Citation: Yang Zhao, Xin Xie, Xing Zhang, Yi Ding. A revocable storage CP-ABE scheme with constant ciphertext length in cloud storage[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4229-4249. doi: 10.3934/mbe.2019211

| [1] | K. H. Yeh, A secure transaction scheme with certificateless cryptographic primitives for iot-based mobile payments, IEEE Syst. J., 12 (2018), 2027–2038. |
| [2] | Z. Qin, Y. Wang, H. Cheng, et al., Demographic information prediction: a portrait of smartphone application users, IEEE T. Emerg. Top. Com., 6 (2018), 432–444. |
| [3] | H. Xiong, H. Zhang and J. Sun, Attribute-based privacy-preserving data sharing for dynamic groups in cloud computing, IEEE Syst. J., 1–22. |
| [4] | Y. Zhao, M. Ren, S. Jiang, et al., An efficient and revocable storage cp-abe scheme in the cloud computing, Computing, (2018), 1–25. |
| [5] | S. Yu, C. Wang, K. Ren, et al., Attribute based data sharing with attribute revocation, in Proceed-ings of the 5th ACM Symposium on Information, Computer and Communications Security, ACM,(2010), 261–270. |
| [6] | Y. Zhang, D. Zheng, J. Li, et al., Attribute directly-revocable attribute-based encryption with con-stant ciphertext length, J. Cryptologic Res., 1 (2014), 465–480. |
| [7] | Q. Jiang, Y. Qian, J. Ma, et al., User centric three-factor authentication protocol for cloud-assisted wearable devices, Int. J. Commun. Syst., e3900. |
| [8] | H. Xiong, Q. Mei and Y. Zhao, Efficient and provably secure certificateless parallel key-insulated signature without pairing for iiot environments, IEEE Syst. J.. |
| [9] | C. M. Chen, B. Xiang, K. H. Wang, et al., A robust mutual authentication with a key agreement scheme for session initiation protocol, Appl. Sci., 8 (2018), 1789. |
| [10] | J. Sun, Y. Bao, X. Nie, et al., Attribute-hiding predicate encryption with equality test in cloud computing, IEEE Access, 6 (2018), 31621–31629. |
| [11] | H. Xiong, Y. Zhao, L. Peng, et al., Partially policy-hidden attribute-based broadcast encryption with secure delegation in edge computing, Future Gener. Comp. Sy.. |
| [12] | T. Y. Wu, C. M. Chen, K. H. Wang, et al., A provably secure certificateless public key encryption with keyword search, J. Chin. Inst. Eng., 42 (2019), 20–28. |
| [13] | H. Xiong and J. Sun, Comments on verifiable and exculpable outsourced attribute-based encryp-tion for access control in cloud computing, IEEE T. Depend. Secure, 14 (2017), 461–462. |
| [14] | T. Y. Wu, C. M. Chen, K. H. Wang, et al., Security analysis and enhancement of a certificateless searchable public key encryption scheme for iiot environments, IEEE Access, 7 (2019), 49232–49239. |
| [15] | H. Xiong, Q. Wang and J. Sun, Comments on circuit ciphertext-policy attribute-based hybrid en-cryption with verifiable delegation, Inform. Process. Lett., 127 (2017), 67–70. |
| [16] | A. Sahai and B. R. Waters, Fuzzy identity-based encryption., in Eurocrypt, Springer, 3494 (2005), 457–473. |
| [17] | V. Goyal, O. Pandey, A. Sahai, et al., Attribute-based encryption for fine-grained access control of encrypted data, in Proceedings of the 13th ACM conference on Computer and communications security, ACM, (2006), 89–98. |
| [18] | J. Bethencourt, A. Sahai and B. Waters, Ciphertext-policy attribute-based encryption, in Security and Privacy, 2007. SP'07. IEEE Symposium on, IEEE, (2007), 321–334. |
| [19] | L. Cheung and C. Newport, Provably secure ciphertext policy abe, in Proceedings of the 14th ACM conference on Computer and communications security, ACM, (2007), 456–465. |
| [20] | K. Emura, A. Miyaji, A. Nomura, et al., A ciphertext-policy attribute-based encryption scheme with constant ciphertext length., in ISPEC, Springer, 9 (2009), 13–23. |
| [21] | T. Nishide, K. Yoneyama and K. Ohta, Attribute-based encryption with partially hidden encryptor-specified access structures, in International Conference on Applied Cryptography and Network Security, Springer, (2008), 111–129. |
| [22] | C. Chen, J. Chen, H. W. Lim, et al., Fully secure attribute-based systems with short cipher-texts/signatures and threshold access structures, in Cryptographers Track at the RSA Conference, Springer, (2013), 50–67. |
| [23] | N.DoshiandD.C.Jinwala, Fullysecureciphertextpolicyattribute-basedencryptionwithconstant length ciphertext and faster decryption, Secur. Commun. Netw., 7 (2014), 1988–2002. |
| [24] | J. Herranz, F. Laguillaumie and C. Ràfols, Constant size ciphertexts in threshold attribute-based encryption, in International Workshop on Public Key Cryptography, Springer, (2010), 19–34. |
| [25] | Y. Zhang, D. Zheng, X. Chen, et al., Computationally efficient ciphertext-policy attribute-based encryption with constant-size ciphertexts, in International Conference on Provable Security, Springer, (2014), 259–273. |
| [26] | Z. Zhou and D. Huang, On efficient ciphertext-policy attribute based encryption and broadcast en-cryption, in Proceedings of the 17th ACM conference on Computer and communications security, ACM, (2010), 753–755. |
| [27] | M. Pirretti, P. Traynor, P. McDaniel, et al., Secure attribute-based systems, J. Comput. Secur., 18 (2010), 799–837. |
| [28] | N. Attrapadung and H. Imai, Attribute-based encryption supporting direct/indirect revocation modes, in IMA International Conference on Cryptography and Coding, Springer, (2009), 278–300. |
| [29] | M. Naor and B. Pinkas, Efficient trace and revoke schemes, in International Conference on Finan-cial Cryptography, Springer, (2000), 1–20. |
| [30] | D. Boneh, C. Gentry and B. Waters, Collusion resistant broadcast encryption with short ciphertexts and private keys, in Crypto, Springer, 3621 (2005), 258–275. |
| [31] | A. Lewko, A. Sahai and B. Waters, Revocation systems with very small private keys, in 2010 IEEE Symposium on Security and Privacy (SP), IEEE, (2010), 273–285. |
| [32] | A.Sahai, H.SeyaliogluandB.Waters, Dynamiccredentialsandciphertextdelegationforattribute-based encryption, in Advances in Cryptology–CRYPTO 2012, Springer, (2012), 199–217. |
| [33] | M. Green, S. Hohenberger, B. Waters, et al., Outsourcing the decryption of abe ciphertexts., in USENIX Security Symposium, 2011 (2011). |
| [34] | J. Li, X. Huang, J. Li, et al., Securely outsourcing attribute-based encryption with checkability, IEEE T. Parall. Distr., 25 (2014), 2201–2210. |
| [35] | R.Zhang, H.MaandY.Lu, Fine-grainedaccesscontrolsystembasedonfullyoutsourcedattribute-based encryption, J. Syst. Software, 125 (2017), 344–353. |
| [36] | J. Li, C. Jia, J. Li, et al., Outsourcing encryption of attribute-based encryption with mapreduce, in International Conference on Information and Communications Security, Springer, (2012), 191–201. |
| [37] | K. Li and H. Ma, Outsourcing decryption of multi-authority abe ciphertexts, IJ Network Security,16 (2014), 286–294. |
| [38] | B. Qin, R. H. Deng, S. Liu, et al., Attribute-based encryption with efficient verifiable outsourced decryption, IEEE T. Inf. Foren. Sec., 10 (2015), 1384–1393. |
| [39] | J. Lai, R. H. Deng, C. Guan, et al., Attribute-based encryption with verifiable outsourced decryp-tion, IEEE T. Inf. Foren. Sec., 8 (2013), 1343–1354. |
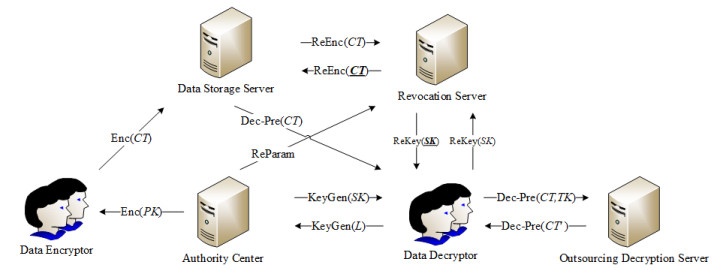
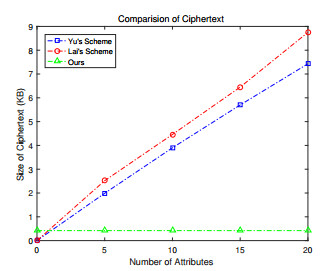

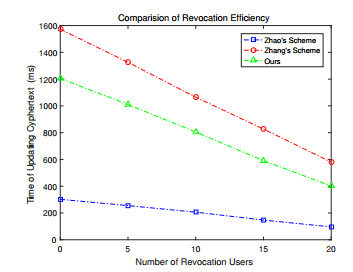
Figures(4) / Tables(6)

Yang Zhao, Xin Xie, Xing Zhang, Yi Ding. A revocable storage CP-ABE scheme with constant ciphertext length in cloud storage[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4229-4249. doi: 10.3934/mbe.2019211







 DownLoad:
DownLoad: