Citation: Junyoung Jang, Kihoon Jang, Hee-Dae Kwon, Jeehyun Lee. Feedback control of an HBV model based on ensemble kalman filter and differential evolution[J]. Mathematical Biosciences and Engineering, 2018, 15(3): 667-691. doi: 10.3934/mbe.2018030

| [1] | [ Z. Abbas,A. R. Siddiqui, Management of hepatitis B in developing countries, World Journal of Hepatology, 3 (2011): 292-299. |
| [2] | [ D. Lavanchy, Hepatitis B virus epidemiology, disease burden, treatment, and current and emerging prevention and control measures, Journal of Viral Hepatitis, 11 (2004): 97-107. |
| [3] | [ B. M. Adams,H. T. Banks,M. Davidian,Hee-Dae Kwon,H. T. Tran,S. N. Wynne,E. S. Rosenberg, HIV dynamics: Modeling, data analysis, and optimal treatment protocols, Journal of Computational and Applied Mathematics, 184 (2005): 10-49. |
| [4] | [ K. Blayneh,Y. Cao,H.-D. Kwon, Optimal control of vector-borne diseases: Treatment and prevention, Discrete and Continuous Dynamical Systems-series B, 11 (2009): 587-611. |
| [5] | [ F. Brauer, P. Van den Driessche and J. Wu, Mathematical Epidemiology, Springer-Verlag, Berlin, Heidelberg, 2008. |
| [6] | [ C. Castillo-Chavez, Blower, P. van den Driessche, D. Kirschner and A. -A. Yakubu, Mathematical Approaches for Emerging and Reemerging Infectious Diseases, Springer-Verlag, New York, 2002. |
| [7] | [ F. Daum, Nonlinear filters: beyond the Kalman filter, IEEE Aerospace and Electronic Systems Magazine, 20 (2005): 57-69. |
| [8] | [ G. Evensen, Data Assimilation: The Ensemble Kalman Filter, Springer-Verlag Berlin Heidelberg, 2009. |
| [9] | [ T. Fujimoto,R. R. Ranade, Two Characterizations of Inverse-Positive Matrices: The Hawkins-Simon Condition and the Le Chatelier-Braun Principle, Electronic Journal of Linear Algebra, 11 (2004): 59-65. |
| [10] | [ J. Guedj,Y. Rotman,S. J. Cotler,C. Koh,P. Schmid, Understanding early serum hepatitis D virus and hepatitis B surface antigen kinetics during pegylated interferon-alpha therapy via mathematical modeling, Hepatology, 60 (2014): 1902-1910. |
| [11] | [ L. G. Guidotti,R. Rochford,J. Chung,M. Shapiro,R. Purcell, Viral clearance without destruction of infected cells during acute HBV infection, Science, 284 (1999): 825-829. |
| [12] | [ K. Ito,K. Kunisch, Asymptotic properties of receding horizon optimal control problems, SIAM Journal on Control and Optimization, 40 (2002): 1585-1610. |
| [13] | [ H. Y. Kim, H. -D. Kwon, T. S. Jang, J. Lim and H. Lee, Mathematical modeling of triphasic viral dynamics in patients with HBeAg-positive chronic hepatitis B showing response to 24-week clevudine therapy, PloS One, 7 (2012), e50377. |
| [14] | [ S. B. Kim, M. Yoon, N. S. Ku, M. H. Kim and J. E. Song, et, al., Mathematical modeling of HIV prevention measures including pre-exposure prophylaxis on hiv incidence in south korea, PloS One, 9 (2014), e90080. |
| [15] | [ J. Lee,J. Kim,H.-D. Kwon, Optimal control of an influenza model with seasonal forcing and age-dependent transmission rates, Journal of Theoretical Biology, 317 (2013): 310-320. |
| [16] | [ S. Lee,M. Golinski,G. Chowell, Modeling optimal age-specific vaccination strategies against pandemic influenza, Bulletin of Mathematical Biology, 74 (2012): 958-980. |
| [17] | [ E. Jung,S. Lenhart,Z. Feng, Optimal control of treatments in a two-strain tuberculosis model, Discrete and Continuous Dynamical Systems -Series B, 2 (2002): 473-482. |
| [18] | [ N. K. Martin,P. Vickerman,G. R. Foster,S. J. Hutchinson,D. J. Goldberg,M. Hickman, Can antiviral therapy for hepatitis C reduce the prevalence of HCV among injecting drug user populations? A modeling analysis of its prevention utility, Journal of Hepatology, 54 (2011): 1137-1144. |
| [19] | [ R. Storn,K. Price, Differential evolution -a simple and efficient heuristic for global optimization over continuous spaces, Journal of Global Optimization, 11 (1997): 341-359. |
| [20] | [ R. Thimme,S. Wieland,C. Steiger,J. Ghrayeb,K. A. Reimann, CD8(+) T cells mediate viral clearance and disease pathogenesis during acute hepatitis B virus infection, J. Virol, 77 (2003): 68-76. |
| [21] | [ K. V. Price, R. M. Storn and J. A. Lampinen, Differential Evolution: A Practical Approach to Global Optimization, Springer-Verlag, Berlin, Heidelberg, 2005. |
| [22] | [ Hepatitis B Foudation, http://www.hepb.org. |

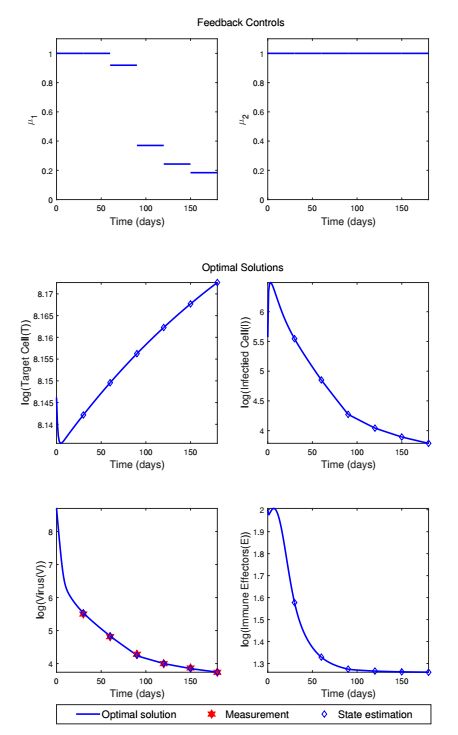
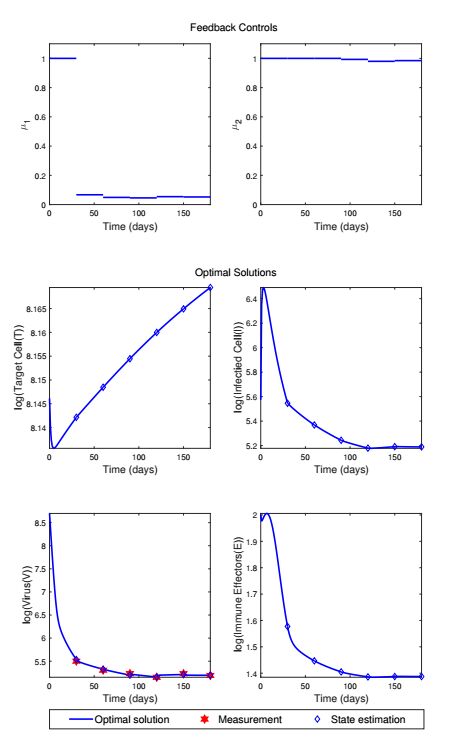
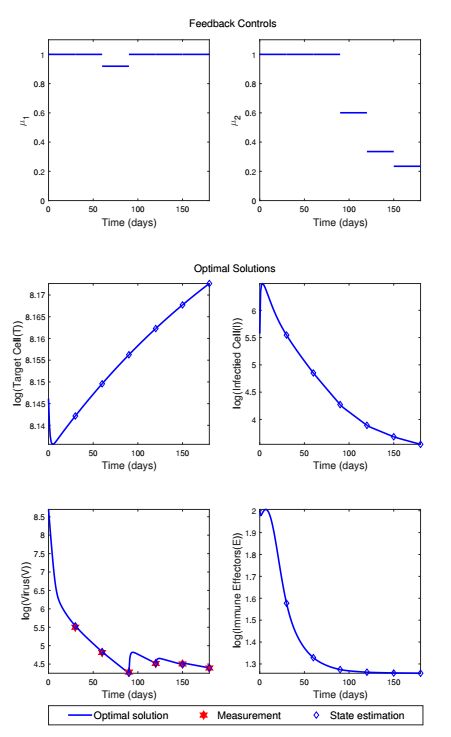
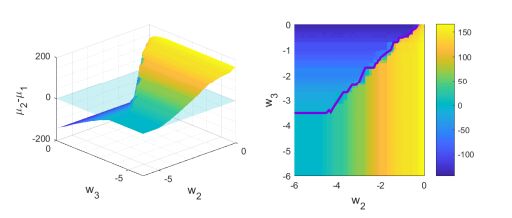
Figures(13) / Tables(1)

Junyoung Jang, Kihoon Jang, Hee-Dae Kwon, Jeehyun Lee. Feedback control of an HBV model based on ensemble kalman filter and differential evolution[J]. Mathematical Biosciences and Engineering, 2018, 15(3): 667-691. doi: 10.3934/mbe.2018030







 DownLoad:
DownLoad: