Asia-Pac Financ Markets 2: 89-122. |
| [27] | Lee B (1995b) The response of stock prices to permanent and temporary shocks to dividends. J Financ Quant Anal 30: 1-22. |
| [28] | Lee B (1998) Permanent, temporary, and non-fundamental components of stock prices. J Financ Quant Anal 33: 1-32. |
| [29] | Lee BS (1996) Comovements of earnings, dividends, and stock prices. J Empir Financ 3: 327-346. |
| [30] | Lütkepohl H (2005) New introduction to multiple time series analysis. Springer. |
| [31] | Nasseh A, Strauss J (2000) Stock prices and domestic and international macroeconomic activity: a cointegration approach. Q Rev Econ Financ 40: 229-245. |
| [32] | Pan MS (2007) Permanent and transitory components of earnings, dividends, and stock prices. Q Rev Econ Financ 47: 535-549. |
| [33] | Podstawski M, Velinov A (2018) The state dependent impact of bank exposure on sovereign risk. J Bank Fianc 88: 63-75. |
| [34] | Psaradakis Z, Spagnolo N (2006) Joint determination of the state dimension and autoregressive order for models with markov regime switching. J Time Ser Anal 27: 753-766. |
| [35] | Rapach D (2001) Macro shocks and real stock prices. J Econ Bus 53: 5-26. |
| [36] | Rigobon R (2003) Identification through heteroskedasticity. Rev Econ Stat 85: 777-792. |
| [37] | Saikkonen P, Lütkepohl H (2000) Testing for the cointegrating rank of a var process with structural shifts. J Bus Econ Stat 18: 451-464. |
| [38] | Schwert GW (1990) Stock returns and real activity: A century of evidence. J Financ 45: 1237-1257. |
| [39] | Shiller RJ (1981) Do stock prices move too much to be justified by subsequent changes in dividends? Am Econ Rev 71: 421-436. |
| [40] | Summers LH (1986) Does the stock market rationally reflect fundamental values? J Financ 41: 591-601. |
| [41] | Swanson N, Granger C (1997) Impulse response functions based on a causal approach to residual orthogonalization in vector autoregressions. J Am Stat Assoc 92: 357-367. |
| [42] | Velinov A, Chen W (2015) Do stock prices reflect their fundamentals? new evidence in the aftermath of the financial crisis. J Econ Bus 80: 1-20. |
| [43] | Vlaar P (2004) On the asymptotic distribution of impulse response functions with long-run restrictions. Econom Theory 20: 891-903. |
| [44] | Waggoner DF, Zha T (2003) Likelihood preserving normalization in multiple equation models. J Econom 114: 329-347. |
| [45] | Zhong M, Darrat AF, Anderson DC (2003) Do US stock prices deviate from their fundamental values? Some new evidence. J Bank Financ 27: 673-697. |
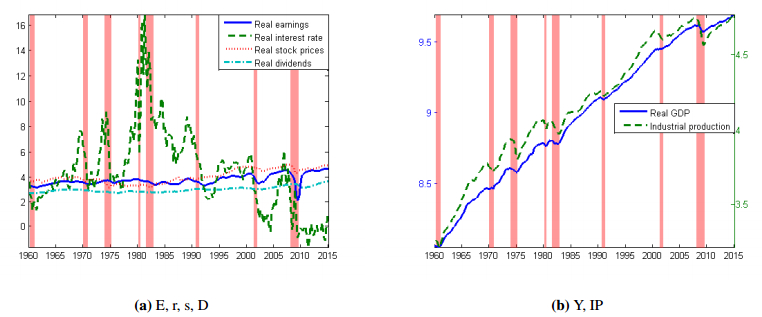
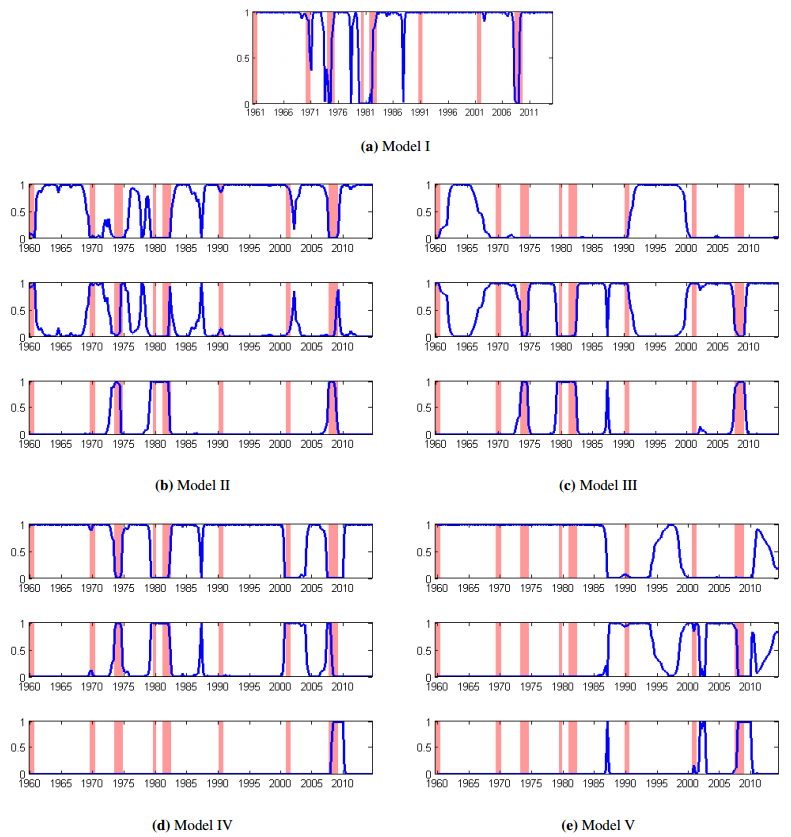
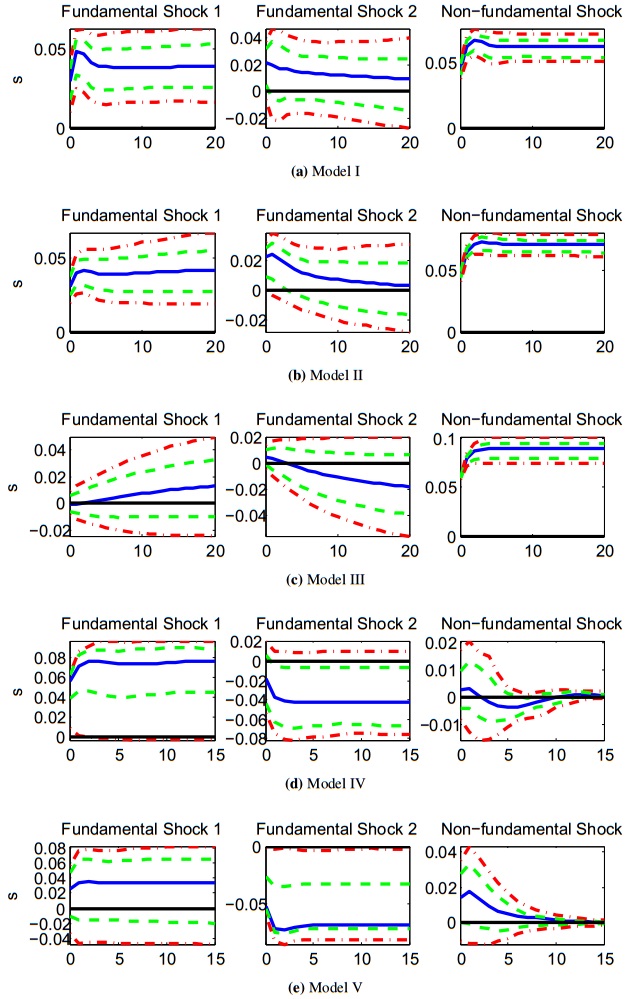
Figures(3) / Tables(8)

Anton Velinov. On the importance of testing structural identification schemes and the potential consequences of incorrectly identified models[J]. Quantitative Finance and Economics, 2018, 2(1): 591-611. doi: 10.3934/QFE.2018.1.106







 DownLoad:
DownLoad: