




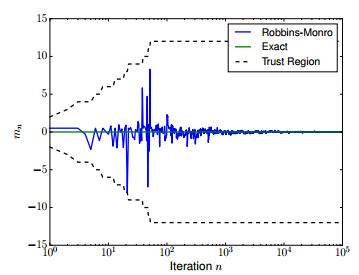
Figure 1.
Robbins-Monro applied to a globally convex scalar problem associated with (4.2) with ϵ=0.1 and expanding trust regions Un=(−1−n,1+n).
Citation: Gideon Simpson, Daniel Watkins. Relative entropy minimization over Hilbert spaces via Robbins-Monro[J]. AIMS Mathematics, 2019, 4(3): 359-383. doi: 10.3934/math.2019.3.359
| [1] | Yan Ling Fu, Wei Zhang . Some results on frames by pre-frame operators in Q-Hilbert spaces. AIMS Mathematics, 2023, 8(12): 28878-28896. doi: 10.3934/math.20231480 |
| [2] | Gang Wang . Some properties of weaving $ K $-frames in $ n $-Hilbert space. AIMS Mathematics, 2024, 9(9): 25438-25456. doi: 10.3934/math.20241242 |
| [3] | Sergio Verdú . Relative information spectra with applications to statistical inference. AIMS Mathematics, 2024, 9(12): 35038-35090. doi: 10.3934/math.20241668 |
| [4] | Ligong Wang . Output statistics, equivocation, and state masking. AIMS Mathematics, 2025, 10(6): 13151-13165. doi: 10.3934/math.2025590 |
| [5] | Cure Arenas Jaffeth, Ferrer Sotelo Kandy, Ferrer Villar Osmin . Functions of bounded $ {\bf (2, k)} $-variation in 2-normed spaces. AIMS Mathematics, 2024, 9(9): 24166-24183. doi: 10.3934/math.20241175 |
| [6] | Chibueze C. Okeke, Abubakar Adamu, Ratthaprom Promkam, Pongsakorn Sunthrayuth . Two-step inertial method for solving split common null point problem with multiple output sets in Hilbert spaces. AIMS Mathematics, 2023, 8(9): 20201-20222. doi: 10.3934/math.20231030 |
| [7] | Osmin Ferrer Villar, Jesús Domínguez Acosta, Edilberto Arroyo Ortiz . Frames associated with an operator in spaces with an indefinite metric. AIMS Mathematics, 2023, 8(7): 15712-15722. doi: 10.3934/math.2023802 |
| [8] | Abdullah Ali H. Ahmadini, Amal S. Hassan, Ahmed N. Zaky, Shokrya S. Alshqaq . Bayesian inference of dynamic cumulative residual entropy from Pareto Ⅱ distribution with application to COVID-19. AIMS Mathematics, 2021, 6(3): 2196-2216. doi: 10.3934/math.2021133 |
| [9] | Messaoud Bounkhel . $ V $-Moreau envelope of nonconvex functions on smooth Banach spaces. AIMS Mathematics, 2024, 9(10): 28589-28610. doi: 10.3934/math.20241387 |
| [10] | Jamilu Adamu, Kanikar Muangchoo, Abbas Ja'afaru Badakaya, Jewaidu Rilwan . On pursuit-evasion differential game problem in a Hilbert space. AIMS Mathematics, 2020, 5(6): 7467-7479. doi: 10.3934/math.2020478 |
In [13,14,15,16,19], it was proposed that insight into a probability distribution, μ, posed on a Hilbert space, H, could be obtained by finding a best fit Gaussian approximation, ν. This notion of best, or optimal, was with respect to the relative entropy, or Kullback-Leibler divergence:
| R(ν||μ)={Eν[logdνdμ],ν≪μ,+∞,otherwise. | (1.1) |
Having a Gaussian approximation provides qualitative insight into μ, as it provides a concrete notion of the mean and variance of the distribution. Additionally, this optimized distribution can be used in algorithms, such as random walk Metropolis, as a preconditioned proposal distribution to improve performance. Such a strategy can benefit a number of applications, including path space sampling for molecular dynamics and parameter estimation in statistical inverse problems.
Observe that in the definition of R, (1.1), there is an asymmetry in the arguments. Were we to work with R(μ||ν), our optimal Gaussian would capture the first and second moments of μ, and in some applications this is desirable. However, for a multimodal problem (consider a distribution with two well separated modes), this would be inadequate; our form attempts to match individual modes of the distribution by a Gaussian. For a recent review of the R(ν||μ) problem, see [4], where it is remarked that this choice of arguments is likely to underestimate the dispersion of the distribution of interest, μ. The other ordering of arguments has been explored, in the finite dimensional case, in [2,3,10,18].
To be of computational use, it is necessary to have an algorithm that will converge to this optimal distribution. In [15], this was accomplished by first expressing ν=N(m,C(p)), where m is the mean and p is a parameter inducing a well defined covariance operator, and then solving the problem,
| (m,p)∈argminR(N(m,C(p))||μ), | (1.2) |
over an admissible set. The optimization step itself was done using the Robbins-Monro algorithm (RM), [17], by seeking a root of the first variation of the relative entropy. While the numerical results of [15] were satisfactory, being consistent with theoretical expectations, no rigorous justification for the application of RM to the examples was given.
In this work, we emphasize the study and application of RM to potentially infinite dimensional problems. Indeed, following the framework of [15,16], we assume that μ is posed on the Borel σ-algebra of a separable Hilbert space (H,⟨∙,∙⟩,‖∙‖). For simplicity, we will leave the covariance operator C fixed, and only optimize over the mean, m. Even in this case, we are seeking m∈H, a potentially infinite-dimensional space.
Given the objective function f:H→H, assume that it has a root, x⋆. In our application to relative entropy, f will be its first variation. Further, we assume that we can only observe a noisy version of f, F:H×χ→H, such that for all x∈H,
| f(x)=E[F(x,Z)]=∫χF(x,z)μZ(dz), | (1.3) |
where μZ is the distribution associated with the random variable (r.v.) Z, taking values in the auxiliary space χ. The naive Robbins-Monro algorithm is given by
| Xn+1=Xn−an+1F(Xn,Zn+1), | (1.4) |
where Zn∼μZ, are independent and identically distributed (i.i.d.), and an>0 is a carefully chosen sequence. Subject to assumptions on f, F, and the distribution μZ, it is known that Xn will converge to x⋆ almost surely (a.s.), in finite dimensions, [5,6,17]. Often, one needs to assume that f grows at most linearly,
| ‖f(x)‖≤c0+c1‖x‖, | (1.5) |
in order to apply the results in the aforementioned papers. The analysis in the finite dimensional case has been refined tremendously over the years, including an analysis based on continuous dynamical systems. We refer the reader to the books [1,8,11] and references therein.
As noted, much of the analysis requires the regression function f to have, at most, linear growth. Alternatively, an a priori assumption is sometimes made that the entire sequence generated by (1.4) stays in a bounded set. Both assumptions are limiting, though, in practice, one may find that the algorithms converge.
One way of overcoming these assumptions, while still ensuring convergence, is to introduce trust regions that the sequence {Xn} is permitted to explore, along with a "truncation" which enforces the constraint. Such truncations distort (1.4) into
| Xn+1=Xn−an+1F(Xn,Zn+1)+an+1Pn+1, | (1.6) |
where Pn+1 is the projection keeping the sequence {Xn} within the trust region. Projection algorithms are also discussed in [1,8,11].
We consider RM on a possibly infinite dimensional separable Hilbert space. This is of particular interest as, in the context of relative entropy optimization, we may be seeking a distribution in a Sobolev space associated with a PDE model. A general analysis of RM with truncations in Hilbert spaces can be found in [20]. The main purpose of this work is to adapt the analysis of [12] to the Hilbert space setting for two versions of the truncated problem. The motivation for this is that the analysis of [12] is quite straightforward, and it is instructive to see how it can be easily adapted to the infinite dimensional setting. The key modification in the proof is that results for Banach space valued martingales must be invoked. We also adapt the results to a version of the algorithm where there is prior knowledge on the location of the root. With these results in hand, we can then verify that the relative entropy minimization problem can be solved using RM.
In some problems, one may have a priori information on the root. For instance, we may know that x⋆∈U1, some open bounded set. In this version of the truncated algorithm, we have two open bounded sets, U0⊊U1, and x⋆∈U1. Let σ0=0 and X0∈U0 be given, then (1.6) can be formulated as
| ˜Xn+1=Xn−an+1F(Xn,Zn+1) | (1.7a) |
| Xn+1={˜Xn+1˜Xn+1∈U1X(σn)0˜Xn+1∉U1 | (1.7b) |
| σn+1={σn˜Xn+1∈U1σn+1˜Xn+1∉U1 | (1.7c) |
We interpret ˜Xn+1 as the proposed move, which is either accepted or rejected depending on whether or not it will remain in the trust region. If it is rejected, the algorithm restarts at X(σn)0∈U0. The restart points, {X(σn)0}, may be random, or it may be that X(σn)0=X0 is fixed. The essential property is that the algorithm will restart in the interior of the trust region, away from its boundary. The r.v. σn counts the number of times a truncation has occurred. Algorithm (1.7) can now be expressed as
| Xn+1=Xn−an+1F(Xn,Zn+1)+Pn+1Pn+1={X(σn)0−˜Xn+1}1˜Xn+1∉U1. | (1.8) |
In the second version of truncated Robbins-Monro, define the sequence of open bounded sets, Un such that:
| U0⊊U1⊊U2⊊…,∪∞n=0Un=H. | (1.9) |
Again, letting X0∈U0, σ0=0, the algorithm is
| ˜Xn+1=Xn−an+1F(Xn,Zn+1) | (1.10a) |
| Xn+1={˜Xn+1˜Xn+1∈UσnX(σn)0˜Xn+1∉Uσn | (1.10b) |
| σn+1={σn˜Xn+1∈Uσnσn+1˜Xn+1∉Uσn | (1.10c) |
A consequence of this formulation is that Xn∈Uσn for all n. As before, the restart points may be random or fixed, and they are in U0. This would appear superior to the fixed trust region algorithm, as it does not require knowledge of the sets. However, to guarantee convergence, global (in H) assumptions on the regression function are required; see Assumption 2 below. (1.10) can written with Pn+1 as
| Xn+1=Xn−an+1F(Xn,Zn+1)+Pn+1Pn+1={X(σn)0−˜Xn+1}1˜Xn+1∉Uσn | (1.11) |
In Section 2, we state sufficient assumptions for which we are able to prove convergence in both the fixed and expanding trust region problems, and we also establish some preliminary results. In Section 3, we focus on the relative entropy minimization problem, and identify what assumptions must hold for convergence to be guaranteed. Examples are then presented in Section 4, and we conclude with remarks in Section 5.
We first reformulate (1.8) and (1.15) in the more general form
| Xn+1=Xn−an+1f(Xn)−an+1δMn+1⏟=˜Xn+1+an+1Pn+1, | (2.1) |
where δMn+1, the noise term, is
| δMn+1=F(Xn,Zn+1)−f(Xn)=F(Xn,Zn+1)−E[F(Xn,Zn+1)∣Xn]. | (2.2) |
A natural filtration for this problem is Fn=σ(X0,Z1,…,Zn). Xn is Fn measurable and the noise term can be expressed in terms of the filtration as δMn+1=F(Xn,Zn+1)−E[F(Xn,Zn+1)∣Fn].
We now state our main assumptions:
Assumption 1. f has a zero, x⋆. In the case of the fixed trust region problem, there exist R0<R1 such that
| U0⊆BR0(x⋆)⊂BR1(x⋆)⊆U1. |
In the case of the expanding trust region problem, the open sets are defined as Un=Brn(0) with
| 0<r0<r1<r2<…<rn→∞. | (2.3) |
These sets clearly satisfy (1.9).
Assumption 2. For any 0<a<A, there exists δ>0:
| infa≤‖x−x⋆‖≤A⟨x−x⋆,f(x)⟩≥δ. |
In the case of the fixed truncation, this inequality is restricted to x∈U1. This is akin to a convexity condition on a functional F with f=DF.
Assumption 3. x↦E[‖F(x,Z)‖2] is bounded on bounded sets, with the restriction to U1 in the case of fixed trust regions.
Assumption 4. an>0, ∑an=∞, and ∑a2n<∞
Theorem 2.1. Under the above assumptions, for the fixed trust region problem, Xn→x⋆ a.s. and σn is a.s. finite.
Theorem 2.2. Under the above assumptions, for the expanding trust region problem, Xn→x⋆ a.s. and σn is a.s. finite.
Note the distinction between the assumptions in the two algorithms. In the fixed truncation algorithm, Assumptions 2 and 3 need only hold in the set U1, while in the expanding truncation algorithm, they must hold in all of H. While this would seem to be a weaker condition, it requires identification of the sets U0 and U1 for which the assumptions hold. Such sets may not be readily identifiable, as we will see in our examples.
We first need some additional information about f and the noise sequence δMn.
Lemma 2.1. Under Assumption 3, f is bounded on U1, for the fixed trust region problem, and on arbitrary bounded sets, for the expanding trust region problem.
Proof. Trivially,
| ‖f(x)‖=‖E[F(x,Z)]‖≤E[‖F(x,Z)‖]≤√E[‖F(x,Z)‖2], |
and the results follows from the assumption.
Proposition 2.1. For the fixed trust region problem, let
| Mn=n∑i=1aiδMi. |
Alternatively, in the expanding trust region problem, for r>0, let
| Mn=n∑i=1aiδMi1‖Xi−1−x⋆‖≤r. |
Under Assumptions 3 and 4, Mn is a martingale, converging in H, a.s.
Proof. The following argument holds in both the fixed and expanding trust region problems, with appropriate modifications. We present the expanding trust region case. The proof is broken up into 3 steps:
1. Relying on Theorem 6 of [7] for Banach space valued martingales, it will be sufficient to show that Mn is a martingale, uniformly bounded in L1(P).
2. In the case of the expanding truncations,
| E[‖δMi1‖Xi−1−x⋆‖≤r‖2]≤2E[‖F(Xi−1,Zi)1‖Xi−1−x⋆‖≤r‖2]+2E[‖f(Xi−1)1‖Xi−1−x⋆‖≤r‖2]≤2sup‖x−x⋆‖≤rE[‖F(x,Z)‖2]+2sup‖x−x⋆‖≤r‖f(x)‖2 |
Since both of these terms are bounded, independently of i, by Assumption 3 and Lemma 1, this is finite.
3. Next, since {δMi1‖Xi−1−x⋆‖≤r} is a martingale difference sequence, we can use the above estimate to obtain the uniform L2(P) bound,
| E[‖Mn‖2]=n∑i=1a2iE[‖δMi1‖Xi−1−x⋆‖≤r‖2]≤supiE[‖δMi1‖Xi−1−x⋆‖≤r‖2]∞∑i=1a2i<∞ |
Uniform boundedness in L2, gives boundedness in L1, and this implies a.s. convergence in H.
In this section we prove results showing that only finitely many truncations will occur, in either the fixed or expanding trust region case. Recall that when a truncation occurs, the equivalent conditions hold: Pn+1≠0; σn+1=σn+1; and ˜Xn+1∉U1 in the fixed trust region algorithm, while ˜Xn+1∉Uσn in the expanding trust region case.
Lemma 2.2. In the fixed trust region algorithm, if Assumptions 1, 2, 3, and 4 hold, then the number of truncations is a.s. finite; a.s., there exists N, such that for all n≥N, σn=σN.
Proof. We break the proof up into 7 steps:
1. Pick ρ and ρ′ such that
| R0<ρ′<ρ<R1 | (2.4) |
Let ˉf=sup‖f(x)‖, with the supremum over U1; this bound exists by Lemma 1. Under Assumption 2, there exists δ>0 such that
| infR0/2≤‖x−x⋆‖≤R1⟨x−x⋆,f(x)⟩=δ. | (2.5) |
Having fixed ρ, ρ′, ˉf, and δ, take ϵ>0 such that:
| ϵ<min{ρ′−R0,R1−ρ′2+ˉf,ρ′−R0ˉf,R02,δ2ˉf,δˉf2,ρ−ρ′}. | (2.6) |
Having fixed such an ϵ, by the assumptions of this lemma and Proposition 1, a.s., there exists nϵ such that for any n,m≥nϵ, both
| ‖m∑k=nakδMk‖≤ϵ,an≤ϵ. | (2.7) |
2. Define the auxiliary sequence
| X′n=Xn−∞∑k=n+1akδMk. | (2.8) |
Using (2.1), we can then write
| X′n+1=X′n−an+1f(Xn)+an+1Pn+1. | (2.9) |
By (2.7), for any n≥nϵ,
| ‖X′n−Xn‖≤ϵ | (2.10) |
3. We will show X′n∈Bρ′(x⋆) for all n large enough. The significance of this is that if n≥nϵ, and X′n∈Bρ′(x⋆), then no truncation occurs. Indeed, using (2.6)
| ‖˜Xn+1−x⋆‖≤‖X′n−x⋆‖+‖Xn−X′n‖+an+1ˉf+‖an+1δMn+1‖<ρ′+ϵ+ϵˉf+ϵ<R1,⇒˜Xn+1∈U1. | (2.11) |
Consequently, Pn+1=0, Xn+1=˜Xn+1, and σn+1=σn. Thus, establishing X′n∈Bρ′(x⋆) will yield the result.
4. Let
| N=inf{n≥nϵ∣˜Xn+1∉U1}+1 | (2.12) |
This corresponds to the the first truncation after nϵ. If the above set is empty, for that realization, no truncations occur after nϵ, and we are done. In such a case, we may take N=nϵ in the statement of the lemma.
5. We now prove by induction that in the case that (2.12) is finite, X′n∈Bρ′(x⋆) for all n≥N. First, note that XN∈BR0(x⋆)⊂Bρ(x⋆). By (2.6) and (2.10),
| ‖X′N−x⋆‖≤‖XN−x⋆‖+‖X′N−XN‖<R0+ϵ<ρ′,⇒X′N∈Bρ′(x⋆). |
Next, assume X′N,X′N+1,…,X′n are all in Bρ′(x⋆). Using (2.11), we have that PN+1=…=Pn+1=0 and σN=…=σn=σn+1. Therefore,
| ‖X′n+1−x⋆‖2=‖X′n−x⋆‖2−2an+1⟨X′n−x⋆,f(Xn)⟩+a2n+1‖f(Xn)‖2≤‖X′n−x⋆‖2−2an+1⟨X′n−x⋆,f(Xn)⟩+an+1ϵˉf2 | (2.13) |
We now consider two cases of (2.13) to conclude ‖X′n+1−x⋆‖<ρ′.
6. In the first case, ‖X′n−x⋆‖≤R0. By Cauchy-Schwarz and (2.6)
| ‖X′n+1−x⋆‖2<R20+2ϵR0ˉf+ϵ2ˉf2=(R0+ϵˉf)2<(ρ′)2. |
In the second case, R0<‖X′n−x⋆‖<ρ′. Dissecting the inner product term in (2.13) and using Assumption 2 and (2.10),
| ⟨X′n−x⋆,f(Xn)⟩=⟨Xn−x⋆,f(Xn)⟩+⟨X′n−Xn,f(Xn)⟩≥⟨Xn−x⋆,f(Xn)⟩−ˉfϵ | (2.14) |
Conditions (2.6) and (2.10) yield the following upper and lower bounds:
| ‖Xn−x⋆‖≥‖X′n−x⋆‖−‖X′n−Xn‖≥R0−ϵ>12R0,‖Xn−x⋆‖≤‖X′n−x⋆‖+‖X′n−Xn‖≤ρ′+ϵ<ρ<R1. |
Therefore, (2.5) applies and ⟨Xn−x⋆,f(Xn)⟩≥δ. Using this in (2.14), and condition (2.6),
| ⟨X′n−x⋆,f(Xn)⟩≥δ−ˉfϵ>12δ. |
Substituting this last estimate back into (2.13), and using (2.6),
| ‖X′n+1−x⋆‖2<(ρ′)2−an+1(δ−ϵˉf2)<(ρ′)2. |
This completes the inductive step.
7. Since the auxiliary sequence remains in Bρ′(x⋆) for all n≥N>nϵ, (2.11) ensures ˜Xn+1∈BR1(x⋆), Pn+1=0, and σn+1=σN, a.s.
To obtain a similar result for the expanding trust region problem, we first relate the finiteness of the number of truncations with the sequence persisting in a bounded set.
Lemma 2.3. In the expanding trust region algorithm, if Assumptions 1, 3, and 4 hold, then the sequence remains in a set of the form BR(0) for some R>0 if and only if the number of truncations is finite, a.s.
Proof. We break this proof into 4 steps:
1. If the number of truncations is finite, then there exists N such that for all n≥N, σn=σN. Consequently, the proposed moves are always accepted, and Xn∈Uσn=UσN for all n≥N. Since Xn∈Uσn⊂UσN for n<N, Xn∈UσN for all n. By Assumption 3, BR(0)=BrσN(0)=UσN is the desired set.
2. For the other direction, assume that there exists R>0 such that Xn∈BR(0) for all n. Since the rn in (2.3) tend to infinity, there exists N1, such that R<R+1<rN1. Hence, for all n≥N1,
| BR(0)⊂BR+1(0)⊂Un | (2.15) |
Let ˉf=sup‖f(x)‖, with the supremum over BR(0). Let ˜R be sufficiently large such that BR+1(0)⊂B˜R(x⋆). Lastly, using Proposition 1 and Assumption 4, a.s., there exists N2, such that for all n≥N2
| ‖anδMn1‖Xn−x⋆‖≤˜R‖<12,an<12(1+ˉf) | (2.16) |
Since Xn∈BR(0)⊂B˜R(x⋆), the indicator function in (2.16) is always one, and ‖anδMn‖<1/2.
3. Next, let
| N=inf{n≥0∣σn≥max{N1,N2}} | (2.17) |
If the above set is empty, then σn<max{N1,N2} for all n, and the number of truncations is a.s. finite. In this case, the proof is complete.
4. If the set in (2.17) is not empy, then N<∞. Take n≥N. As Xn∈BR(0), and since n≥σn≥max{N1,N2}, (2.16) applies. Therefore,
| ‖˜Xn+1‖≤‖Xn‖+‖˜Xn+1−Xn‖≤‖Xn‖+an+1‖f(Xn)‖+‖an+1δMn+1‖<R+12+12<R+1. | (2.18) |
Thus, ˜Xn+1∈BR+1(0)⊂UN1, σn≥N1, and UN1⊂Uσn. Therefore, ˜Xn+1∈Uσn. No truncation occurs, and σn=σn+1. Since this holds for all n≥N, σn=σN, and the number of truncations is a.s. finite.
Next, we establish that, subject to an additional assumption, the sequence remains in a bounded set; the finiteness of the truncations is then a corollary.
Lemma 2.4. In the expanding trust region algorithm, if Assumptions 1, 2, 3, and 4 hold, and for any r>0, there a.s. exists N<∞, such that for all n≥N,
| Pn+11‖Xn−x⋆‖≤r=0, |
then {Xn} remains in a bounded open set, a.s.
Proof. We break this proof into 7 steps:
1. We begin by setting some constants for the rest of the proof. Fix R>0 sufficiently large such that BR(x⋆)⊃U0. Next, let ˉf=sup‖f(x)‖ with the supremum taken over BR+2(x⋆). Assumption 2 ensures there exists δ>0 such that
| infR/2≤‖x−x⋆‖≤R+2⟨x−x⋆,f(x)⟩=δ. | (2.19) |
Having fixed R, ˉf, and δ, take ϵ>0 such that:
| ϵ<min{1,1ˉf,δ2ˉf,δˉf2,R2}. | (2.20) |
By the assumptions of this lemma and Proposition 1 there exists, a.s., nϵ≥N such that for all n≥nϵ,
| ‖∞∑i=n+1aiδMi1‖Xi−1−x⋆‖≤R+2‖≤ϵ, | (2.21a) |
| Pn+11‖Xn−x⋆‖≤R+2=0, | (2.21b) |
| an+1≤ϵ | (2.21c) |
2. Define the modified sequence for n≥nϵ as
| X′n=Xn−∞∑k=n+1akδMk1‖Xk−1−x⋆‖≤R+2,⇒‖X′n−Xn‖≤ϵ. | (2.22) |
Using (2.1), we have the iteration
| X′n+1=X′n−an+1δMn+11‖Xn−x⋆‖>R+2−an+1f(Xn)+an+1Pn+1. | (2.23) |
3. Let
| N=inf{n≥nϵ∣σn+1≠σn}+1, | (2.24) |
the first time after nϵ that a truncation occurs.
If the above set is empty, no truncations occur after nϵ. In this case, σn=σnϵ≤nϵ<∞ for all n≥nϵ. Therefore, for all n≥nϵ, Xn∈Uσn⊂Uσnϵ. Since Uσn⊂Uσnϵ for all n<nϵ too, the proof is complete in this case.
4. Now assume that N<∞. We will show that {X′n} remains in BR+1(x⋆) for all n≥N. Were this to hold, then for n≥N,
| ‖Xn−x⋆‖≤‖X′n−x⋆‖+‖∞∑i=n+1aiδMi1‖Xi−1−x⋆‖≤R+2‖<R+1+ϵ<R+2, | (2.25) |
having used (2.21) and (2.22). For n<N, Xn∈Uσn⊂UσN=BrN(0). Therefore, for all n, Xn∈B˜R(0) where ˜R=max{rN,‖x⋆‖+R+2}.
5. We prove X′n∈BR+1(x⋆) by induction. First, since ϵ<1 and XN∈U0⊂BR(x⋆),
| ‖X′N−x⋆‖≤‖X′N−XN‖+‖XN−x⋆‖<ϵ+R<R+1. |
Next, assume that X′N,X′N+1,…,X′n are all in BR+1(x⋆). By (2.25), Xn∈BR+2(x⋆). Since Pn+11‖Xn−x⋆‖≤R+2=0, we conclude Pn+1=0. The modified iteration (2.23) simplifies to have
| X′n+1=X′n−an+1f(Xn), |
and
| ‖X′n+1−x⋆‖2=‖X′n−x⋆‖2−2an+1⟨X′n−x⋆,f(Xn)⟩+a2n+1‖f(Xn)‖2<‖X′n−x⋆‖2−2an+1⟨X′n−x⋆,f(Xn)⟩+an+1ϵˉf2. | (2.26) |
6. We now consider two cases of (2.26). First, assume ‖X′n−x⋆‖≤R. Then (2.26) can immediately be bounded as
| ‖X′n+1−x⋆‖2<R2+2ϵRˉf+ϵ2ˉf2=(R+ϵˉf)2<(R+1)2, |
where we have used condition (2.20) in the last inequality.
7. Now consider the case R<‖X′n−x⋆‖<R+1. Using (2.20), the inner product in (2.26) can first be bounded from below:
| ⟨X′n−x⋆,f(Xn)⟩=⟨Xn−x⋆,f(Xn)⟩+⟨X′n−Xn,f(Xn)⟩≥⟨Xn−x⋆,f(Xn)⟩−ϵˉf>⟨Xn−x⋆,f(Xn)⟩−12δ. |
Next, using (2.20)
| ‖Xn−x⋆‖≥‖X′n−x⋆‖−‖Xn−X′n‖>R−ϵ>R−12R=12R |
Therefore, 12R<‖Xn−x⋆‖<R+2, so (2.19) ensures ⟨Xn−x⋆,f(Xn)⟩≥δ and
| ⟨X′n−x⋆,f(Xn)⟩>δ−12δ=12δ. |
Returning to (2.26), by (2.20),
| ‖X′n+1−x⋆‖2≤(R+1)2−an+1(δ−ϵˉf2)<(R+1)2. |
This completes the proof of the inductive step in this second case, completing the proof.
Corollary 2.1. For the expanding trust region algorithm, if Assumptions 1, 2, 3, and 4 hold, then the number of truncations is a.s. finite.
Proof. The proof is by contradiction. We break the proof into 4 steps:
1. Assuming that there are infinitely many truncations, Lemma 3 implies that the sequence cannot remain in a bounded set. Then, continuing to assume that Assumptions 1, 2, 3, and 4 hold, the only way for the conclusion of Lemma 4 to fail is if the assumption on Pn+11‖Xn−x⋆‖≤r is false. Therefore, there exists r>0 and a set of positive measure on which a subsequence, Pnk+11‖Xnk−x⋆‖≤r≠0. Hence Xnk∈Br(x⋆), and Pnk+1≠0. So truncations occur at these indices, and ˜Xnk+1∉Uσnk.
2. Let ˉf=sup‖f(x)‖ with the supremum over the set Br(x⋆) and let ϵ>0 satisfy
| ϵ<(ˉf+1)−1. | (2.27) |
By our assumptions of the lemma and Proposition 1, there exists nϵ such that for all n≥nϵ
| ‖an+1δMn+11‖Xn−x⋆‖≤r‖≤ϵ,an+1≤ϵ | (2.28) |
Along the subsequence, for all nk≥nϵ,
| ‖ank+1δMnk+11‖Xnk−x⋆‖≤r‖=‖ank+1δMnk+1‖≤ϵ. | (2.29) |
3. Furthermore, for nk≥nϵ:
| ‖˜Xnk+1−x⋆‖≤‖Xnk−x⋆‖+ank+1‖f(Xnk)‖+‖ank+1δMnk+1‖<r+ϵˉf+ϵ<r+1,⇒˜Xnk+1∈Br+1(x⋆), | (2.30) |
where (2.27) has been used in the last inequality.
4. By the definition of the Un, there exists an index M such that UM⊃Br+1(x⋆). Let
| N=inf{n≥nϵ∣σn≥M}. | (2.31) |
This set is nonempty and N<∞ since we have assumed there are infinitely many truncations. Let nk≥N. Then σnk≥M and Uσnk⊃Br+1(x⋆). But (2.30) then implies that ˜Xnk+1∈Uσnk, and no truncation will occur; Pnk+1=0, providing the desired the contradiction.
Using the above results, we are able to prove Theorems 2.1 and 2.2. Since the proofs are quite similar, we present the more complicated expanding trust region case.
Proof. We split this proof into 6 steps:
1. First, by Corollary 1, only finitely many truncations occur. By Lemma 3, there exists R>0 such that Xn∈BR(0) for all n. Consequently, there is an r such that Xn∈Br(x⋆) for all n.
2. Next, we fix constants. Let ˉf=sup‖f(x)‖ with the supremum taken over Br(x⋆). Fix η∈(0,2R), and use Assumption 2 to determine δ>0 such that
| infη/2≤‖x−x⋆‖≤r⟨x−x⋆,f(x)⟩=δ | (2.32) |
Take ϵ>0 such that:
| ϵ<min{1,η2,δ2ˉf,δ2ˉf2} | (2.33) |
Having set ϵ, we again appeal to Assumption 4 and Proposition 1 to find nϵ such that for all n≥nϵ:
| ‖∞∑i=n+1aiδMi1‖Xi−1−x⋆‖≤r‖=‖∞∑i=n+1aiδMi‖≤ϵ,an+1≤ϵ | (2.34) |
3. Define the auxiliary sequence,
| X′n=Xn−∞∑i=n+1aiδMi1‖Xi−1−x⋆‖≤r=Xn−∞∑i=n+1aiδMi. | (2.35) |
Since there are only finitely many truncations, there exists N≥nϵ, such that for all n≥N, Pn+1=0, as the truncations have ceased. Consequently, for n≥N,
| X′n+1=X′n−an+1f(Xn) | (2.36) |
By (2.34) and (2.35), for n≥N, ‖Xn−X′n‖≤ϵ. Since ϵ>0 may be arbitrarily small, it will be sufficient to prove X′n→x⋆.
4. To obtain convergence of X′n, we first examine ‖X′n+1−x⋆‖. For n≥N,
| ‖X′n+1−x⋆‖2≤‖X′n−x⋆‖2−2an+1⟨X′n−x⋆,f(Xn)⟩+an+1ϵˉf2, | (2.37) |
Now consider two cases of this expression. First, assume ‖X′n−x⋆‖≤η. In this case, using (2.33),
| −2an+1⟨X′n−x⋆,f(Xn)⟩+an+1ϵˉf2≤an+1(2ηˉf+ϵˉf2)<an+1(4Rˉf+ˉf2)=an+1B. | (2.38) |
where B>0 is a constant depending only on R and ˉf. For ‖X′n−x⋆‖>η, using (2.33)
| ⟨X′n−x⋆,f(Xn)⟩=⟨Xn−x⋆,f(Xn)⟩+⟨X′n−Xn,f(Xn)⟩≥⟨Xn−x⋆,f(Xn)⟩−ϵˉf>⟨Xn−x⋆,f(Xn)⟩−12δ. | (2.39) |
By (2.33),
| ‖Xn−x⋆‖≥‖X′n−x⋆‖−‖Xn−X′n‖>η−ϵ>12η |
Since ‖Xn−x⋆‖<r too, (2.32) and (2.39) yield the estimate
| ⟨X′n−x⋆,f(Xn)⟩>δ−ϵˉf>12δ |
Thus, in this regime, using (2.33),
| −2an+1⟨X′n−x⋆,f(Xn)⟩+an+1ϵˉf2≤−an+1(δ−ϵˉf2)<−12δan+1=−Aan+1 | (2.40) |
where A>0 is a constant depending only on δ.
Combining estimates (2.38) and (2.40), we can write for n≥N
| ‖X′n+1−x⋆‖2<‖X′n−x⋆‖2−an+1A1‖X′n−x⋆‖>η+an+1B1‖X′n−x⋆‖≤η. | (2.41) |
5. We now show that ‖X′n−x⋆‖≤η i.o. The argument is by contradiction. Let M≥N be such that for all n≥M, ‖X′n−x⋆‖>η. For such n,
| η2<‖X′n+1−x⋆‖2<‖X′n−x⋆‖2−an+1A<‖X′n−1−x⋆‖2−an+1A−anA<…<‖X′M−x⋆‖2−An∑i=Mai+1. | (2.42) |
Using Assumption 4 and taking n→∞, we obtain a contradiction.
6. Finally, we prove convergence of X′n→x⋆. Since X′n∈Bη(x⋆) i.o., let
| N′=inf{n≥N∣‖X′n−x⋆‖<η}. | (2.43) |
For n≥N′, we can then define
| φ(n)=max{p≤n∣‖X′p−x⋆‖<η}. | (2.44) |
For all such n, φ(n)≤n, and X′φ(n)∈Bη(x⋆).
We claim that for n≥N′,
| ‖X′n+1−x⋆‖2<‖X′φ(n)−x⋆‖2+Baφ(n)+1<η2+Baφ(n)+1. |
First, if n=φ(n), this trivially holds in (2.41). Suppose now that n>φ(n). Then for i=φ(n)+1,φ(n)+2,…n, ‖X′i−x⋆‖>η. Consequently,
| ‖X′n+1−x⋆‖2<‖X′n−x⋆‖2<‖X′n−1−x⋆‖2<…<‖X′φ(n)+1−x⋆‖2<‖X′φ(n)−x⋆‖2+Baφ(n)+1<η2+Baφ(n)+1 |
As φ(n)→∞,
| lim supn→∞‖X′n+1−x⋆‖2≤η2 |
Since η may be arbitrarily small, we conclude that
| lim supn→∞‖X′n+1−x⋆‖=limn→∞‖X′n+1−x⋆‖=0, |
completing the proof.
Recall from the introduction that our distribution of interest, μ, is posed on the Borel subsets of Hilbert space H. We assume that μ≪μ0, where μ0=N(m0,C0) is some reference Gaussian. Thus, we write
| dμdμ0=1Zμexp{−Φμ(u)}, | (3.1) |
where Φν:X→R, X a Banach space, a subspace of H, of full measure with respect to μ0, a Gaussian on H, assumed to be continuous. Zμ=Eμ0[exp{−Φ(u)}]∈(0,∞) is the partition function ensuring we have a probability measure.
Let ν=N(m,C), be another Gaussian, equivalent to μ0, such that we can write
| dνdμ0=1Zνexp{−Φν(v)}, | (3.2) |
Assuming that ν≪μ, we can write
| R(ν||μ)=Eν[Φμ(u)−Φν(u)]+log(Zμ)−log(Zν) | (3.3) |
The assumption that ν≪μ implies that ν and μ are equivalent measures. As was proven in [16], if A is a set of Gaussian measures, closed under weak convergence, such that at least one element of A is absolutely continuous with respect to μ, then any minimizing sequence over A will have a weak subsequential limit.
If we assume, for this work, that C=C0, then, by the Cameron-Martin formula (see [9]),
| Φν(u)=−⟨u−m,m−m0⟩H1−12‖m−m0‖2H1,Zν=1. | (3.4) |
Here, ⟨∙,∙⟩H1 and ‖∙‖H1 are the inner product and norms of the Cameron-Martin Hilbert space, denoted H1,
| ⟨f,g⟩H1=⟨C−1/20f,C−1/20g⟩,‖f‖2H1=⟨f,f⟩2H1. | (3.5) |
Convergence to the minimizer will be established in H1, and H1 will be the relevant Hilbert space in our application of Theorems 2.1 and 2.2 to this problem.
Letting ν0=N(0,C0) and v∼ν0, we can then rewrite (3.3) as
| J(m)≡R(ν||μ)=Eν0[Φμ(v+m)]+12‖m−m0‖2H1+log(Zμ) | (3.6) |
The Euler-Lagrange equation associated with (3.6), and the second variation, are:
| J′(m)=Eν0[Φ′μ(v+m)]+C−10(m−m0), | (3.7) |
| J″(m)=Eν0[Φ″μ(v+m)]+C−10. | (3.8) |
In [15], it was suggested that rather than try to find a root of (3.7), the equation first be preconditioned by multiplying by C0,
| C0Eν0[Φ′μ(v+m)]+(m−m0), | (3.9) |
and a root of this mapping is sought, instead. Defining
| f(m)=C0Eν0[Φ′μ(v+m)]+(m−m0), | (3.10) |
| F(m,v)=C0Φ′μ(v+m)+(m−m0). | (3.11) |
The Robbins-Monro formulation is then
| mn+1=mn−an+1F(mn,vn+1)+Pn+1, | (3.12) |
with vn∼ν0, i.i.d.
We thus have
Theorem 3.1. Assume:
● There exists ν=N(m,C0)∼μ0 such that ν≪μ.
● Φ′μ and Φ″μ exist for all u∈H1.
● There exists m⋆, a local minimizer of J, such that J′(m⋆)=0.
● The mapping
| m↦Eν0[‖√C0Φ′μ(m+v)‖2] | (3.13) |
is bounded on bounded subsets of H1.
● There exists a convex neighborhood U⋆ of m⋆ and a constant α>0, such that for all m∈U⋆, for all u∈H1,
| ⟨J″(m)u,u⟩≥α‖u‖2H1 | (3.14) |
Then, choosing an according to Assumption 4,
● If the subset U⋆ can be taken to be all of H1, for the expanding truncation algorithm, mn→m⋆ a.s. in H1.
● If the subset U⋆ is not all of H1, then, taking U1 to be a bounded (in H1) convex subset of U⋆, with m⋆∈U1, and U0 any subset of U1 such that there exist R0<R1 with
| U0⊂BR0(x⋆)⊂BR1(x⋆)⊂U1, |
for the fixed truncation algorithm, mn→m⋆ a.s. in H1.
Proof. We split the proof into 2 steps:
1. By the assumptions of the theorem, we clearly satisfy Assumptions 1 and 4. To satisfy Assumption 3, we observe that
| Eν0[‖F(m,v)‖2H1]≤2Eν0[‖√C0Φ′μ(m+v)‖2]+2‖m−m0‖2H1. |
This is bounded on bounded subsets of H1.
2. Per the convexity assumption, (3.14), implies Assumption 2, since, by the mean value theorem in function spaces,
| ⟨m−m⋆,f(m)⟩H1=⟨m−m⋆,C0[J′(m⋆)+J″(˜m)(m−m⋆)]⟩H1=⟨m−m⋆,J″(˜m)(m−m⋆)⟩≥α‖m−m⋆‖2H1 |
where ˜m is some intermediate point between m and m⋆. This completes the proof.
While condition (3.14) is sufficient to obtain convexity, other conditions are possible. For instance, suppose there is a convex open set U⋆ containing m⋆ and constant θ∈[0,1), such that for all m∈U⋆,
| infu∈Hu≠0⟨Eν0[Φ″μ(v+m)]u,u⟩‖u‖2≥−θλ−11, | (3.15) |
where λ1 is the principal eigenvalue of C0. Then this would also imply Assumption 2, since
| ⟨m−m⋆,f(m)⟩H1=⟨m−m⋆,C0[J′(m⋆)+J″(˜m)(m−m⋆)]⟩H1=⟨m−m⋆,J″(˜m)(m−m⋆)⟩≥‖m−m⋆‖2H1+⟨m−m⋆,Eν0[Φ″μ(v+˜m)](m−m⋆)⟩≥‖m−m⋆‖2H1−θλ−11‖m−m⋆‖2≥(1−θ)‖m−m⋆‖2H1. |
We mention (3.15) as there may be cases, shown below, for which the operator Eν0[Φ″μ(v+m)] is obviously nonnegative.
To apply the Robbins-Monro algorithm to the relative entropy minimization problem, the Φμ functional of interest must be examined. In this section we present a few examples, based on those presented in [15], and examine when the assumptions hold. The one outstanding assumption that we must make is that, a priori, μ0 is an equivalent measure to μ.
Taking μ0=N(0,1), the standard unit Gaussian, let V:R→R be a smooth function such that
| dμdμ0=1Zμexp{−ϵ−1V(x)} | (4.1) |
is a probability measure on R. For these scalar cases, we use x in place of v. In the above framework,
| F(x,ξ)=ϵ−1V′(x+ξ)−ξ,f(x)=ϵ−1E[V′(x+ξ)]mΦ′μ(x)=ϵ−1V′(x),Φ″μ(x)=ϵ−1V″(x) |
and ξ∼N(0,1)=ν0=μ0.
Consider the case that
| V(x)=12x2+14x4. | (4.2) |
In this case
| F(x,ξ)=ϵ−1(x+ξ+(x+ξ)3)+x,f(x)=ϵ−1(4x+x3)+x,E[Φ″μ(x+ξ)]=ϵ−1(4+3x2),E[|Φ′μ(x+ξ)|2]=ϵ−1(22+58x2+17x4+x6). |
Since E[Φ″μ(x+ξ)]≥4ϵ−1, all of our assumptions are satisfied and the expanding truncation algorithm will converge to the unique root at x⋆=0 a.s. See Figure 1 for an example of the convergence at ϵ=0.1, Un=(−n−1,n+1), and always restarting at 0.5.
We refer to this as a "globally convex'' problem since R is globally convex about the minimizer.
In contrast to the above problem, some mimizers are only "locally'' convex. Consider the case the double well potential
| V(x)=14(4−x2)2 | (4.3) |
Now, the expressions for RM are
| F(x,ξ)=ϵ−1((x+ξ)3−4(x+ξ)))+x,f(x)=ϵ−1(x3−x)+x,E[Φ″μ(x+ξ)]=ϵ−1(3x2−1),E[|Φ′μ(x+ξ)|2]=ϵ−1(1+x2)(7+6x2+x4). |
In this case, f(x) vanishes at 0 and ±√1−ϵ, and J″ changes sign from positive to negative when x enters (−√(1−ϵ)/3,√(1−ϵ)/3). We must therefore restrict to a fixed trust region if we want to ensure convergence to either of ±√1−ϵ.
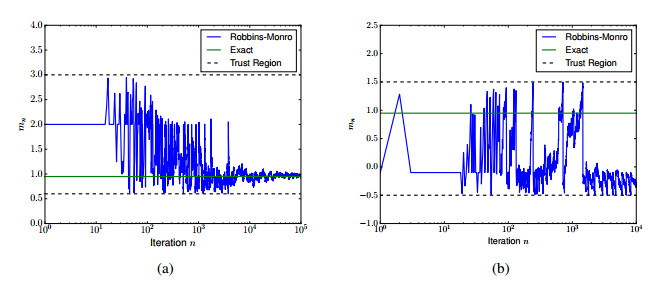
We ran the problem at ϵ=0.1 in two cases. In the first case, U1=(0.6,3.0) and the process always restarts at 2. This guarantees convergence since the second variation will be strictly postive. In the second case, U1=(−0.5,1.5), and the process always restarts at −0.1. Now, the second variation can change sign. The results of these two experiments appear in Figure 2. For some random number sequences the algorithm still converged to √1−ϵ, even with the poor choice of trust region.
Take μ0=N(m0(t),C0), with
| C0=(−d2dt2)−1, | (4.4) |
equipped with Dirichlet boundary conditions on H=L2(0,1).* In this case the Cameron-Martin space H1=H10(0,1), the standard Sobolev space equipped with the Dirichlet norm. Let us assume m0∈H1(0,1), taking values in Rd.
* This is the covariance of the standard unit Brownian bridge, Yt=Bt−tB1.
Consider the path space distribution on L2(0,1), induced by
| dμdμ0=−1Zμexp{−Φμ(v)},Φμ(u)=ϵ−1∫10V(v(t))dt, | (4.5) |
where V:Rd→R is a smooth function. We assume that V is such that this probability distribution exists and that μ∼μ0, our reference measure.
We thus seek an Rd valued function m(t)∈H1(0,1) for our Gaussian approximation of μ, satisfying the boundary conditions
| m(0)=m−,m(1)=m+. | (4.6) |
For simplicity, take m0=(1−t)m−+tm+, the linear interpolant between m±. As above, we work in the shifted coordinated x(t)=m(t)−m0(t)∈H10(0,1).
Given a path v(t)∈H10, by the Sobolev embedding, v is continuous with its L∞ norm controlled by its H1 norm. Also recall that for ξ∼N(0,C0), in the case of ξ(t)∈R,
| E[ξ(t)p]={0,p odd,(p−1)!![t(1−t)]p2,p even. | (4.7) |
Letting λ1=1/π2 be the ground state eigenvalue of C0,
| E[‖√C0Φ′μ(v+m0+ξ)‖2]≤λ1E[‖Φ′μ(v+m0+ξ)‖2]=λ1ϵ−2∫10E[|V′(v(t)+m0(t)+ξ(t))|2]dt. |
The terms involving v+m0 in the integrand can be controlled by the L∞ norm, which in turn is controlled by the H1 norm, while the terms involving ξ can be integrated according to (4.7). As a mapping applied to x, this expression is bounded on bounded subsets of H1.
Minimizers will satisfy the ODE
| ϵ−1E[V′(x+m0+ξ)]−x″=0,x(0)=x(1)=0. | (4.8) |
With regard to convexity about a minimizer, m⋆, if, for instance, V″ were pointwise positive definite, then the problem would satisfy (3.15), ensuring convergence. Consider the quartic potential V given by (4.2). In this case,
| Φ(v)=ϵ−1∫1012v(t)2+14v(t)4dt, | (4.9) |
and
| Φ′(v+m0+ξ)=ϵ−1[(v+m0+ξ)+3(v+m0+ξ)3]Φ″(v+m0+ξ)=ϵ−1[1+3(v+m0+ξ)2],E[Φ′(v+m0+ξ)]=ϵ−1[v+m0+(v+m0)3+3t(1−t)(v+m0)]E[Φ″(v+m0+ξ)]=ϵ−1[1+3(v+m0)2+3t(1−t)] |
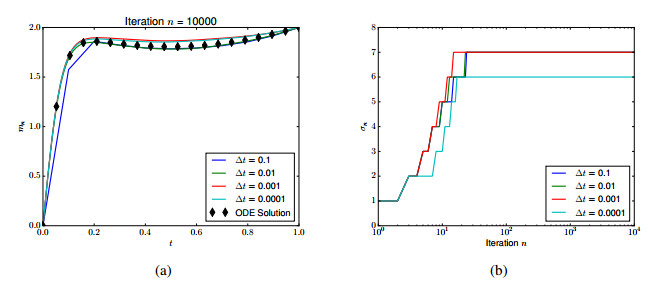
Since Φ″(v+m0+ξ)≥ϵ−1, we are guaranteed convergence using expanding trust regions. Taking ϵ=0.01, m−=0 and m+=2, this is illustrated in Figure 3, where we have also solved (4.8) by ODE methods for comparison. As trust regions, we take
| Un={m∈H10(0,1)∣‖x‖H1≤10+n}, | (4.10) |
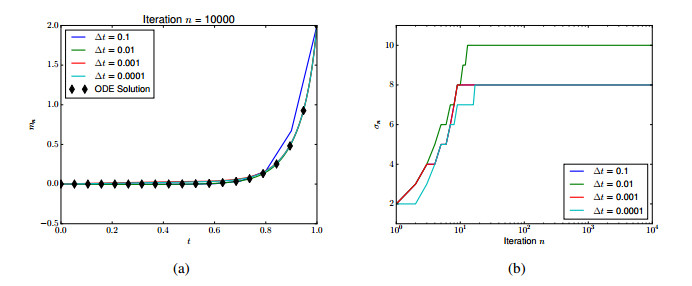
and we always restart at the zero solution Figure 3 also shows robustness to discretization; the number of truncations is relatively insensitive to Δt.
For many problems of interest, we do not have global convexity. Consider the double well potential (4.3), but in the case of paths,
| Φ(u)=ϵ−1∫1014(4−v(t)2)2dt. | (4.11) |
Then,
| Φ′(v+m0+ξ)=ϵ−1[(v+m0+ξ)3−4(v+m0+ξ)]Φ″(v+m0+ξ)=ϵ−1[3(v+m0+ξ)2−4],E[Φ′(v+m0+ξ)]=ϵ−1[(v+m0)3+3t(1−t)(v+m0)−4(v+m0)]E[Φ″(v+m0+ξ)]=ϵ−1[3(v+m0)2+3t(1−t)−4] |
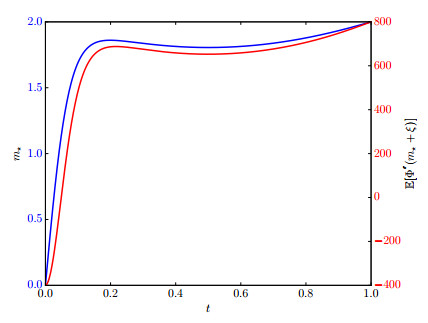
Here, we take m−=0, m+=2, and ϵ=0.01. We have plotted the numerically solved ODE in Figure 4. Also plotted is E[Φ″(v⋆+m0+ξ)]. Note that E[Φ″(v⋆+m0+ξ)] is not sign definite, becoming as small as −400. Since C0 has λ1=1/π2≈0.101, (3.15) cannot apply.
Discretizing the Schrödinger operator
| J″(v⋆)=−d2dt2+ϵ−1(3(v⋆(t)+m0(t))2+3t(1−t)−4), | (4.12) |
we numerically compute the eigenvalues. Plotted in Figure 5, we see that the minimal eigenvalue of J″(m⋆) is approximately μ1≈550. Therefore,
| ⟨J″(x⋆)u,u⟩≥μ1‖u‖2L2⇒⟨J″(x)u,u⟩≥α‖u‖2H1, | (4.13) |
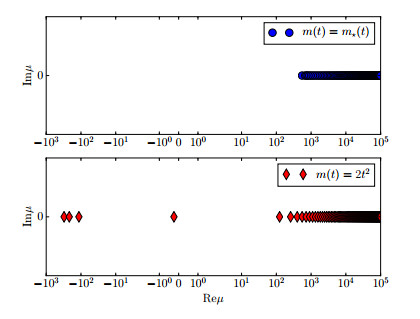
for all v in some neighborhood of v⋆. For an appropriately selected fixed trust region, the algorithm will converge.
However, we can show that the convexity condition is not global. Consider the path m(t)=2t2, which satisfies the boundary conditions. As shown in Figure 5, this path induces negative eigenvalues.
Despite this, we are still observe convergence. Using the fixed trust region
| U1={x∈H10(0,1)∣‖x‖H1≤100}, | (4.14) |
we obtain the results in Figure 6. Again, the convergence is robust to discretization.
We have shown that the Robbins-Monro algorithm, with both fixed and expanding trust regions, can be applied to Hilbert space valued problems, adapting the finite dimensional proof of [12]. We have also constructed sufficient conditions for which the relative entropy minimization problem fits within this framework.
One problem we did not address here was how to identify fixed trust regions. Indeed, that requires a tremendous amount of a priori information that is almost certainly not available. We interpret that result as a local convergence result that gives a theoretical basis for applying the algorithm. In practice, since the root is likely unknown, one might run some numerical experiments to identify a reasonable trust region, or just use expanding trust regions. The practitioner will find that the algorithm converges to a solution, though perhaps not the one originally envisioned. A more sophisticated analysis may address the convergence to a set of roots, while being agnostic as to which zero is found.
Another problem we did not address was how to optimize not just the mean, but also the covariance in the Gaussian. As discussed in [15], it is necessary to parameterize the covariance in some way, which will be application specific. Thus, while the form of the first variation of relative entropy with respect to the mean, (3.7), is quite generic, the corresponding expression for the covariance will be specific to the covariance parameterization. Additional constraints are also necessary to guarantee that the parameters always induce a covariance operator. We leave such specialization as future work.
This work was supported by US Department of Energy Award DE-SC0012733. This work was completed under US National Science Foundation Grant DMS-1818716. The authors would like to thank J. Lelong for helpful comments, along with anonymous reviewers whose reports significantly impacted our work.
The authors declare that there is no conflicts of interest in this paper.
| [1] | A. E. Albert and L. A. Gardner Jr., Stochastic approximation and nonlinear regression The MIT Press, 1967. |
| [2] |
C. Andrieu and É. Moulines, On the ergodicity properties of some adaptive MCMC algorithms Ann. Appl. Probab. 16 (2006), 1462-1505. doi: 10.1214/105051606000000286

|
| [3] |
C. Andrieu and J. Thoms, A tutorial on adaptive MCMC Stat. Comput. 18 (2008), 343-373. doi: 10.1007/s11222-008-9110-y
|
| [4] |
D. M. Blei, A. Kucukelbir and J. D. McAuliffe, Variational Inference: A Review for Statisticians J. Am. Stat. Assoc. 112 (2017), 859-877. doi: 10.1080/01621459.2017.1285773
|
| [5] |
J. R. Blum, Approximation methods which converge with probability one Annals of Mathematical Statistics 25 (1954), 382-386. doi: 10.1214/aoms/1177728794
|
| [6] |
J. R. Blum, Multidimensional stochastic approximation methods Annals of Mathematical Statistics 25 (1954), 737-744. doi: 10.1214/aoms/1177728659
|
| [7] |
S. D. Chatterji, Martingale convergence and the Radon-Nikodym theorem in Banach spaces Math. Scand. 22 (1968), 21-41. doi: 10.7146/math.scand.a-10868
|
| [8] | H.-F. Chen, Stochastic approximation and its applications 2002. |
| [9] | G. Da Prato, An Introduction to Infinite-Dimensional Analsysis Springer, 2006. |
| [10] |
H. Haario, E. Saksman and J. Tamminen, An adaptive Metropolis algorithm Bernoulli 7 (2001), 223-242. doi: 10.2307/3318737
|
| [11] | H. J. Kushner and G. Yin, Stochastic Approximation and Recursive Algorithms and Applications Springer, 2003. |
| [12] |
J. Lelong, Almost sure convergence of randomly truncated stochastic algorithms under verifiable conditions Stat. Probabil. Lett. 78 (2008), 2632-2636. doi: 10.1016/j.spl.2008.02.034
|
| [13] |
Y. Lu, A. Stuart and H. Weber, Gaussian approximations for probability measures on r^d SIAM/ASA Journal on Uncertainty Quantification 5 (2017), 1136-1165. doi: 10.1137/16m1105384
|
| [14] |
Y. Lu, A. Stuart and H. Weber, Gaussian approximations for transition paths in brownian dynamics SIAM J. Math. Anal. 49 (2017), 3005-3047. doi: 10.1137/16m1071845
|
| [15] |
F. J. Pinski, G Simpson, A. M. Stuart, et al. Algorithms for Kullback-Leibler Approximation of Probability Measures in Infinite Dimensions SIAM J. Sci. Comput. 37 (2015), A2733-A2757. doi: 10.1137/14098171x
|
| [16] |
F. J. Pinski, G Simpson, A. M. Stuart, et al. Kullback-Leibler Approximation for Probability Measures on Infinite Dimensional Spaces SIAM J. Math. Anal. 47 (2015), 4091-4122. doi: 10.1137/140962802
|
| [17] | H. Robbins and S. Monro, A stochastic approximation method The Annals of Mathematical Statistics (1950), 400-407. |
| [18] |
G. O. Roberts and J. S. Rosenthal, Coupling and Ergodicity of Adaptive Markov Chain Monte Carlo Algorithms J. Appl. Probab. 44 (2007), 458-475. doi: 10.1017/s0021900200003090
|
| [19] |
D. Sanz-Alonso and A. M. Stuart, Gaussian approximations of small noise diffusions in kullback-leibler divergence Commun. Math. Sci. 15 (2017), 2087-2097. doi: 10.4310/cms.2017.v15.n7.a13
|
| [20] |
G. Yin and Y. M. Zhu, On H-valued Robbins-Monro processes J. Multivariate Anal. 34 (1990), 116-140. doi: 10.1016/0047-259x(90)90064-o
|
Figures(6)

Gideon Simpson, Daniel Watkins. Relative entropy minimization over Hilbert spaces via Robbins-Monro[J]. AIMS Mathematics, 2019, 4(3): 359-383. doi: 10.3934/math.2019.3.359

 DownLoad:
DownLoad:
