Citation: Alexis Erich S. Almocera, Sze-Bi Hsu, Polly W. Sy. Extinction and uniform persistence in a microbial food web with mycoloop: limiting behavior of a population model with parasitic fungi[J]. Mathematical Biosciences and Engineering, 2019, 16(1): 516-537. doi: 10.3934/mbe.2019024

| [1] | M. Kagami, A. de Bruin, B. W. Ibelings and E. Van Donk, Parasitic chytrids: their effects on phytoplankton communities and food web dynamics, Hydrobiologia, 578 (2007): 113–129. |
| [2] | M. Kagami, N. R. Helmsing and E. Van Donk, Parasitic chytrids could promote copepod survival by mediating material transfer from inedible diatoms, Hydrobiologia, 659 (2011): 49–54. |
| [3] | M. Kagami, T. Miki and G. Takimoto, Mycoloop: chytrids in aquatic food webs, Front. Microbiol., 5 (2014): 166. |
| [4] | M. Kagami, E. von Elert, B. W. Ibelings, A. de Bruin and E. Van Donk, The parasitic chytrid, zygorhizidium, facilitates the growth of the cladoceran zooplankter, daphnia, in cultures of the inedible alga, asterionella, Proceedings of the Royal Society of London B: Biological Science, 274 (2007): 1561–1566. |
| [5] | A. M. Kuris, R. F. Hechinger, J. C. Shaw, K. L. Whitney, L. Aguirre-Macedo, C. A. Boch, A. P. Dobson, E. J. Dunham, B. L. Fredensborg, T. C. Huspeni, J. Lorda, L. Mababa, F. T. Mancini, A. B. Mora, M. Pickering, N. L. Talhouk, M. E. Torchin and K. D. Lafferty, Ecosystem energetic implications of parasite and free-living biomass in three estuaries, Nature, 454 (2008): 515. |
| [6] | K. D. Lafferty, S. Allesina, M. Arim, C. J. Briggs, G. De Leo, A. P. Dobson, J. A. Dunne, P. T. J. Johnson, A. M. Kuris, D. J. Marcogliese, N. D. Martinez, J. Memmott, P. A. Marquet, J. P. McLaughlin, E. A. Mordecai, M. Pascual, R. Poulin, D. W. Thieltges, Parasites in food webs: the ultimate missing links, Ecol. Lett., 11 (2008): 533–546. |
| [7] | D. J. Marcogliese and D. K. Cone, Food webs: a plea for parasites, Trends Ecol. Evol., 12 (1997): 320–325. |
| [8] | I. P. Martines, H. V. Kojouharov and J. P. Grover, A chemostat model of resource competition and allelopathy, Appl. Math. Comput., 215 (2009): 573–582. |
| [9] | T. Miki, G. Takimoto and M. Kagami, Roles of parasitic fungi in aquatic food webs: a theoretical approach, Freshwater Biol., 56 (2011): 1173–1183. |
| [10] | C. J. Rhodes and A. P. Martin, The influence of viral infection on a plankton ecosystem undergoing nutrient enrichment, J. Theor. Biol., 265 (2010): 225–237. |
| [11] | B. K. Singh, J. Chattopadhyay and S. Sinha, The role of virus infection in a simple phytoplankton zooplankton system, J. Theor. Biol., 231 (2004): 153–166. |
| [12] | H. L. Smith and H. R. Thieme, Dynamical systems and population persistence, volume 118, American Mathematical Society, 2011. |
| [13] | H. L. Smith and P. Waltman, The theory of the chemostat: dynamics of microbial competition, volume 13, Cambridge university press, 1995. |
| [14] | R. E. H. Smith and J. Kalff, Size-dependent phosphorus uptake kinetics and cell quota in phytoplankton, J. Phycol., 18 (1982): 275–284. |
| [15] | U. Sommer, R. Adrian, L. D. S. Domis, J. J. Elser, U. Gaedke, B. Ibelings, E. Jeppesen, M. L¨urling, J. C. Molinero, W. M. Mooij, E. van Donk and M. Winder, Beyond the plankton ecology group (peg) model: mechanisms driving plankton succession, Annu. Rev. Ecol. Evol. Syst., 43 (2012): 429–448. |
| [16] | H. R. Thieme, Persistence under relaxed point-dissipativity (with application to an endemic model), SIAM J. Math. Anal., 24 (1993): 407–435. |
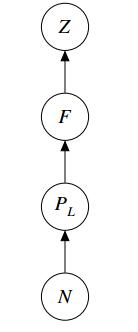
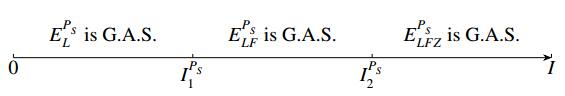
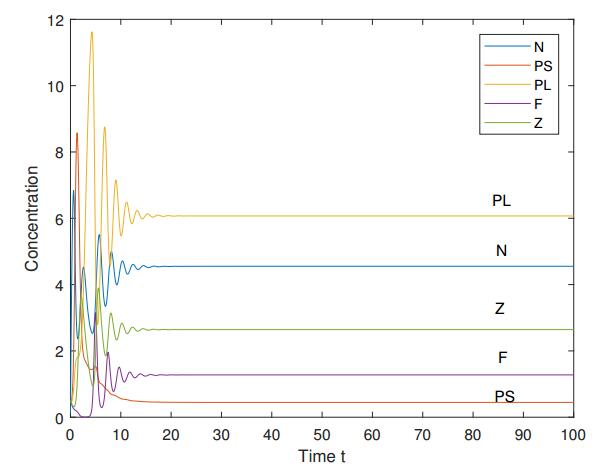
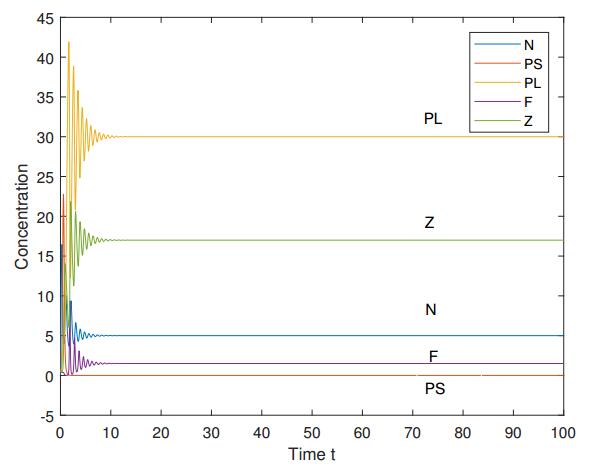
Figures(10) / Tables(2)

Alexis Erich S. Almocera, Sze-Bi Hsu, Polly W. Sy. Extinction and uniform persistence in a microbial food web with mycoloop: limiting behavior of a population model with parasitic fungi[J]. Mathematical Biosciences and Engineering, 2019, 16(1): 516-537. doi: 10.3934/mbe.2019024







 DownLoad:
DownLoad: