Citation: Akram Zardadi. Data selection with set-membership affine projection algorithm[J]. AIMS Electronics and Electrical Engineering, 2019, 3(4): 359-369. doi: 10.3934/ElectrEng.2019.4.359

| [1] | Han S, De Maio S, Carotenuto V, et al. (2018) Censoring outliers in radar data: an approximate ML approach and its analysis. IEEE T Aero Elec Sys 55: 534–546. |
| [2] | Diniz PSR, Yazdanpanah H (2017) Data censoring with set-membership algorithms. In: IEEE Global Conference on Signal and Information Processing (GlobalSIP 2017), Montreal, Canada, 121–125. |
| [3] |
Zhu H, Qian H, Luo X, et al. (2018) Adaptive queuing censoring for big data processing. IEEE Signal Proc Let 25: 610–614. doi: 10.1109/LSP.2018.2815006

|
| [4] |
Zheng Y, Niu R, Varshney PK (2014) Sequential bayesian estimation with censored data for multi-sensor systems. IEEE T Signal Proces 62: 2626–2641. doi: 10.1109/TSP.2014.2315163
|
| [5] |
Msechu EJ, Giannakis GB (2012) Sensor-centric data reduction for estimation with WSNs via censoring and quantization. IEEE T Signal Proces 60: 400–414. doi: 10.1109/TSP.2011.2171686
|
| [6] | Fernández-Bes J, Arroyo-Valles R, Cid-Sueiro J (2011) Cooperative data censoring for energy- efficient communications in sensor networks. In: IEEE International Workshop on Machine Learning for Signal Processing, Santander, Spain, 1–6. |
| [7] | Msechu EJ, Giannakis GB (2011) Decentralized data selection for MAP estimation: a censoring and quantization approach. In: 14th International Conference on Information Fusion, Chicago, IL, USA, 1–8. |
| [8] | Yazdanpanah H, Diniz PSR, Lima MVS (2016) A simple set-membership affine projection algorithm for sparse system modeling. In: 24th European Signal Processing Conference (EUSIPCO 2016), Budapest, Hungary, 1798–1802. |
| [9] | Yazdanpanah H, Diniz PSR (2017) Recursive least-squares algorithms for sparse system modeling. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2017), New Orleans, LA, USA, 3879–3883. |
| [10] | Diniz PSR (2013) Adaptive Filtering: Algorithms and Practical Implementation, 4th edition, New York, USA, Springer. |
| [11] |
Gollamudi S, Nagaraj S, Kapoor S, et al. (1998) Set-membership filtering and a set-membership normalized LMS algorithm with an adaptive step size. IEEE Signal Proc Let 5: 111–114. doi: 10.1109/97.668945
|
| [12] |
Gollamudi S, Kapoor S, Nagaraj S, et al. (1998) Set-membership adaptive equalization and updator-shared implementation for multiple channel communications systems. IEEE T Signal Proces 46: 2372–2385. doi: 10.1109/78.709523
|
| [13] |
Werner S, Diniz PSR (2001) Set-membership affine projection algorithm. IEEE Signal Proc Let 8: 231–235. doi: 10.1109/97.935739
|
| [14] | Yazdanpanah H, Diniz PSR (2017) New trinion and quaternion set-membership affine projection algorithms. IEEE T Circuits-II 64: 216–220. |
| [15] | Diniz PSR, Yazdanpanah H (2016) Improved set-membership partial-update affine projection algorithm. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2016), Shanghai, China, 4174–4178. |
| [16] |
Takahashi N, Yamada I (2009) Steady-state mean-square performance analysis of a relaxed set-membership NLMS algorithm by the energy conservation argument. IEEE T Signal Proces 57: 3361–3372. doi: 10.1109/TSP.2009.2020747
|
| [17] |
Bhotto MZA, Antoniou A (2012) A robust constrained set-membership affine-projection adaptive-filtering algorithm. IEEE T Signal Proces 60: 73–81. doi: 10.1109/TSP.2011.2170980
|
| [18] | Deller JR (1989) Set-membership identification in digital signal processing. IEEE ASSP Magazine 6: 4–20. |
| [19] | Nagaraj S, Gollamudi S, Kapoor S, et al. (1999) BEACON: an adaptive set-membership filtering technique with sparse updates, IEEE T Signal Proces 47: 2928–2941. |
| [20] | Yazdanpanah H, Lima MVS, Diniz PSR (2016) On the robustness of the set-membership NLMS algorithm. In: 9th IEEE Sensor Array and Multichannel Signal Processing Workshop (SAM 2016), Rio de Janeiro, Brazil, 1–5. |
| [21] |
Diniz PSR (2018) On Data-Selective Adaptive Filtering. IEEE T Signal Proces 66: 4239–4252. doi: 10.1109/TSP.2018.2847657
|
| [22] |
Lima MVS, Diniz PSR (2013) Steady-state MSE performance of the set-membership affine projection algorithm. Circ Syst Signal Pr 32: 1811–1837. doi: 10.1007/s00034-012-9545-4
|
| [23] | Diniz PSR, Braga RP, Werner S (2006) Set-membership affine projection algorithm for echo cancellation. In: International Symposium on Circuits and Systems (ISCAS 2006), Island of Kos, Greece. |
| [24] | Papoulis A (1991) Probability, Random Variables, and Stochastic Processes, 3rd edition, McGraw Hill, New York, USA. |
| [25] |
Yazdanpanah H, Lima MVS, Diniz PSR (2017) On the robustness of set-membership adaptive filtering algorithms. EURASIP J Adv Sig Pr 2017: 72. doi: 10.1186/s13634-017-0507-7
|
| [26] |
Martins WA, Lima MVS, Diniz PSR, et al. (2017) Optimal constraint vectors for set-membership affine projection algorithms. Signal Process 134: 285–294. doi: 10.1016/j.sigpro.2016.11.025
|
| [27] | Lima MVS, Diniz PSR (2010) Steady-state analysis of the set-membership affine projection algorithm. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2010), Dallas, USA, 3802–3805. |
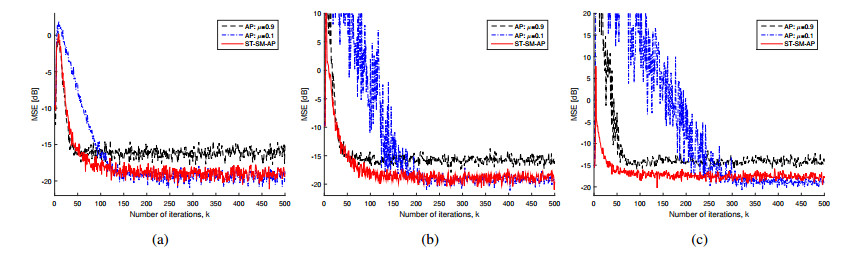
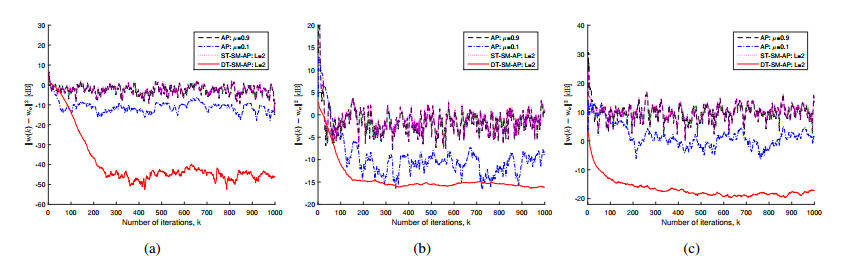
Figures(2) / Tables(3)

Akram Zardadi. Data selection with set-membership affine projection algorithm[J]. AIMS Electronics and Electrical Engineering, 2019, 3(4): 359-369. doi: 10.3934/ElectrEng.2019.4.359







 DownLoad:
DownLoad: